【练拳不练功,到老一场空】深入浅出计算机组成原理
深入浅出计算机组成原理
文章目录
- 深入浅出计算机组成原理
-
- 计算机的基本组成
-
- 硬件设备组成
-
- CPU
- 内存
- 主板
- I/O 设备
- 硬盘
- 显卡
- 冯.诺依曼体系结构
-
- 运算器/处理器单元
- 控制器
- 存储器
- 输入设备
- 输出设备
- 举个栗子:
- 计算机的性能与功耗
-
- 响应时间
- 吞吐率
- CPU时钟/主频
- 计算机的功耗
- 计算机的指令和运算
-
- 计算机指令(机器码)
-
- 计算机指令和指令集
- 机器码
- CPU是如何执行指令的?
- 程序栈
- 程序执行
-
- 静态链接和ELF格式
- 程序的装载(内存的优化)
- 动态链接
- 计算机运算(二进制)
-
- 字符串是如何转为二进制的?
- 数字电路
- 浮点数和定点数(0.3+0.6==0.9为啥为false)
- 深入理解浮点数到底怎么用
- 计算机处理器
-
- CPU
- GPU
- GPU与CPU有什么区别
- 存储器和I/O系统
-
- 存储器的层次结构
-
- SRAM
- DRAM
- 存储器的层次结构
- 局部性原理
-
- 时间局部性
- 空间局部性
- 举个栗子:
- CPU Cache
-
- 引入
- 高速缓存
- Cache 的数据结构和读取过程
- Cache 的写入
-
- 写直达(Write-Through)
- 写回(Write-Back)
- 缓存一致性问题
- 总线嗅探机制和MESI协议
- 理解内存
-
- 虚拟内存和内存保护
-
- 简单页表
- 多级页表
- TLB和内存保护
- 总线:计算机内部的高速公路
-
- Bus,设计概念
- 总线类型
- 输入输出设备I/O
-
- IO的构成
- CPU是如何控制IO的
- 信号和地址
- 磁盘IO的性能
- 硬盘
-
- 机械硬盘(HDD)
- 固态硬盘(SSD)
- 为什么SSD硬盘不建议使用碎片整理
- 磨损均衡(FTL)、TRIM 和写入放大效应
- DMA
-
- 理解DMA,一个协处理器
- 开发中的问题
-
- 为什么Kafka这么快?
练拳不练功,到老一场空
本文是:深入浅出计算机组成原理 (geekbang.org) 学习笔记。有些概念如果不容易理解可以去B站抖音等搜索相关视频,B站推荐:硬件茶谈
如果越早去弄清楚计算机的底层原理,在你的知识体系中“储蓄”起这些知识,也就意味着你有越长的时间来收获学习知识的“利息”。虽然一开始可能不起眼,但是随着时间带来的复利效应,你的长线投资项目,就能让你在成长的过程中越走越快。
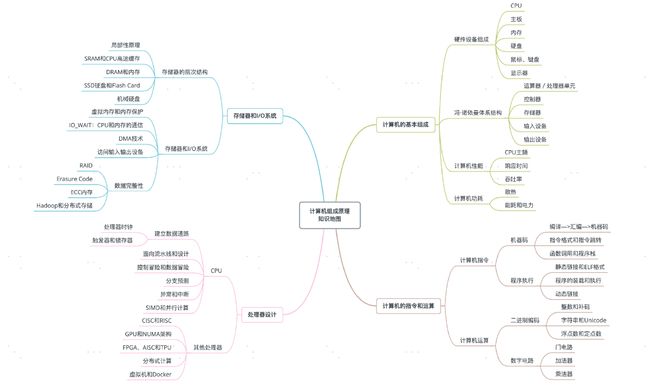
计算机的基本组成
硬件设备组成
**假如我们要自己组装一台计算机。**首先我们要有三大件:CPU、内存、主板
CPU
CPU,全名中央处理器(Central Processing Unit),计算机的所有“计算 ”都是由CPU来进行的。

内存
你撰写的程序、打开的浏览器、运行的游戏,都要加载到内存里才能运行。程序读取的数据、计算得到的结果,也都要放在内存里。内存越大,能加载的东西自然也就越多。

主板
存放在内存里的程序和数据,需要被 CPU 读取,CPU 计算完之后,还要把数据写回到内存。然而 CPU 不能直接插到内存上,反之亦然。
主板是一个有着各种各样,有时候多达数十乃至上百个插槽的配件。我们的 CPU 要插在主板上,内存也要插在主板上。主板的芯片组(Chipset)和总线(Bus)解决了 CPU 和内存之间如何通信的问题。芯片组控制了数据传输的流转,也就是数据从哪里到哪里的问题。总线则是实际数据传输的高速公路。因此,总线速度(Bus Speed)决定了数据能传输得多快。

I/O 设备
输入设备: 显示器…
输入设备: 鼠标、键盘…
鼠标、键盘以及硬盘,这些都是插在主板上的。作为外部 I/O 设备,它们是通过主板上的南桥(SouthBridge)芯片组,来控制和 CPU 之间的通信的。“南桥”芯片的名字很直观,一方面,它在主板上的位置,通常在主板的“南面”。另一方面,它的作用就是作为“桥”,来连接鼠标、键盘以及硬盘这些外部设备和 CPU 之间的通信。
硬盘
有了硬盘,这样各种数据才能持久地保存下来。
如果你去过网吧,那么你会发现,很多网吧的计算机没有硬盘,而是直接通过局域网,读写远程网络硬盘里的数据,类似于我们日常使用的云服务器。
显卡
现在,使用图形界面操作系统的计算机,无论是 Windows、Mac OS 还是 Linux,显卡都是必不可少的。有人可能要说了,我装机的时候没有买显卡,计算机一样可以正常跑起来啊!那是因为,现在的主板都带了内置的显卡。如果你用计算机玩游戏,做图形渲染或者跑深度学习应用,你多半就需要买一张单独的显卡,插在主板上。显卡之所以特殊,是因为显卡里有除了 CPU 之外的另一个“处理器”,也就是GPU(Graphics Processing Unit,图形处理器),GPU 一样可以做各种“计算”的工作。

冯.诺依曼体系结构
智能手机和电脑的硬件组成方式不太一样,但是我们写智能手机上的
App,和写个人电脑的客户端应用似乎没有什么差别,都是通过“高级语言”这样的编程语言撰写、编译之后,一样是把代码和数据加载到内存里来执行。这是为什么呢?因为,无论是个人电脑、服务器、智能手机,还是 Raspberry Pi 这样的微型卡片机,都遵循着同一个“计算机”的抽象概念。
计算机祖师爷之一 冯·诺依曼(John von Neumann)提出的冯·诺依曼体系结构(Von Neumannarchitecture),也叫存储程序计算机。
**什么是存储程序计算机呢?**这里面其实暗含了两个概念,一个是“可编程”计算机,一个是“存储”计算机。
计算机是由各种
门电路组合而成的,然后通过组装出一个固定的电路版,来完成一个特定的计算程序。一旦需要修改功能,就要重新组装电路。这样的话,计算机就是**“不可编程”的,因为程序在计算机硬件层面是“写死”的。最常见的就是老式计算器**,电路板设好了加减乘除,做不了任何计算逻辑固定之外的事情。
冯诺伊曼体系结构:

运算器/处理器单元
完成各种算术、逻辑运算和数据传输等数据加工处理
- 算数运算:加、减、乘、除法等
- 逻辑运算:与、或、非、移位等
- 基本结构
- ALU(Arithmetic Logical Unit):算术逻辑运算单元
- 寄存器
- 连接通路
控制器
控制程序的执行
- 产生指令执行过程所需要的所有控制信号,控制相关功能部件执行相应操作
- 控制信号的形式
- 电平信号
- 脉冲信号
- 产生控制信号的依据
- 指令
- 状态
- 时序
- 控制信号的产生方式
- 微程序
存储器
记住程序和数据
- 功能
- 存储原程序、原数据、运算中间结果
- 工作方式
- 读/写
- 工作原理
- 按地址访问,读/写数据
输入设备
把程序和数据加载到计算机
- 输入设备
- 向计算机输入数据(键盘、鼠标、网卡、扫描仪等)
输出设备
按照要求将处理的数据结果显示给用户
- 输出设备
- 输出处理结果(显示器、声卡、网卡、打印机等)
举个栗子:
你在qq 上发送了一句 “ 在吗 ” 给朋友,数据的流动过程 :

你在qq上发了一个文件给朋友:

计算机的性能与功耗
计算机的性能,其实和我们干体力劳动很像,好比是我们要搬东西。对于计算机的性能,我们需要有个标准来衡量。这个标准中主要有两个指标。
响应时间
响应时间(Response time)或者叫执行时间(Execution time)。想要提升响应时间这个性能指标,你可以理解为让计算机“跑得更快”。
吞吐率
吞吐率(Throughput)或者带宽(Bandwidth),想要提升这个指标,你可以理解为让计算机“搬得更多”。

CPU时钟/主频
计算机可能同时运行着好多个程序,CPU 实际上不停地在各个程序之间进行切换。在这些走掉的时间里面,很可能 CPU 切换去运行别的程序了。而且,有些程序在运行的时候,可能要从网络、硬盘去读取数据,要等网络和硬盘把数据读出来,给到内存和 CPU。
所以说,要想准确统计某个程序运行时间,进而去比较两个程序的实际性能,我们得把这些时间给刨除掉。那这件事怎么实现呢?Linux 下有一个叫 time 的命令,可以帮我们统计出来,同样的 WallClock Time 下,程序实际在 CPU 上到底花了多少时间。

程序实际花费的 CPU 执行时间(CPUTime),就是 user time 加上 sys time。
除了 CPU 之外,时间这个性能指标还会受到主板、内存这些其他相关硬件的影响。所以,我们需要对“时间”这个我们可以感知的指标进行拆解,把程序的 CPU 执行时间变成 CPU时钟周期数(CPU Cycles)和 时钟周期时间(Clock Cycle)的乘积。
程序的 CPU 执行时间 =CPU 时钟周期数×时钟周期时间
我们先来理解一下什么是时钟周期时间。你在买电脑的时候,一定关注过 CPU 的主频。例如Intel Core-i7-7700HQ 2.8GHz,这里的 2.8GHz 就是电脑的主频(Frequency/Clock Rate)。这个 2.8GHz,我们可以先粗浅地认为,CPU 在 1 秒时间内,可以执行的简单指令的数量是 2.8G 条。
2.8GHz详解:
这个 2.8GHz 就代表,我们 CPU 的一个“钟表”能够识别出来的最小的时间间隔。就像我们挂在墙上的挂钟,都是“滴答滴答”一秒一秒地走,所以通过墙上的挂钟能够识别出来的最小时间单位就是秒。
而在 CPU 内部,和我们平时戴的电子石英表类似,有一个叫晶体振荡器(OscillatorCrystal)的东西,简称为晶振。我们把晶振当成 CPU 内部的电子表来使用。晶振带来的每一次“滴答”,就是时钟周期时间。在我这个 2.8GHz 的 CPU 上,这个时钟周期时间,就是 1/2.8G。
我们的 CPU,是按照这个“时钟”提示的时间来进行自己的操作。主频越高,意味着这个表走得越快,我们的CPU 也就“被逼”着走得越快。如果你自己组装过台式机的话,可能听说过“**超频”**这个概念,这说的其实就相当于把买回来的 CPU 内部的钟给调快了,于是 CPU 的计算跟着这个时钟的节奏,也就自然变快了。当然这个快不是没有代价的,CPU 跑得越快,散热的压力也就越大。就和人一样,超过生理极限,CPU 就会崩溃了。
对于软件工程师来说,如何提升性能呢?
- 换CPU
- 减少程序需要的CPU时钟周期数量
对于 CPU 时钟周期数,我们可以再做一个分解,把它变成“指令数×每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)
程序的 CPU 执行时间 = (指令数×CPI)× 时钟周期时间
我们可以把自己想象成一个 CPU,坐在那里写程序。
- 计算机主频就好像是你的打字速度,打字越快,你自然可以多写一点程序。
- CPI 相当于你在写程序的时候,熟悉各种快捷键,越是打同样的内容,需要敲击键盘的次数就越少。
- 指令数相当于你的程序设计得够合理,同样的程序要写的代码行数就少。
如果三者皆能实现,你自然可以很快地写出一个优秀的程序,你的“性能”从外面来看就是好的。
计算机的功耗
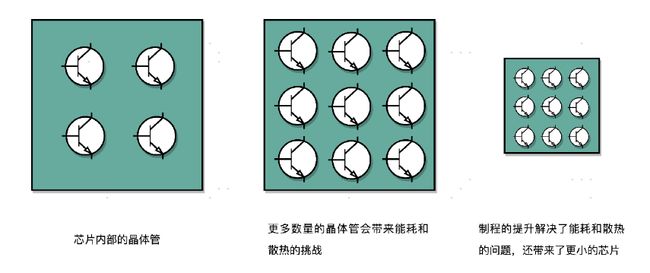
我们的 CPU,一般都被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI)。这些电路,实际上都是一个个晶体管组合而成的。CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。
想要计算得快,一方面,我们要在 CPU 里,同样的面积里面,多放一些晶体管,也就是增加密度;另一方面,我们要让晶体管“打开”和“关闭”得更快一点,也就是提升主频。而这两者,都会增加功耗,带来耗电和散热的问题。
我们会在 CPU 上面抹硅脂、装风扇,乃至用上水冷或者其他更好的散热设备,就好像在工厂里面装风扇、空调,发冷饮一样。但是同样的空间下,装上风扇空调能够带来的散热效果也是有极限的。
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
那么,为了要提升性能,我们需要不断地增加晶体管数量。同样的面积下,我们想要多放一点晶体管,就要把晶体管造得小一点。这个就是平时我们所说的提升**“制程”**。从 28nm到 7nm,相当于晶体管本身变成了原来的 1/4 大小。这个就相当于我们在工厂里,同样的活儿,我们要找瘦小一点的工人,这样一个工厂里面就可以多一些人。我们还要提升主频,让开关的频率变快,也就是要找手脚更快的工人。
我们可以看到,无论是简单地通过提升主频,还是增加更多的 CPU 核心数量,通过并行来提升性能,都会遇到相应的瓶颈。仅仅简单地通过“堆硬件”的方式,在今天已经不能很好地满足我们对于程序性能的期望了。
在整个计算机组成层面,还有这样几个原则性的性能提升方法:
- 加速大概率事件,例如GPU来处理向量和矩阵计算。
- 通过流水线提高性能
- 通过预测提高性能
计算机的指令和运算
计算机中的基本单位:计算机存储单位一般用 bit, Byte, KB, MB, GB, TB, PB, EB, ZB, BB来表示;
1、计算机存储信息的最小单位:
- 位 bit (比特)(Binary Digits):存放一位二进制数,即 0 或 1,最小的存储单位。
2、计算机存储容量基本单位是字节
- 字节 byte:8个二进制位(bit)为一个字节(B),最常用的单位。
1B(Byte 字节)=8bit,
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB (Trillionbyte 万亿字节 太字节)=1024GB,其中1024=2^10 ( 2 的10次方),
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB.
计算机指令(机器码)
计算机指令和指令集
在编程的最初期,工程师们使用打孔卡来写程序,因为计算机或者说 CPU 本身,并没有能力理解这些高级语言。即使在 2019 年的今天,我们使用的现代个人计算机,仍然只能处理所谓的“机器码”,也就是一连串的“0”和“1”这样的数字。那么,我们每天用高级语言的程序,最终是怎么变成一串串“0”和“1”的?这一串串“0”和“1”又是怎么在 CPU 中处理的?

在软硬接口中,CPU帮我们做了什么事?
- 从硬件的角度来看,CPU 就是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑。
- 如果我们从软件工程师的角度来讲,CPU 就是一个执行各种计算机指令(InstructionCode)的逻辑机器。这里的计算机指令,就好比一门 CPU 能够听得懂的语言,我们也可以把它叫作机器语言(Machine Language)。
不同的 CPU 能够听懂的语言不太一样。比如,我们的个人电脑用的是 Intel 的 CPU,苹果手机用的是 ARM 的 CPU。这两者能听懂的语言就不太一样。类似这样两种 CPU 各自支持的语言,就是两组不同的计算机指令集,英文叫 Instruction Set。这里面的“Set”,其实就是数学上的集合,代表不同的单词、语法。
所以,如果我们在自己电脑上写一个程序,然后把这个程序复制一下,装到自己的手机上,肯定是没办法正常运行的,因为这两者语言不通。而一台电脑上的程序,简单复制一下到另外一台电脑上,通常就能正常运行,因为这两台 CPU 有着相同的指令集,也就是说,它们的语言相通的。
一个计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。但是 CPU 里不能一直放着所有指令,所以计算机程序平时是存储在存储器中的。这种程序指令存储在存储器里面的计算机,我们就叫作存储程序型计算机(Stored-program Computer)。
机器码
编译->汇编,代码如何变成机器码?
了解了计算机指令和计算机指令集,接下来我们来看看,平时编写的代码,到底是怎么变成一条条计算机指令,最后被 CPU 执行的呢?
int main()
{
int a = 1;
int b = 2;
a = a + b;
}
要让这段C语言程序在一个 Linux 操作系统上跑起来,我们需要把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序,这个过程我们一般叫编译(Compile)成汇编代码。
针对汇编代码,我们可以再用汇编器(Assembler)翻译成机器码(Machine Code)。这些机器码由“0”和“1”组成的机器语言表示。这一条条机器码,就是一条条的计算机指令。这样一串串的 16 进制数字,就是我们 CPU 能够真正认识的计算机指令。
在一个 Linux 操作系统上,我们可以简单地使用 gcc 和 objdump 这样两条命令,把对应的汇编代码和机器码都打印出来。
[root@iZ2ze9ql6wc4u0l1j4f6uiZ ~]# gcc -g -c test.c
[root@iZ2ze9ql6wc4u0l1j4f6uiZ ~]# ls
get-docker.sh install.sh jstack.log test.c test.o
[root@iZ2ze9ql6wc4u0l1j4f6uiZ ~]# objdump -d -M intel -S test.o
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
#include可以看到,左侧有一堆数字,这些就是一条条机器码;右边有一系列的 push、mov、add、pop 等,这些就是对应的汇编代码。一行 C 语言代码,有时候只对应一条机器码和汇编代码,有时候则是对应两条机器码和汇编代码。
这个时候你可能又要问了,我们实际在用 GCC(GUC 编译器套装,GUI CompilerCollectipon)编译器的时候,可以直接把代码编译成机器码呀,为什么还需要汇编代码呢?原因很简单,你看着那一串数字表示的机器码,是不是摸不着头脑?但是即使你没有学过汇编代码,看的时候多少也能“猜”出一些这些代码的含义。
汇编代码其实就是“给程序员看的机器码”
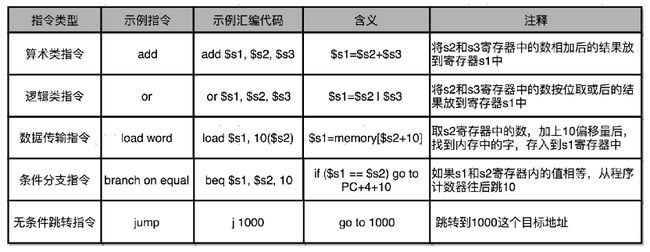
汇编器是怎么吧对应的汇编代码,翻译成为机器码的?——MIPS指令集
CPU是如何执行指令的?
拿我们用的 Intel CPU 来说,里面差不多有几百亿个晶体管。实际上,一条条计算机指令执行起来非常复杂。好在 CPU 在软件层面已经为我们做好了封装。对于我们这些做软件的程序员来说,我们只要知道,写好的代码变成了指令之后,是一条一条顺序执行的就可以了。
逻辑上,我们可以认为,CPU 其实就是由一堆寄存器组成的。而寄存器就是 CPU 内部,由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单电路。
N 个触发器或者锁存器,就可以组成一个 N 位(Bit)的寄存器,能够保存 N 位的数据。比方说,我们用的 64 位 Intel 服务器,寄存器就是 64 位的。
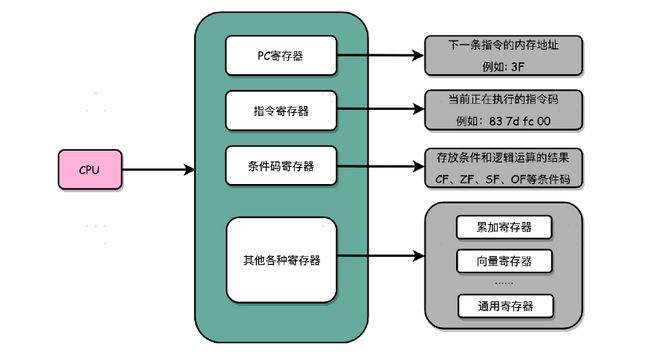
除了这些特殊的寄存器,CPU 里面还有更多用来存储数据和内存地址的寄存器。这样的寄存器通常一类里面不止一个。我们通常根据存放的数据内容来给它们取名字,比如整数寄存器、浮点数寄存器、向量寄存器和地址寄存器等等。有些寄存器既可以存放数据,又能存放地址,我们就叫它通用寄存器。
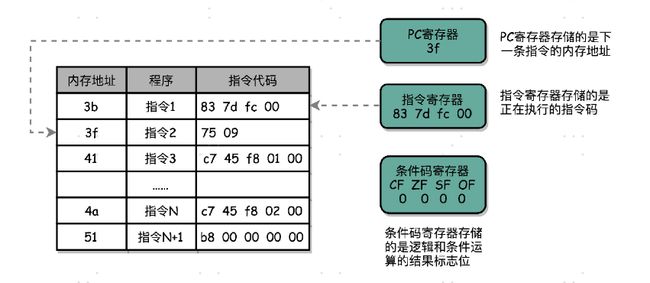
实际上,一个程序执行的时候,CPU 会根据 PC 寄存器里的地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。可以看到,一个程序的一条条指令,在内存里面是连续保存的,也会一条条顺序加载。
程序栈
我们在内存里面开辟一段空间,用栈这个后进先出(LIFO,Last In First Out)的数据结构。作为程序栈,我们可以方便地通过压栈和出栈操作,使得程序在不同的函数调用过程中进行转移。
结合之前的机器码和汇编码来看:
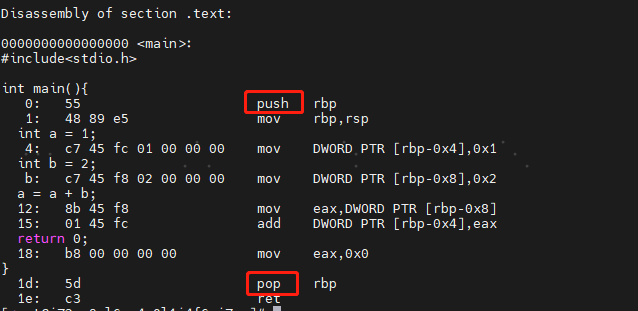
Push 即为入栈, pop即为出栈。
程序执行
静态链接和ELF格式
为什么同样一个程序,在 Linux 下可以执行而在 Windows下不能执行了。其中一个非常重要的原因就是,两个操作系统下可执行文件的格式不一样。
- Linux 下的 ELF 文件格式
- 而Windows 的可执行文件格式是一种叫作PE(Portable Executable Format)的文件格式。
- Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。

Linux 下著名的开源项目 Wine,就是通过兼容PE 格式的装载器,使得我们能直接在 Linux 下运行 Windows 程序的。而现在微软的
Windows 里面也提供了 WSL,也就是 Windows Subsystem for Linux,可以解析和加载ELF 格式的文件。
我们去写可以用的程序,也不仅仅是把所有代码放在一个文件里来编译执行,而是可以拆分成不同的函数库,最后通过一个静态链接的机制,使得不同的文件之间既有分工,又能通过静态链接来“合作”(通过链接器,把多个文件合并成一个最终可执行文件),变成一个可执行的程序。
程序的装载(内存的优化)
我们看到了如何通过链接器,把多个文件合并成一个最终可执行文件。在运行这些可执行文件的时候,我们其实是通过一个装载器,解析 ELF 或者 PE 格式的可执行文件。装载器会把对应的指令和数据加载到内存里面来,让 CPU 去执行。
装载器需要满足两个要求:
- 可执行程序加载后占用的内存空间应该是连续的。
- 我们需要同时加载很多个程序,并且不能让程序自己规定正在内存中加载的位置。
我们可以在内存里面,找到一段连续的内存空间,然后分配给装载的程序,然后把这段连续的内存空间地址,和整个程序指令里指定的内存地址做一个映射。–(分段)
- 我们把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address)
- 实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。
我们只需要关心虚拟内存地址就行了,对于任何一个程序来说,它看到的都是同样的内存地址。我们维护一个虚拟内存到物理内存的映射表,这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。因为是连续的内存地址空间,所以我们只需要维护映射关系的起始地址和对应的空间大小就可以了。
内存分段:
这种找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。这里的段,就是指系统分配出来的那个连续的内存空间。
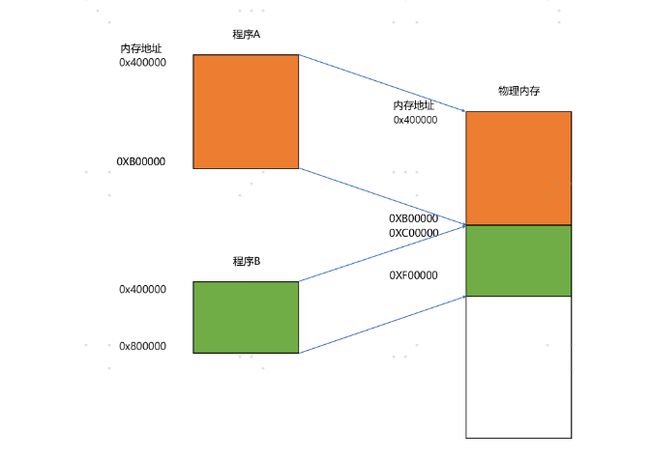
分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但它也有一些不足之处,第一个就是内存碎片(Memory Fragmentation)的问题。
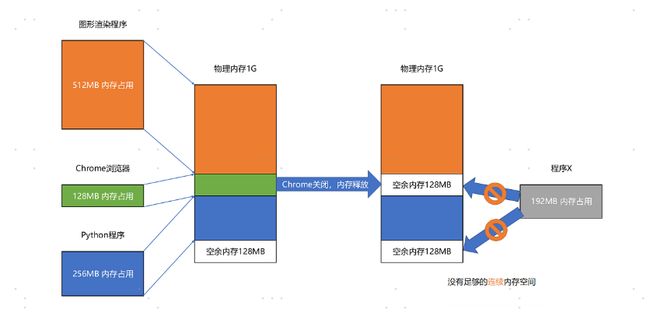
内存交换就是解决内存分段的问题。
我们可以把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。不过读回来的时候,我们不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的 512MB 内存后面。这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。
如果你自己安装过 Linux 操作系统,你应该遇到过分配一个 swap 硬盘分区的问题。这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。
内存分页
虚拟内存、分段,再加上内存交换,看起来似乎已经解决了计算机同时装载运行很多个程序的问题。不过,你千万不要大意,这三者的组合仍然会遇到一个性能瓶颈。硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
既然问题出在内存碎片和内存交换的空间太大上,那么解决问题的办法就是,少出现一些内存碎片。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决这个问题。这个办法,在现在计算机的内存管理里面,就叫作内存分页(Paging)。
和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下,我们通常只设置成 4KB。

由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。
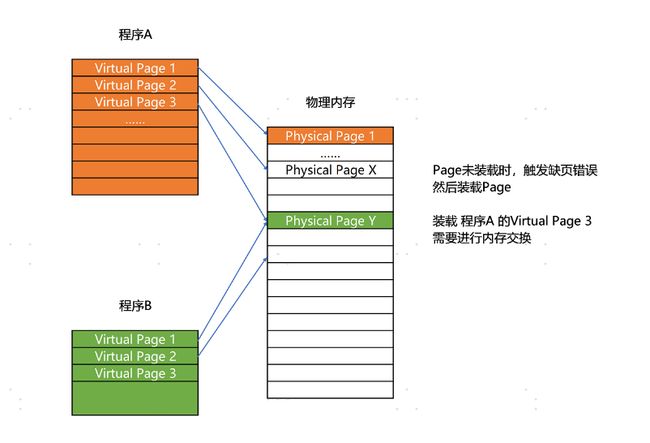
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
实际上,我们的操作系统,的确是这么做的。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
总结:任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。
动态链接
我们之前讲过,程序的链接,是把对应的不同文件内的代码段,合并到一起,成为最后的可执行文件。这个链接的方式,让我们在写代码的时候做到了“复用”。同样的功能代码只要写一次,然后提供给很多不同的程序进行链接就行了。这么说来,“链接”其实有点儿像我们日常生活中的标准化、模块化生产。我们有一个可以生产标准螺帽的生产线,就可以生产很多个不同的螺帽。只要需要螺帽,我们都可以通过链接的方式,去复制一个出来,放到需要的地方去,大到汽车,小到信箱。
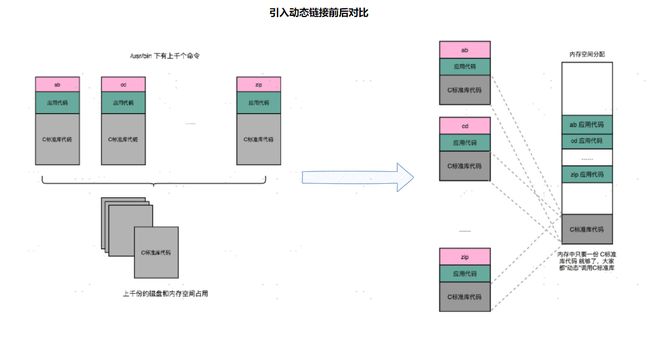
但是,如果我们有很多个程序都要通过装载器装载到内存里面,那里面链接好的同样的功能代码,也都需要再装载一遍,再占一遍内存空间。这就好比,假设每个人都有骑自行车的需要,那我们给每个人都生产一辆自行车带在身边,固然大家都有自行车用了,但是马路上肯定会特别拥挤。 我们上一节解决程序装载到内存的时候,讲了很多方法。说起来,最根本的问题其实就是内存空间不够用。如果我们能够让同样功能的代码,在不同的程序里面,不需要各占一份内存空间,那该有多好啊!这个思路就引入一种新的链接方法,叫作动态链接(Dynamic Link)。
在动态链接的过程中,我们想要“链接”的,不是存储在硬盘上的目标文件代码,而是加载到内存中的共享库(Shared Libraries)。
这个加载到内存中的共享库会被很多个程序的指令调用到。在 Windows 下,这些共享库文件就是.dll 文件,也就是 Dynamic-Link Libary(DLL,动态链接库)。在 Linux 下,这些共享库文件就是.so 文件,也就是 Shared Object(一般我们也称之为动态链接库)。这两大操作系统下的文件名后缀,一个用了“动态链接”的意思,另一个用了“共享”的意思,正好覆盖了两方面的含义。
要想要在程序运行的时候共享代码,也有一定的要求,就是这些机器码必须是“地址无关”的。
大部分函数库其实都可以做到地址无关,因为它们都接受特定的输入,进行确定的操作,然后给出返回结果就好了。无论是实现一个向量加法,还是实现一个打印的函数,这些代码逻辑和输入的数据在内存里面的位置并不重要。
而常见的地址相关的代码,比如绝对地址代码(Absolute Code)、利用重定位表的代码等等,都是地址相关的代码。在程序链接的时候,我们就把函数调用后要跳转访问的地址确定下来了,这意味着,如果这个函数加载到一个不同的内存地址,跳转就会失败。
对于所有动态链接共享库的程序来讲,虽然我们的共享库用的都是同一段物理内存地址,但是在不同的应用程序里,它所在的虚拟内存地址是不同的。 —— PLT 和 GOT,动态链接的解决方案。
实际上,在进行 Linux 下的程序开发的时候,我们一直会用到各种各样的动态链接库。C语言的标准库就在 1MB 以上。我们撰写任何一个程序可能都需要用到这个库,常见的Linux 服务器里,/usr/bin 下面就有上千个可执行文件。如果每一个都把标准库静态链接进来的,几 GB 乃至几十 GB 的磁盘空间一下子就用出去了。如果我们服务端的多进程应用要开上千个进程,几 GB 的内存空间也会一下子就用出去了。这个问题在过去计算机的内存较少的时候更加显著。
通过动态链接这个方式,可以说彻底解决了这个问题。就像共享单车一样,如果仔细经营,是一个很有社会价值的事情,但是如果粗暴地把它变成无限制地复制生产,给每个人造一辆,只会在系统内制造大量无用的垃圾。
计算机运算(二进制)
上算法和数据结构课的时候,老师们都会和你说,程序 = 算法 + 数据结构。如果对应到组成原理或者说硬件层面,算法就是我们前面讲的各种计算机指令,数据结构就对应我们接下来要讲的二进制数据。众所周知,现代计算机都是用 0 和 1 组成的二进制,来表示所有的信息。前面几讲的程序指令用到的机器码,也是使用二进制表示的;我们存储在内存里面的字符串、整数、浮点数也都是用二进制表示的。万事万物在计算机里都是 0 和 1,所以呢,搞清楚各种数据在二进制层面是怎么表示的,是我们必备的一课。
对于基础类型的转换(十进制 —>二进制),以及原码、补码,相信大家都不陌生,所以此处重点讲解字符串编码。
字符串是如何转为二进制的?
最早计算机只需要使用英文字符,加上数字和一些特殊符号,然后用 8 位的二进制,就能表示我们日常需要的所有字符了,这个就是我们常常说的ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码)。

ASCII 码就好比一个字典,用 8 位二进制中的 128 个不同的数,映射到 128 个不同的字符里。比如,小写字母 a 在 ASCII 里面,就是第 97 个,也就是二进制的 0110 0001,对应的十六进制表示就是 61。而大写字母 A,就是第 65 个,也就是二进制的 0100 0001,对应的十六进制表示就是 41。在 ASCII 码里面,数字 9 不再像整数表示法里一样,用 0000 1001 来表示,而是用 00111001 来表示。字符串 15 也不是用 0000 1111 这 8 位来表示,而是变成两个字符 1 和 5连续放在一起,也就是 0011 0001 和 0011 0101,需要用两个 8 位来表示。
我们可以看到,最大的 32 位整数,就是 2147483647。如果用整数表示法,只需要 32 位就能表示了。但是如果用字符串来表示,一共有 10 个字符,每个字符用 8 位的话,需要整整 80 位。比起整数表示法,要多占很多空间。
这也是为什么,很多时候我们在存储数据的时候,要采用二进制序列化这样的方式,而不是简单地把数据通过 CSV 或者 JSON,这样的文本格式存储来进行序列化。不管是整数也好,浮点数也好,采用二进制序列化会比存储文本省下不少空间。
字符集、字符编码
ASCII 码只表示了 128 个字符,一开始倒也堪用,毕竟计算机是在美国发明的。然而随着越来越多的不同国家的人都用上了计算机,想要表示譬如中文这样的文字,128 个字符显然是不太够用的。于是,计算机工程师们开始各显神通,给自己国家的语言创建了对应的字符集(Charset)和字符编码(Character Encoding)。
- **字符集:**表示的可以是字符的一个集合,“第一版《新华字典》里面出现的所有汉字”,这是一个字符集。(一个字符在不在这个集合里面。比如,我们日常说的 Unicode,其实就是一个字符集,包含了 150 种语言的 14 万个不同的字符。)
- **字符编码:**是对于字符集里的这些字符,怎么一一用二进制表示出来的一个字典。Unicode,就可以用 UTF-8、UTF-16,乃至 UTF-32 来进行编码,存储成二进制。
同样的文本,采用不同的编码存储下来。如果另外一个程序,用一种不同的编码方式来进行解码和展示,就会出现乱码。这就好像两个军队用密语通信,如果用错了密码本,那看到的消息就会不知所云。
拓展:“手持两把锟斤拷,口中疾呼烫烫烫。脚踏千朵屯屯屯,笑看万物锘锘锘。”

实现一个 “锟斤拷”
print('�'.encode('utf-8'))
b'\xef\xbf\xbd'
print('锟斤拷'.encode('gbk'))
b'\xef\xbf\xbd\xef\xbf\xbd'
print('�'.encode('utf-8').decode('gbk'))
# UnicodeDecodeError: 'gbk' codec can't decode byte 0xbd in position 2: incomplete multibyte sequence
print('�'.encode('utf-8').decode('gbk', errors='ignore'))
锟
print('�'.encode('utf-8').decode('gbk', errors='replace'))
锟�
print('��'.encode('utf-8').decode('gbk'))
锟斤拷
遇到全是烫烫烫的这种情况,赶紧为CPU降频,CPU太烫了!(狗头)
烫,屯,葺 三个字符的频繁出现是和微软系的编译器有关,
- 静态分配而未初始化的内存空间,默认使用 CC 填充,CCCC 对应 GBK 编码的
烫 - 动态分配而未初始化的内存空间,默认使用 CD 填充,CDCD 对应 GBK 编码的
屯 - 动态分配然后被回收的内存空间,默认使用 DD 填充,DDDD 对应 GBK 编码的
葺
Windows 中文版本的默认编码是 GBK,一输出就显示成了 烫烫烫, 屯屯屯, 葺葺葺。
print((b'\xcc' * 6).decode('gbk'))
# 烫烫烫
print((b'\xcd' * 6).decode('gbk'))
# 屯屯屯
print((b'\xdd' * 6).decode('gbk'))
# 葺葺葺
数字电路
数字电路相关知识 ->数字电路基础 - 简书 (jianshu.com)
浮点数和定点数(0.3+0.6==0.9为啥为false)

我们现在用的计算机通常用 16/32 个比特(bit)来表示一个数。32 个比特,只能表示 2 的 32 次方个不同的数,差不多是 40 亿个。如果表示的数要超过这个数,就会有两个不同的数的二进制表示是一样的。那计算机可就会一筹莫展,不知道这个数到底是多少。
我到底应该让这 40 亿个数映射到实数集合上的哪些数,在实际应用中才能最划得来呢?
定点数的表示
有一个很直观的想法,就是我们用 4 个比特来表示 0~9 的整数,那么 32 个比特就可以表示 8 个这样的整数。然后我们把最右边的 2 个 0~9 的整数,当成小数部分;把左边 6 个0~9 的整数,当成整数部分。这样,我们就可以用 32 个比特,来表示从 0 到 999999.99这样 1 亿个实数了。

它的运用非常广泛,最常用的是在超市、银行这样需要用小数记录金额的情况里。在超市里面,我们的小数最多也就到分。这样的表示方式,比较直观清楚,也满足了小数部分的计算。
不过,这样的表示方式也有几个缺点:
- 浪费,本来 32 个比特我们可以表示 40 亿个不同的数,但是在 BCD 编码下,只能表示 1 亿个数,如果我们要精确到分的话,那么能够表示的最大金额也就是到 100 万。
- **这样的表示方式没办法同时表示很大的数字和很小的数字。**我们在写程序的时候,实数的用途可能是多种多样的。有时候我们想要表示商品的金额,关心的是 9.99 这样小的数字;有时候,我们又要进行物理学的运算,需要表示光速,也就是 这样很大的数字。3 × 10^8
浮点数的表示
一个现实问题:有限宽度的便签,只能写下有限大小的数字。
这里的纸张宽度,就和我们 32 个比特一样,是在空间层面的限制。那么,在现实生活中,我们是怎么表示一个很大的数的呢?比如说,我们想要在一本科普书里,写一下宇宙内原子的数量,莫非是用一页纸,用好多行写下很多个 0 么?
到这里你肯定能想到,科学计数法。
在计算机里,我们也可以用一样的办法,用科学计数法来表示实数。浮点数的科学计数法的表示,有一个IEEE的标准,它定义了两个基本的格式。
- 用 32 比特表示单精度的浮点数,也就是我们常常说的
float或者float32类型。 - 另外一个是用 64 比特表示双精度的浮点数,也就是我们平时说的
double或者float64类型。
单精度:
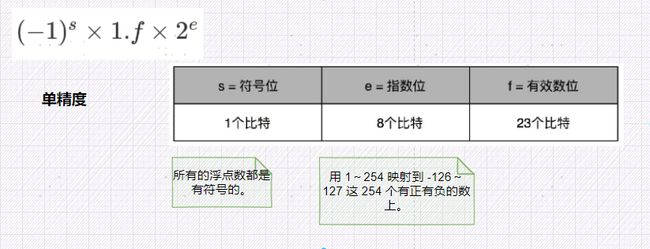
你会发现,这里的浮点数,没有办法表示 0。的确,要表示 0 和一些特殊的数,我们就要用上在 e 里面留下的 0 和 255 这两个表示,这两个表示其实是两个标记位。在 e 为 0 且 f为 0 的时候,我们就把这个浮点数认为是 0。至于其它的 e 是 0 或者 255 的特殊情况,你可以看下面这个表格,分别可以表示出无穷大、无穷小、NAN 以及一个特殊的不规范数。

举个栗子:0.5该如何表示呢?

精度问题:为什么我们用 0.3 + 0.6 不能得到 0.9 呢?
浮点数没有办法精确表示 0.3、0.6 和 0.9。事实上,我们拿出 0.1~0.9 这 9 个数,其中只有 0.5 能够被精确地表示成二进制的浮点数,也就是 s = 0、e = -1、f = 0 这样的情况。而 0.3、0.6 乃至我们希望的 0.9,都只是一个近似的表达。
那么,在使用过程中,我们该怎么来使用浮点数,以及使用浮点数会遇到些什么问题呢?
深入理解浮点数到底怎么用
浮点数可以大到
3.40 × 10^38,也可以小到1.17 × 10^38这样的数值。同时,我们也发现,其实我们平时写的 0.1、0.2 并不是精确的数值,只是一个近似值。只有 0.5 这样,可以表示成2^1这种形式的,才是一个精确的浮点数。
我们在实际应用中,该怎么用好浮点数呢?
搞清楚了怎么把一个十进制的数值,转化成 IEEE-754 标准下的浮点数表示,我们现在来看一看浮点数的加法是怎么进行的。其实原理也很简单,你记住六个字就行了,那就是先对齐、再计算。
两个浮点数的指数位可能是不一样的,所以我们要把两个的指数位,变成一样的,然后只去计算有效位的加法就好了。
其中指数位较小的数,需要在有效位进行右移,在右移的过程中,最右侧的有效位就被丢弃掉了。这会导致对应的指数位较小的数,在加法发生之前,就丢失精度。
举个例子,两个差距非常大的浮点数相加,小的精度就会被完全抛弃:(加到 1600 万之后的加法因为精度丢失都没有了)
public class FloatPrecision {
public static void main(String[] args) {
float sum = 0.0f;
for (int i = 0; i < 20000000; i++) {
float x = 1.0f;
sum += x;
}
System.out.println("sum is " + sum);
}
}
sum is 1.6777216E7
Kahan Summation 算法
我们有没有什么办法来解决这个精度丢失问题呢?虽然我们在计算浮点数的时候,常常可以容忍一定的精度损失,但是像上面那样,如果我们连续加 2000 万个 1,2000 万的数值都会被精度损失丢掉了,就会影响我们的计算结果。
面对这个问题,聪明的计算机科学家们也想出了具体的解决办法。他们发明了一种叫作Kahan Summation的算法来解决这个问题。
public class KahanSummation {
public static void main(String[] args) {
float sum = 0.0f;
float c = 0.0f;
for (int i = 0; i < 20000000; i++) {
float x = 1.0f;
float y = x - c;
float t = sum + y;
c = (t-sum)-y;
sum = t;
}
System.out.println("sum is " + sum);
}
}
sum is 2.0E7
其实这个算法的原理其实并不复杂,就是在每次的计算过程中,都用一次减法,把当前加法计算中损失的精度记录下来,然后在后面的循环中,把这个精度损失放在要加的小数上,再做一次运算。
总结:
一般情况下,在实践应用中,对于需要精确数值的,比如银行存款、电商交易,我们都会使用定点数或者整数类型。
比方说,你一定在 MySQL 里用过 decimal(12,2),来表示订单金额。如果我们的银行存款用 32 位浮点数表示,就会出现,马云的账户里有 2 千万,我的账户里只剩 1 块钱。结果银行一汇总总金额,那 1 块钱在账上就“不翼而飞”了。
而浮点数呢,则更适合我们不需要有一个非常精确的计算结果的情况。对于浮点数加法中可能存在的精度损失,特别是大量加法运算中累积产生的巨大精度损失,我们可以用 Kahan Summation 这样的软件层面的算法来解决。
计算机处理器
CPU
CPU所负责的就是解释和运行族中转换成机器语言的程序内容。
CPU内部由寄存器、控制器、运算器和时钟四个部分构成,各部分由电流信号相互连通。
- 寄存器可用来暂存指令、数据等处理对象那可以将之看成内存的一种,一个CPU内部会有20~100个寄存器。
- 控制器负责把内存上的指令、数据等读入寄存器,并根据指令的执行结果来控制整个计算机。
- 运算器负责运算从内存读入寄存器的数据。
- 时钟负责发出CPU开始计时的时钟信号(频率越高,CPU运行速度越快),有些时钟不在CPU内部。
GPU
GPU英文全称Graphic Processing Unit,中文翻译为“图形处理器”。 GPU是相对于CPU的一个概念,由于在现代的计算机中(特别是家用系统,游戏的发烧友)图形的处理变得越来越重要,需要一个专门的图形的核心处理器。 GPU是一种芯片,是一种显示芯片,是显卡的心脏。
GPU与CPU有什么区别
CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。主要区别如下。
CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。
于是CPU和GPU就呈现出非常不同的架构。
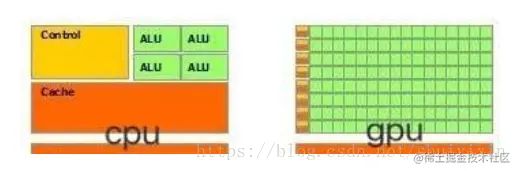
其中上图中绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。
GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。而CPU不仅被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分。
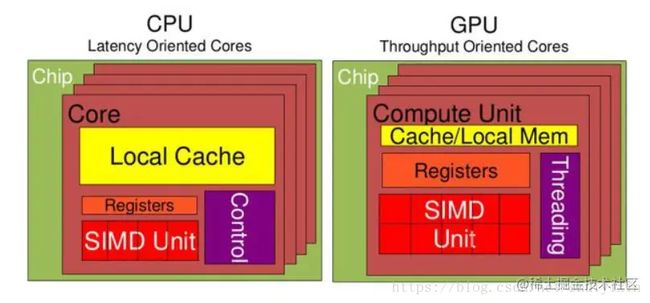
CPU 基于低延时的设计:
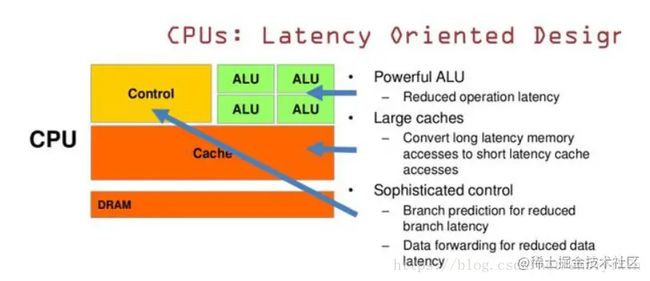
CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方).大的缓存也可以降低延时。保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
复杂的逻辑控制单元。当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。

GPU是基于大的吞吐量设计。
GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread. 为啦平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的Threads.通常来看GPU ALU会有非常重的pipeline就是因为这样。所以与CPU擅长逻辑控制,串行的运算。和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。所以GPU除了图像处理,也越来越多的参与到计算当中来。
上面说的有点专业化,接下来就简单说一下,他们两个到底差在哪?
CPU(Central Processing Unit)是电脑最主要的部件,他的主要功能是解释计算机指令以及处理计算机软件中的数据,说白了就是做指挥工作,统筹各方面。CPU相当于整个电脑的心脏,而GPU相当于显卡的心脏。
普通的处理器CPU差不多双核心四线程,目前市面上最高端的桌面处理器i9-7980XE(RMB1.5万)不过十八核心三十六线程。GPU则不同,就拿普通的2000块的游戏显卡RX 480来说,RX480的GPU芯片计算单元划分为36个CU计算核心,每个CU核心又包含了64个流处理器计算核心,所以总共就是36X64=2304个流处理器计算核心。
CPU相对于GPU就像老教授和小学生,拿i9-7980XE和RX480举个例子,出一套小学数学试卷,老教授刚做一道题,两千多名学生一人一题早就交卷子了。如果套高数卷子,老教授做完学生们一道也不会做。
存储器和I/O系统
如果你自己组装过 PC 机,你肯定知道,想要 CPU,我们只要买一个就好了,但是存储器,却有不同的设备要买。比方说,我们要买内存,还要买硬盘。买硬盘的时候,不少人会买一块 SSD 硬盘作为系统盘,还会买上一块大容量的 HDD 机械硬盘作为数据盘。内存和硬盘都是我们的存储设备。而且,像硬盘这样的持久化存储设备,同时也是一个 I/O 设备。
在实际的软件开发过程中,我们常常会遇到服务端的请求响应时间长,吞吐率不够的情况。在分析对应问题的时候,相信你没少听过类似“主要瓶颈不在 CPU,而在 I/O”的论断。可见,存储在计算机中扮演着多么重要的角色。
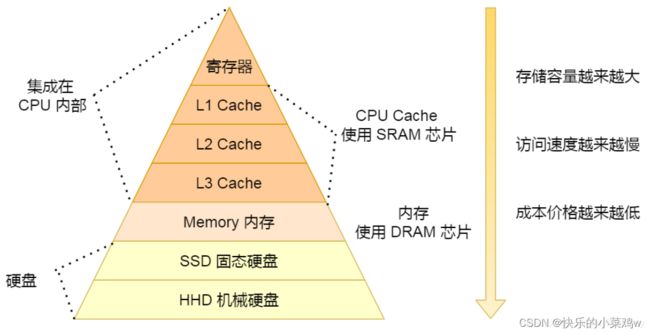
存储器的层次结构
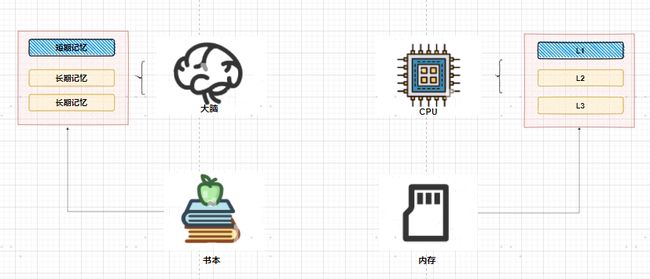
我们常常把 CPU 比喻成计算机的“大脑”。我们思考的东西,就好比 CPU 中的寄存器(Register)。寄存器与其说是存储器,其实它更像是 CPU 本身的一部分,只能存放极其有限的信息,但是速度非常快,和 CPU 同步。
而我们大脑中的记忆,就好比CPU Cache(CPU 高速缓存,我们常常简称为“缓存”)。CPU Cache 用的是一种叫作SRAM(Static Random-Access Memory,静态随机存取存储器)的芯片。
SRAM

SRAM 之所以被称为“静态”存储器,是因为只要处在通电状态,里面的数据就可以保持存在。而一旦断电,里面的数据就会丢失了。
在 SRAM 里面,一个比特的数据,需要 6~8个晶体管。所以 SRAM 的存储密度不高。同样的物理空间下,能够存储的数据有限。不
过,因为 SRAM 的电路简单,所以访问速度非常快。
在 CPU 里,通常会有 L1、L2、L3 这样三层高速缓存。
- 每个 CPU 核心都有一块属于自己的 L1 高速缓存,通常分成
指令缓存和数据缓存,分开存放 CPU 使用的指令和数据。L1 的 Cache 往往就嵌在 CPU 核心的内部。 - L2 的 Cache 同样是每个 CPU 核心都有的,不过它往往不在 CPU 核心的内部。所以,L2Cache 的访问速度会比 L1 稍微慢一些。
- L3 Cache,则通常是多个 CPU 核心共用的,尺寸会更大一些,访问速度自然也就更慢一些。
CPU 中的 L1 Cache 理解为我们的短期记忆,把 L2/L3 Cache 理解成长期记忆,把内存当成我们拥有的书架或者书桌。 当我们自己记忆中没有资料的时候,可以从书桌或者书架上拿书来翻阅。这个过程中就相当于,数据从内存中加载到 CPU 的寄存器和 Cache中,然后通过“大脑”,也就是 CPU,进行处理和运算。
DRAM

内存用的芯片和 Cache 有所不同,它用的是一种叫作DRAM(Dynamic Random AccessMemory,动态随机存取存储器)的芯片,比起 SRAM 来说,它的密度更高,有更大的容量,而且它也比 SRAM 芯片便宜不少。
DRAM 被称为“动态”存储器,是因为 DRAM 需要靠不断地“刷新”,才能保持数据被存储起来。DRAM 的一个比特,只需要一个晶体管和一个电容就能存储。所以,DRAM 在同样的物理空间下,能够存储的数据也就更多,也就是存储的“密度”更大。但是,因为数据是存储在电容里的,电容会不断漏电,所以需要定时刷新充电,才能保持数据不丢失。DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问延时也就更长。
存储器的层次结构
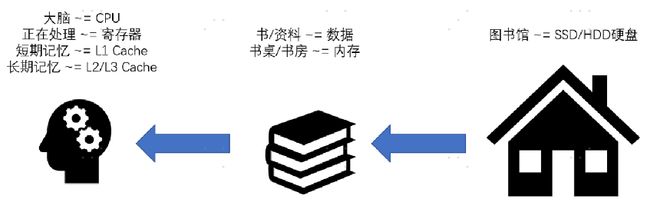
对于内存来说,SSD(Solid-state drive 或 Solid-statedisk,固态硬盘)、HDD(Hard Disk Drive,硬盘)这些被称为硬盘的外部存储设备,就
是公共图书馆。于是,我们就可以去家附近的图书馆借书了。图书馆有更多的空间(存储空间)和更多的书(数据)。
CPU 并不是直接和每一种存储器设备打交道,而是每一种存储器设备,只和它相邻的存储设备打交道。
局部性原理
平时进行服务端软件开发的时候,我们通常会把数据存储在数据库里。而服务端系统遇到的第一个性能瓶颈,往往就发生在访问数据库的时候。这个时候,大部分工程师和架构师会拿出一种叫作“缓存”的武器。但是添加缓存的策略一定是有效的吗?
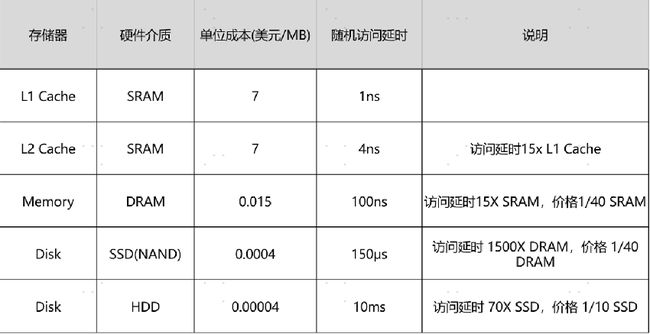
可以看到,不同的存储器设备之间,访问速度、价格和容量都有几十乃至上千倍的差异。
我们能不能既享受 CPU Cache 的速度,又享受内存、硬盘巨大的容量和低廉的价格呢?
想要同时享受到这三点,前辈们已经探索出了答案,那就是,存储器中数据的局部性原理(Principle of Locality)。我们可以利用这个局部性原理,来制定管理和访问数据的策略。这个局部性原理包括时间局部性(temporal locality)和空间局部性(spatial locality)这两种策略。
时间局部性
这个策略是说,如果一个数据被访问了,那么它在短时间内还会被再次访问。这么看这个策略有点奇怪是吧?我用一个简单的例子给你解释下,你一下就能明白了。
比如说,《盗墓笔记》这本书,我今天读了一会儿,没读完,明天还会继续读。同理,在一个电子商务型系统中,如果一个用户打开了 App,看到了首屏。我们推断他应该很快还会再次访问网站的其他内容或者页面,我们就将这个用户的个人信息,从存储在硬盘的数据库读取到内存的缓存中来。这利用的就是时间局部性。
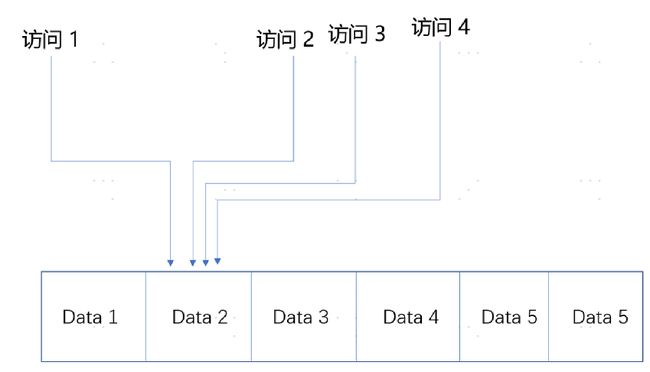
空间局部性
这个策略是说,如果一个数据被访问了,那么和它相邻的数据也很快会被访问。
我们还拿刚才读《盗墓笔记》的例子来说。我读完了这本书之后,感觉这书不错,所以就会借阅整套“盗墓笔记”。这就好比我们的程序,在访问了数组的首项之后,多半会循环访问它的下一项。因为,在存储数据的时候,数组内的多项数据会存储在相邻的位置。这就好比图书馆会把“盗墓笔记”系列放在一个书架上,摆放在一起,加载的时候,也会一并加载。我们去图书馆借书,往往会一次性把整套都借回来。

有了时间局部性和空间局部性,我们不用再把所有数据都放在内存里,也不用都放在 HDD硬盘上,**而是把访问次数多的数据,放在贵但是快一点的存储器里,把访问次数少的数据,放在慢但是大一点的存储器里。**这样组合使用内存、SSD 硬盘以及 HDD 硬盘,使得我们可以用最低的成本提供实际所需要的数据存储、管理和访问的需求。
举个栗子:
- 我们现在要提供一个亚马逊这样的电商网站。我们假设里面有 6 亿件商品,如果每件商品需要 4MB 的存储空间(考虑到商品图片的话,4MB 已经是一个相对较小的估计了),那么一共需要 2400TB( = 6 亿 × 4MB)的数据存储。
- 如果我们把数据都放在内存里面,那就需要 3600 万美元( = 2400TB/1MB × 0.015 美元= 3600 万美元)。但是,这 6 亿件商品中,不是每一件商品都会被经常访问。比如说,有Kindle 电子书这样的热销商品,也一定有基本无人问津的商品,比如偏门的缅甸语词典。
- 如果我们只在内存里放前 1% 的热门商品,也就是 600 万件热门商品,而把剩下的商品,放在机械式的 HDD 硬盘上,那么,我们需要的存储成本就下降到 45.6 万美元( = 3600万美元 × 1% + 2400TB / 1MB × 0.00004 美元),是原来成本的 1.3% 左右。
这里我们用的就是时间局部性。我们把有用户访问过的数据,加载到内存中,一旦内存里面放不下了,我们就把最长时间没有在内存中被访问过的数据,从内存中移走,这个其实就是我们常用的LRU(Least Recently Used)缓存算法。
热门商品被访问得多,就会始终被保留在内存里,而冷门商品被访问得少,就只存放在 HDD 硬盘上,数据的读取也都是直接访问硬盘。即使加载到内存中,也会很快被移除。越是热门的商品,越容易在内存中找到,也就更好地利用了内存的随机访问性能。
CPU Cache
引入
int[] arr = new int[64 * 1024 * 1024];
// 循环 1
for (int i = 0; i < arr.length; i++) {arr[i] *= 3;}
// 循环 2
for (int i = 0; i < arr.length; i += 16) {arr[i] *= 3}
运行两个循环,统计运行时间:
循环1: 50 ms
循环2: 46 ms
按道理来说,循环 2 只访问循环 1 中 1/16 的数组元素,只进行了循环 1 中 1/16 的乘法计算,那循环 2 花费的时间应该是循环 1 的 1/16 左右。但是实际上,这两个循环花费时间之差在 15% 之内。
高速缓存
在 CPU 眼里,内存也慢得不行(在今天,CPU 和内存的访问速度已经有了 120倍的差距)。
于是,聪明的工程师们就在 CPU 里面嵌入了 CPU Cache(高速缓存),来解决这一问题。
为了弥补两者之间的性能差异,我们能真实地把 CPU 的性能提升用起来,而不是让它在那儿空转,我们在现代 CPU 中引入了高速缓存。
从 CPU Cache 被加入到现有的 CPU 里开始,内存中的指令、数据,会被加载到 L1-L3Cache 中,而不是直接由 CPU 访问内存去拿。在 95% 的情况下,CPU 都只需要访问 L1-L3 Cache,从里面读取指令和数据,而无需访问内存。
要注意的是,这里我们说的 CPUCache 或者 L1/L3 Cache,不是一个单纯的、概念上的缓存(比如之前我们说的拿内存作为硬盘的缓存),而是指特定的由 SRAM 组成的物理芯片。
这里是一张 Intel CPU 的放大照片。这里面大片的长方形芯片,就是这个 CPU 使用的20MB 的 L3 Cache。

在之前的程序里,运行程序的时间主要花在了将对应的数据从内存中读取出来,加载到 CPU Cache 里。CPU 从内存中读取数据到 CPU Cache 的过程中,是一小块一小块来读取数据的,而不是按照单个数组元素来读取数据的。这样一小块一小块的数据,在 CPUCache 里面,我们把它叫作 Cache Line(缓存块)。
在我们日常使用的 Intel 服务器或者 PC 里,Cache Line 的大小通常是 64 字节。而在上面的循环 2 里面,我们每隔 16 个整型数计算一次,16 个整型数正好是 64 个字节。于是,循环 1 和循环 2,需要把同样数量的 Cache Line 数据从内存中读取到 CPU Cache 中,最终两个程序花费的时间就差别不大了。
Cache 的数据结构和读取过程
现代 CPU 进行数据读取的时候,无论数据是否已经存储在 Cache 中,CPU 始终会首先访问 Cache。只有当 CPU 在 Cache 中找不到数据的时候,才会去访问内存,并将读取到的数据写入 Cache 之中。当时间局部性原理起作用后,这个最近刚刚被访问的数据,会很快再次被访问。而 Cache 的访问速度远远快于内存,这样,CPU 花在等待内存访问上的时间就大大变短了。
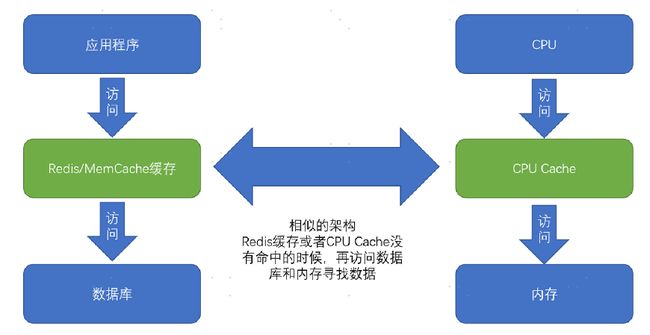
CPU 如何知道要访问的内存数据,存储在 Cache 的哪个位置呢?
直接映射
在开头的 3 行小程序里我说过,CPU 访问内存数据,是一小块一小块数据来读取的。对于读取内存中的数据,我们首先拿到的是数据所在的内存块(Block)的地址。而直接映射Cache 采用的策略,就是确保任何一个内存块的地址,始终映射到一个固定的 CPU Cache地址(Cache Line)。而这个映射关系,通常用 mod 运算(求余运算)来实现。下面我举个例子帮你理解一下。
比如说,我们的主内存被分成 0~31 号这样 32 个块。我们一共有 8 个缓存块。用户想要访问第 21 号内存块。如果 21 号内存块内容在缓存块中的话,它一定在 5 号缓存块(21mod 8 = 5)中。

实际计算中,有一个小小的技巧,通常我们会把缓存块的数量设置成 2 的 N 次方。这样在计算取模的时候,可以直接取地址的低 N 位,也就是二进制里面的后几位。比如这里的 8个缓存块,就是 2 的 3 次方。那么,在对 21 取模的时候,可以对 21 的 2 进制表示10101 取地址的低三位,也就是 101,对应的 5,就是对应的缓存块地址。
取 Block 地址的低位,就能得到对应的 Cache Line 地址,除了 21 号内存块外,13 号、5号等很多内存块的数据,都对应着 5 号缓存块中。既然如此,假如现在 CPU 想要读取 21号内存块,在读取到 5 号缓存块的时候,我们怎么知道里面的数据,究竟是不是 21 号对应的数据呢?
- 组标记,在对应的缓存块中,我们会存储一个组标记(Tag),我们只需要记录 21 剩余的高 2 位的信息,也就是 10 就可以了。
- 有效位,它其实就是用来标记,对应的缓存块中的数据是否是有效的,确保不是机器刚刚启动时候的空数据。
CPU 在读取数据的时候,并不是要读取一整个 Block,而是读取一个他需要的整数。这样的数据,我们叫作 CPU 里的一个字(Word)。具体是哪个字,就用这个字在整个 Block里面的位置来决定。这个位置,我们叫作偏移量(Offset)。
一个内存的访问地址,最终包括高位代表的组标记、低位代表的索引,以及在对应的 Data Block 中定位对应字的位置偏移量。

如果内存中的数据已经在 CPU Cache 里了,那一个内存地址的访问,就会经历这样 4 个步骤:
- 根据内存地址的低位,计算在 Cache 中的索引;
- 判断有效位,确认 Cache 中的数据是有效的;
- 对比内存访问地址的高位,和 Cache 中的组标记,确认 Cache 中的数据就是我们要访问的内存数据,从 Cache Line 中读取到对应的数据块(Data Block);
- 根据内存地址的 Offset 位,从 Data Block 中,读取希望读取到的字。
其实,除了直接映射 Cache 之外,我们常见的缓存放置策略还有全相连 Cache(Fully Associative Cache)、组相连 Cache(Set Associative
Cache)。这几种策略的数据结构都是相似的,理解了最简单的直接映射 Cache,其他的策略你很容易就能理解了。
Cache 的写入
如果你是一名Java工程师,那么你一定知道JMM模型,理解了JMM模型可以很容易的理解计算机组成里的CPU、Cache、主内存的关系。
我们现在用的 Intel CPU,通常都是多核的的。每一个 CPU 核里面,都有独立属于自己的L1、L2 的 Cache,然后再有多个 CPU 核共用的 L3 的 Cache、主内存。
因为 CPU Cache 的访问速度要比主内存快很多,而在 CPU Cache 里面,L1/L2 的 Cache也要比 L3 的 Cache 快。所以,上一讲我们可以看到,CPU 始终都是尽可能地从 CPUCache 中去获取数据,而不是每一次都要从主内存里面去读取数据。

由于这种结构,在写入数据的时候,就引发了两个问题:
- 写数据的时候,应该写到Cache还是主内存呢?
- 如果写到了主内存,那么Cache中的数据是否会失效?
写直达(Write-Through)
写直达把所有的数据都直接写入到主内存里面,简单直观,但是性能就会受限于内存的访问速度。
写直达的这个策略很直观,但是问题也很明显,那就是这个策略很慢。无论数据是不是在 Cache 里面,我们都需要把数据写到主内存里面。这个方式就有点儿像我们Java中的 volatile 关键字,始终都要把数据同步到主内存里面。

写回(Write-Back)
写回则通常只更新缓存,只有在需要把缓存里面的脏数据交换出去的时候,才把数据同步到主内存里。在缓存经常会命中的情况下,性能更好。
这个策略里,我们不再是每次都把数据写入到主内存,而是只写到 CPU Cache 里。只有当 CPU Cache 里面的数据要被“替换”的时候,我们才把数据写入到主内存里面去。
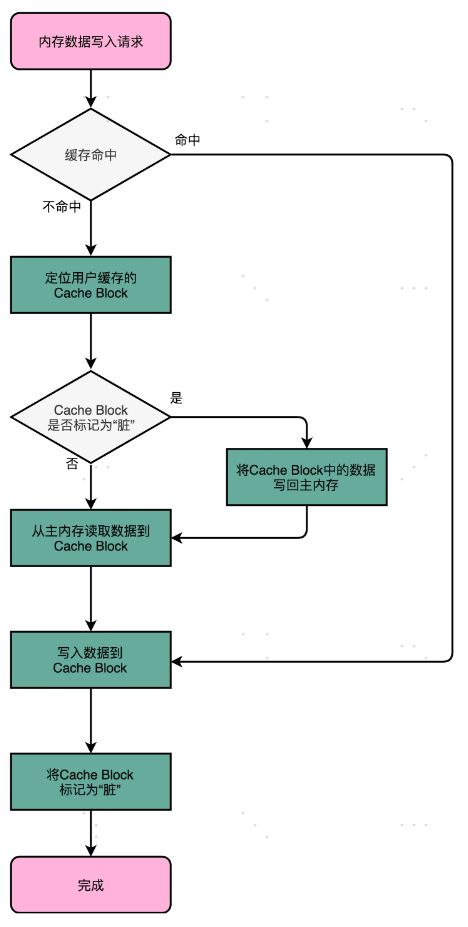
缓存一致性问题
多核 CPU 里的每一个 CPU 核,都有独立的属于自己的 L1 Cache 和 L2 Cache。多个 CPU 之间,只是共用 L3 Cache 和主内存。
CPU Cache 解决的是内存访问速度和 CPU 的速度差距太大的问题。而多核 CPU 提供的是,在主频难以提升的时候,通过增加 CPU 核心来提升 CPU 的吞吐率的办法。我们把多核和 CPU Cache 两者一结合,就给我们带来了一个新的挑战。因为 CPU 的每个核各有各的缓存,互相之间的操作又是各自独立的,就会带来**缓存一致性(Cache Coherence)**的问题。
什么时缓存一致性?举个例子:
比方说,iPhone 降价了,我们要把 iPhone 最新的价格更新到内存里。为了性能问题,它采用了上一讲我们说的写回策略,先把数据写入到 L2 Cache 里面,然后把 Cache Block 标记成脏的。这个时候,数据其实并没有被同步到 L3 Cache 或者主内存里。1 号核心希望在这个 Cache Block 要被交换出去的时候,数据才写入到主内存里。
如果我们的 CPU 只有 1 号核心这一个 CPU 核,那这其实是没有问题的。不过,我们旁边还有一个 2 号核心呢!这个时候,2 号核心尝试从内存里面去读取 iPhone 的价格,结果读到的是一个错误的价格。这是因为,iPhone 的价格刚刚被 1 号核心更新过。但是这个更新的信息,只出现在 1 号核心的 L2 Cache 里,而没有出现在 2 号核心的 L2 Cache 或者主内存里面。这个问题,就是所谓的缓存一致性问题,1 号核心和 2 号核心的缓存,在这个时候是不一致的。
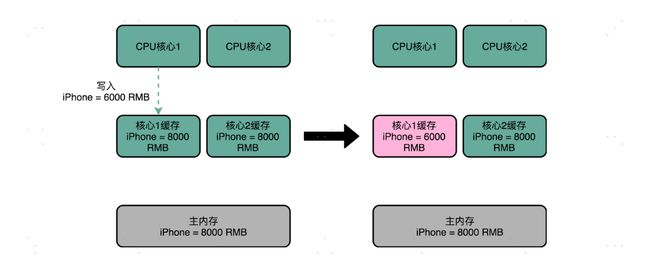
为了解决这个缓存不一致的问题,我们就需要有一种机制,来同步两个不同核心里面的缓存数据。
这样的机制需要满足什么条件呢?
- 写传播,在一个 CPU 核心里,我们的 Cache 数据更新,必须能够传播到其他的对应节点的 Cache Line 里。
- 事务的串行化,我们在一个 CPU 核心里面的读取和写入,在其他的节点看起来,顺序是一样的。
事务串行化:
我们还拿刚才修改 iPhone 的价格来解释。这一次,我们找一个有 4 个核心的 CPU。1 号核心呢,先把 iPhone 的价格改成了 5000 块。差不多在同一个时间,2 号核心把 iPhone 的价格改成了 6000 块。这里两个修改,都会传播到 3 号核心和 4 号核心。
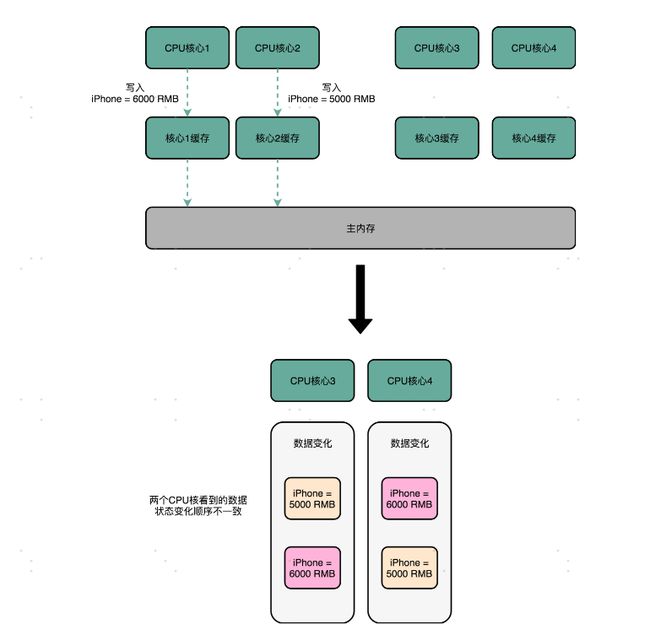
然而这里有个问题,3 号核心先收到了 2 号核心的写传播,再收到 1 号核心的写传播。所以 3 号核心看到的 iPhone 价格是先变成了 6000 块,再变成了 5000 块。而 4 号核心呢,是反过来的,先看到变成了 5000 块,再变成 6000 块。虽然写传播是做到了,但是各个 Cache 里面的数据,是不一致的。
事实上,我们需要的是,从 1 号到 4 号核心,都能看到相同顺序的数据变化。比如说,都是先变成了 5000 块,再变成了 6000 块。这样,我们才能称之为实现了事务的串行化。
事务的串行化,不仅仅是缓存一致性中所必须的。比如,我们平时所用到的系统当中,最需要保障事务串行化的就是数据库。多个不同的连接去访问数据库的时候,我们必须保障事务的串行化,做不到事务的串行化的数据库,根本没法作为可靠的商业数据库来使用。
而在 CPU Cache 里做到事务串行化,需要做到两点:
- 第一点是一个 CPU 核心对于数据的操作,需要同步通信给到其他 CPU 核心。
- 第二点是,如果两个 CPU 核心里有同一个数据的 Cache,那么对于这个 Cache 数据的更新,需要有一个“锁”的概念。只有拿到了对应 Cache Block 的“锁”之后,才能进行对应的数据更新。接下来,我们就看看实现了这两个机制的 MESI 协议。
总线嗅探机制和MESI协议
要解决缓存一致性问题,首先要解决的是多个 CPU 核心之间的数据传播问题。最常见的一种解决方案呢,叫作总线嗅探(Bus Snooping)。
这个策略,本质上就是把所有的读写请求都通过总线(Bus)广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。
基于总线嗅探机制,其实还可以分成很多种不同的缓存一致性协议。其中最常用的,就是 MESI 协议。
MESI 协议,是一种叫作**写失效(Write Invalidate)**的协议。在写失效协议里,只有一个 CPU 核心负责写入数据,其他的核心,只是同步读取到这个写入。在这个 CPU 核心写入 Cache 之后,它会去广播一个“失效”请求告诉所有其他的 CPU 核心。其他的 CPU 核心,只是去判断自己是否也有一个“失效”版本的 Cache Block,然后把这个也标记成失效的就好了。
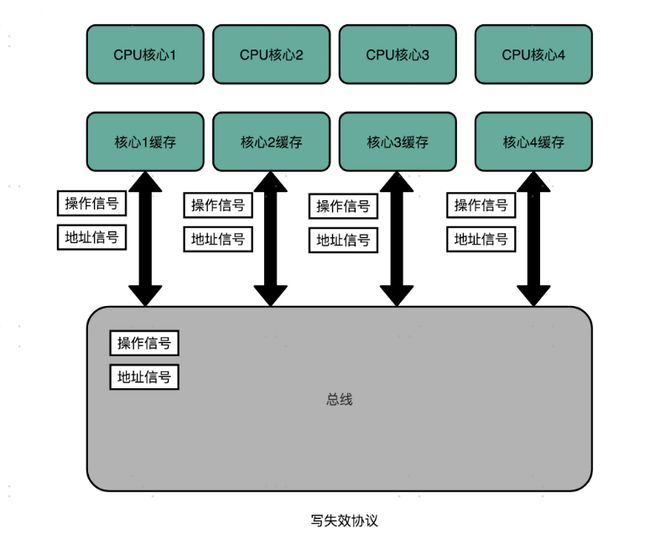
相对于写失效协议,还有一种叫作**写广播(Write Broadcast)**的协议。在这个协议里,一个写入请求广播到所有的 CPU 核心,同时更新各个核心里的 Cache。写广播在实现上自然很简单,但是写广播需要占用更多的总线带宽。写失效只需要告诉其他的 CPU 核心,哪一个内存地址的缓存失效了,但是写广播还需要把对应的数据传输给其他 CPU 核心。

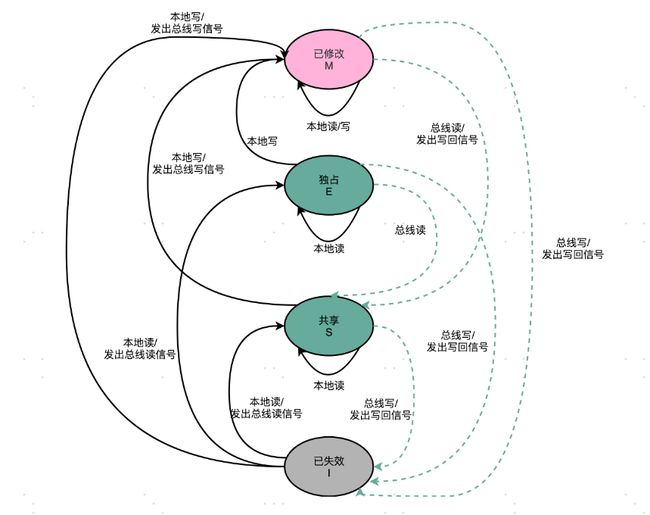
MESI 协议的由来呢,来自于我们对 Cache Line 的四个不同的标记,分别是:
- M:代表已修改(Modified)
- E:代表独占(Exclusive)
- S:代表共享(Shared)
- I:代表已失效(Invalidated)
无论是独占状态还是共享状态,缓存里面的数据都是“干净”的。这个“干净”,自然对应的是前面所说的“脏”的,也就是说,这个时候,Cache Block 里面的数据和主内存里面的数据是一致的。
在独占状态下,对应的 Cache Line 只加载到了当前 CPU 核所拥有的 Cache 里。其他的 CPU 核,并没有加载对应的数据到自己的 Cache 里。这个时候,如果要向独占的 Cache Block 写入数据,我们可以自由地写入数据,而不需要告知其他 CPU 核。
在独占状态下,对应的 Cache Line 只加载到了当前 CPU 核所拥有的 Cache 里。其他的 CPU 核,并没有加载对应的数据到自己的 Cache 里。这个时候,如果要向独占的 Cache Block 写入数据,我们可以自由地写入数据,而不需要告知其他 CPU 核。
而在共享状态下,因为同样的数据在多个 CPU 核心的 Cache 里都有。所以,当我们想要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他 CPU 核心里面的 Cache,都变成无效的状态,然后再更新当前 Cache 里面的数据。这个广播操作,一般叫作 RFO(Request For Ownership),也就是获取当前对应 Cache Block 数据的所有权。
有没有觉得这个操作有点儿像我们在多线程里面用到的读写锁。在共享状态下,大家都可以并行去读对应的数据。但是如果要写,我们就需要通过一个锁,获取当前写入位置的所有权。
整个 MESI 的状态,可以用一个有限状态机来表示它的状态流转。需要注意的是,对于不同状态触发的事件操作,可能来自于当前 CPU 核心,也可能来自总线里其他 CPU 核心广播出来的信号。我把对应的状态机流转图放在了下面,你可以对照着Wikipedia 里面 MESI 的内容,仔细研读一下。
理解内存
虚拟内存和内存保护
我们的内存需要被分成固定大小的页(Page),然后再通过虚拟内存地址(VirtualAddress)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而我们的程序看到的内存地址,都是虚拟内存地址。
这些虚拟内存地址究竟是怎么转换成物理内存地址的呢?
简单页表
想要把虚拟内存地址,映射到物理内存地址,最直观的办法,就是来建一张映射表。这个映射表,能够实现虚拟内存里面的页,到物理内存里面的页的一一映射。这个映射表,在计算机里面,就叫作页表(Page Table)。页表这个地址转换的办法,会把一个内存地址分成**页号(Directory)和偏移量(Offset)**两个部分。

总结一下,对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量的组合;
- 从页表里面,查询出虚拟页号,对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
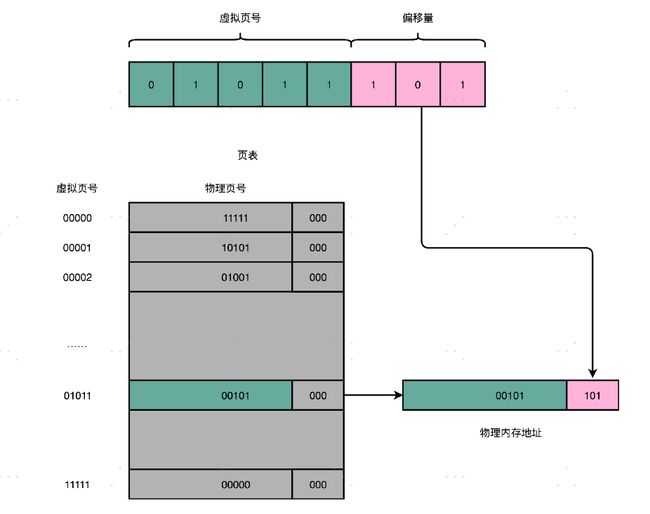
我们以 32 位的内存地址空间为例,32 位的内存地址空间,页表一共需要记录 2^20 个到物理页号的映射关系。这个存储关系,就好比一个 2^20 大小的数组。一个页号是完整的 32 位的4 字节(Byte),这样一个页表就需要 4MB 的空间。
我们每一个进程,都有属于自己独立的虚拟内存地址空间。这也就意味着,每一个进程都需要这样一个页表。不管我们这个进程,是个本身只有几 KB 大小的程序,还是需要几 GB 的内存空间,都需要这样一个页表。如果你用的是Windows,你可以打开你自己电脑上的任务管理器看看,现在你的计算机里同时在跑多少个进程,用这样的方式,页表需要占用多大的内存。

这还只是 32 位的内存地址空间,现在大家用的内存,多半已经超过了 4GB,也已经用上了 64 位的计算机和操作系统。这样的话,用上面这个数组的数据结构来保存页面,内存占用就更大了。那么,我们有没有什么更好的解决办法呢?你可以先仔细思考一下。
多级页表
仔细想一想,我们其实没有必要存下这 2^20 个物理页表啊。大部分进程所占用的内存是有限的,需要的页也自然是很有限的。我们只需要去存那些用到的页之间的映射关系就好了。
我们先来看一看,一个进程的内存地址空间是怎么分配的。在整个进程的内存地址空间,通常是“两头实、中间空”。在程序运行的时候,内存地址从顶部往下,不断分配占用的栈的空间。而堆的空间,内存地址则是从底部往上,是不断分配占用的。
**在一个实际的程序进程里面,虚拟内存占用的地址空间,通常是两段连续的空间。**而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。

多级页表就像一个多叉树的数据结构,所以我们常常称它为页表树(Page TableTree)。因为虚拟内存地址分布的连续性,树的第一层节点的指针,很多就是空的,也就不需要有对应的子树了。所谓不需要子树,其实就是不需要对应的 2 级、3 级的页表。找到最终的物理页号,就好像通过一个特定的访问路径,走到树最底层的叶子节点。
不过,多级页表虽然节约了我们的存储空间,却带来了时间上的开销,所以它其实是一个“以时间换空间”的策略。原本我们进行一次地址转换,只需要访问一次内存就能找到物理页号,算出物理内存地址。但是,用了 4 级页表,我们就需要访问 4 次内存,才能找到物理页号了。我们在前面两讲讲过,内存访问其实比 Cache 要慢很多。我们本来只是要做一个简单的地址转换,反而是一下子要多访问好多次内存。
TLB和内存保护
机器指令里面的内存地址都是虚拟内存地址。程序里面的每一个进程,都有一个属于自己的虚拟内存地址空间。我们可以通过地址转换来获得最终的实际物理地址。我们每一个指令都存放在内存里面,每一条数据都存放在内存里面。因此,“地址转换”是一个非常高频的动作,“地址转换”的性能就变得至关重要了。这就是我们今天要讲的第一个问题,也就是性能问题。
加速地址转换TLB
程序所需要使用的指令,都顺序存放在虚拟内存里面。我们执行的指令,也是一条条顺序执行下去的。也就是说,我们对于指令地址的访问,存在前面几讲所说的“空间局部性”和“时间局部性”,而需要访问的数据也是一样的。我们连续执行了 5 条指令。因为内存地址都是连续的,所以这 5 条指令通常都在同一个“虚拟页”里。因此,这连续 5 次的内存地址转换,其实都来自于同一个虚拟页号,转换的结果自然也就是同一个物理页号。那我们就可以用前面几讲说过的,用一个“加个缓存”的办法。把之前的内存转换地址缓存下来,使得我们不需要反复去访问内存来进行内存地址转换。

于是,计算机工程师们专门在 CPU 里放了一块缓存芯片。这块缓存芯片我们称之为TLB,全称是地址变换高速缓冲(Translation-Lookaside Buffer)。这块缓存存放了之前已经进行过地址转换的查询结果。这样,当同样的虚拟地址需要进行地址转换的时候,我们可以直接在 TLB 里面查询结果,而不需要多次访问内存来完成一次转换。
TLB 和我们前面讲的 CPU 的高速缓存类似,可以分成指令的 TLB 和数据的 TLB,也就是ITLB和DTLB。同样的,我们也可以根据大小对它进行分级,变成 L1、L2 这样多层的TLB。
除此之外,还有一点和 CPU 里的高速缓存也是一样的,我们需要用脏标记这样的标记位,来实现“写回”这样缓存管理策略。

为了性能,我们整个内存转换过程也要由硬件来执行。在 CPU 芯片里面,我们封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换。和 TLB 的访问和交互,都是由这个 MMU 控制的。
因为我们的指令、数据都存放在内存里面,这里就会遇到我们今天要谈的第二个问题,也就是内存安全问题。如果被人修改了内存里面的内容,我们的 CPU 就可能会去执行我们计划之外的指令。这个指令可能是破坏我们服务器里面的数据,也可能是被人获取到服务器里面的敏感信息。
安全性与内存保护
进程的程序也好,数据也好,都要存放在内存里面。实际程序指令的执行,也是通过程序计数器里面的地址,去读取内存内的内容,然后运行对应的指令,使用相应的数据。
虽然我们现代的操作系统和 CPU,已经做了各种权限的管控。正常情况下,我们已经通过虚拟内存地址和物理内存地址的区分,隔离了各个进程。但是,无论是 CPU 这样的硬件,还是操作系统这样的软件,都太复杂了,难免还是会被黑客们找到各种各样的漏洞。
就像我们在软件开发过程中,常常会有一个“兜底”的错误处理方案一样,在对于内存的管理里面,计算机也有一些最底层的安全保护机制。这些机制统称为内存保护(MemoryProtection)。
可执行空间保护
这个机制是说,我们对于一个进程使用的内存,只把其中的指令部分设置成“可执行”的,对于其他部分,比如数据部分,不给予“可执行”的权限。因为无论是指令,还是数据,在我们的 CPU 看来,都是二进制的数据。我们直接把数据部分拿给 CPU,如果这些数据解码后,也能变成一条合理的指令,其实就是可执行的。
这个时候,黑客们想到了一些搞破坏的办法。我们在程序的数据区里,放入一些要执行的指令编码后的数据,然后找到一个办法,让 CPU 去把它们当成指令去加载,那 CPU 就能执行我们想要执行的指令了。对于进程里内存空间的执行权限进行控制,可以使得 CPU 只能执行指令区域的代码。对于数据区域的内容,即使找到了其他漏洞想要加载成指令来执行,也会因为没有权限而被阻挡掉。
其实,在实际的应用开发中,类似的策略也很常见。我下面给你举个例子。
SQL 注入攻击。如果服务端执行的 SQL 脚本是通过字符串拼装出来的,那么在 Web 请求里面传输的参数就可以藏下一些我们想要执行的 SQL,让服务器执行一些我们没有想到过的 SQL 语句。
地址空间布局随机化
内存层面的安全保护核心策略,是在可能有漏洞的情况下进行安全预防。上面的可执行空间保护就是一个很好的例子。但是,内存层面的漏洞还有其他的可能性。这里的核心问题是,其他的人、进程、程序,会去修改掉特定进程的指令、数据,然后,让当前进程去执行这些指令和数据,造成破坏。要想修改这些指令和数据,我们需要知道这些指令和数据所在的位置才行。
原先我们一个进程的内存布局空间是固定的,所以任何第三方很容易就能知道指令在哪里,程序栈在哪里,数据在哪里,堆又在哪里。这个其实为想要搞破坏的人创造了很大的便利。而地址空间布局随机化这个机制,就是让这些区域的位置不再固定,在内存空间随机去分配这些进程里不同部分所在的内存空间地址,让破坏者猜不出来。猜不出来呢,自然就没法找到想要修改的内容的位置。如果只是随便做点修改,程序只会 crash 掉,而不会去执行计划之外的代码。

举个例子:这样的“随机化”策略,其实也是我们日常应用开发中一个常见的策略。
- 网站和 App 都会需要你设置用户名和密码,之后用来登陆自己的账号。然后,在服务器端,我们会把用户名和密码保存下来,在下一次用户登陆的时候,使用这个用户名和密码验证。我们的密码当然不能明文存储在数据库里,不然就会有安全问题。如果明文存储在数据库里,意味着能拿到数据库访问权限的人,都能看到用户的明文密码。这个可能是因为安全漏洞导致被人拖库,而且网站的管理员也能直接看到所有的用户名和密码信息。
- 于是,大家会在数据库里存储密码的哈希值,比如用现在常用的 SHA256,生成一一个验证的密码哈希值。但是这个往往还是不够的。因为同样的密码,对应的哈希值都是相同的,大部分用户的密码又常常比较简单。但是,拖库成功的黑客可以通过彩虹表的方式,来推测出用户的密码。
- 这个时候,我们的“随机化策略”就可以用上了。我们可以在数据库里,给每一个用户名生成一个随机的、使用了各种特殊字符的盐值(Salt)。这样,我们的哈希值就不再是仅仅使用密码来生成的了,而是密码和盐值放在一起生成的对应的哈希值。哈希值的生成中,包括了一些类似于“乱码”的随机字符串,所以通过彩虹表碰撞来猜出密码的办法就用不了了。
总线:计算机内部的高速公路
CPU 所代表的控制器和运算器,要和存储器,也就是我们的主内存,以及输入和输出设备进行通信。那问题来了,CPU 从我们的键盘、鼠标接收输入信号,向显示器输出信号,这之间究竟是怎么通信的呢?换句话说,计算机是用什么样的方式来完成,CPU 和内存、以及外部输入输出设备的通信呢?
Bus,设计概念
计算机里其实有很多不同的硬件设备,除了 CPU 和内存之外,我们还有大量的输入输出设备。可以说,你计算机上的每一个接口,键盘、鼠标、显示器、硬盘,乃至通过 USB 接口连接的各种外部设备,都对应了一个设备或者模块。
与其让各个设备之间互相单独通信,不如我们去设计一个公用的线路。CPU 想要和什么设备通信,通信的指令是什么,对应的数据是什么,都发送到这个线路上;设备要向 CPU 发送什么信息呢,也发送到这个线路上。这个线路就好像一个高速公路,各个设备和其他设备之间,不需要单独建公路,只建一条小路通向这条高速公路就好了。
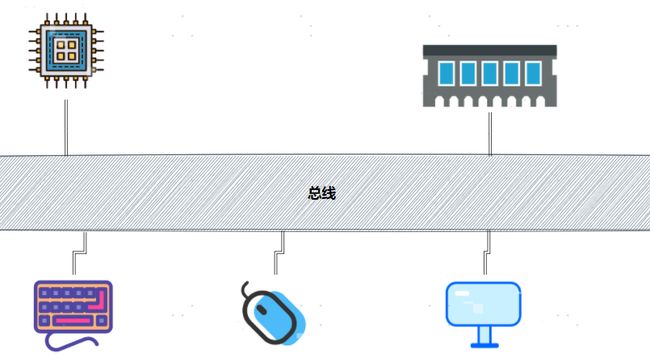
我们的 CPU、内存以及输入和输出设备,都是通过这组线路,进行相互间通信的。总线的英文叫作 Bus,就是一辆公交车。这个名字很好地描述了总线的含义。我们的“公交车”的各个站点,就是各个接入设备。要想向一个设备传输数据,我们只要把数据放上公交车,在对应的车站下车就可以了。
对应的设计思路,在软件开发中也是非常常见的。我们在做大型系统开发的过程中,经常会用到一种叫作事件总线(Event Bus)的设计模式。
在事件总线这个设计模式里,各个模块触发对应的事件,并把事件对象发送到总线上。也就是说,每个模块都是一个发布者(Publisher)。而各个模块也会把自己注册到总线上,去监听总线上的事件,并根据事件的对象类型或者是对象内容,来决定自己是否要进行特定的处理或者响应。

总线类型
首先,CPU 和内存以及高速缓存通信的总线,这里面通常有两种总线。这种方式,我们称之为双独立总线(Dual Independent Bus,缩写为 DIB)。CPU 里,有一个快速的本地总线(Local Bus),以及一个速度相对较慢的前端总线(Front-side Bus)。
我们在前面几讲刚刚讲过,现代的 CPU 里,通常有专门的高速缓存芯片。这里的高速本地总线,就是用来和高速缓存通信的。而前端总线,则是用来和主内存以及输入输出设备通信的。有时候,我们会把本地总线也叫作后端总线(Back-side Bus),和前面的前端总线对应起来。而前端总线也有很多其他名字,比如处理器总线(Processor Bus)、内存总线(Memory Bus)。

事实上,真实的计算机里,这个总线层面拆分得更细。根据不同的设备,还会分成独立的PCI 总线、ISA 总线等等。

在物理层面,其实我们完全可以把总线看作一组“电线”。不过呢,这些电线之间也是有分工的,我们通常有三类线路。
- 数据线,用来传输实际的数据信息,也就是实际上了公交车的“人”。
- 地址线,用来确定到底把数据传输到哪里去,是内存的某个位置,还是某一个 I/O 设备。这个其实就相当于拿了个纸条,写下了上面的人要下车的站点。
- 控制线,用来控制对于总线的访问。虽然我们把总线比喻成了一辆公交车。那么有人想要做公交车的时候,需要告诉公交车司机,这个就是我们的控制信号。
尽管总线减少了设备之间的耦合,也降低了系统设计的复杂度,但同时也带来了一个新问题,那就是总线不能同时给多个设备提供通信功能。
总线是一个各个接入的设备公用的线路,所以自然会在各个设备之间争夺总线所有权的情况。于是,我们需要一个机制来决定让谁来使用总线,这个决策机制就是总线裁决。
2008 年之后,我们的 Intel CPU 其实已经没有前端总线了。Intel 发明了快速通道互联(Intel Quick Path Interconnect,简称为 QPI)技术,替代了传统的前端总线。这个 QPI技术,你可以搜索和翻阅一下相关资料,了解一下它引入了什么新的设计理念。
输入输出设备I/O
像蓝牙、WiFi 无线网卡这样的设备也是输入输出设备吗?我们的输入输出设备的寄存器在哪里?到底是在主板上,还是在硬件设备上?
IO的构成
输入输出设备,并不只是一个设备。大部分的输入输出设备,都有两个组成部分。第一个是它的接口(Interface),第二个才是实际的 I/O 设备(Actual I/O Device)。我们的硬件设备并不是直接接入到总线上和 CPU 通信的,而是通过接口,用接口连接到总线上,再通过总线和 CPU 通信。

你平时听说的并行接口(Parallel Interface)、串行接口(Serial Interface)、USB 接口,都是计算机主板上内置的各个接口。我们的实际硬件设备,比如,使用并口的打印机、使用串口的老式鼠标或者使用 USB 接口的 U 盘,都要插入到这些接口上,才能和 CPU 工作以及通信的。
接口本身就是一块电路板。CPU 其实不是和实际的硬件设备打交道,而是和这个接口电路板打交道。我们平时说的,设备里面有三类寄存器,其实都在这个设备的接口电路上,而不在实际的设备上。
那这三类寄存器是哪三类寄存器呢?它们分别是状态寄存器(Status Register)、 命令寄存器(Command Register)以及数据寄存器(Data Register)。
除了内置在主板上的接口之外,有些接口可以集成在设备上。
如果你用的是 Windows 操作系统,你可以打开设备管理器,里面有各种各种的Devices(设备)、Controllers(控制器)、Adaptors(适配器)。这些,其实都是对于输入输出设备不同角度的描述。被叫作 Devices,看重的是实际的 I/O 设备本身。被叫作Controllers,看重的是输入输出设备接口里面的控制电路。而被叫作 Adaptors,则是看重接口作为一个适配器后面可以插上不同的实际设备。
CPU是如何控制IO的
无论是内置在主板上的接口,还是集成在设备上的接口,除了三类寄存器之外,还有对应的控制电路。正是通过这个控制电路,CPU 才能通过向这个接口电路板传输信号,来控制实际的硬件。我们先来看一看,硬件设备上的这些寄存器有什么用。这里,我拿我们平时用的打印机作为例子。

- 首先是数据寄存器(Data Register)。CPU 向 I/O 设备写入需要传输的数据,比如要打印的内容是“GeekTime”,我们就要先发送一个“G”给到对应的 I/O 设备。
- 然后是命令寄存器(Command Register)。CPU 发送一个命令,告诉打印机,要进行打印工作。这个时候,打印机里面的控制电路会做两个动作。第一个,是去设置我们的状态寄存器里面的状态,把状态设置成 not-ready。第二个,就是实际操作打印机进行打印。
- 而状态寄存器(Status Register),就是告诉了我们的 CPU,现在设备已经在工作了,所以这个时候,CPU 你再发送数据或者命令过来,都是没有用的。直到前面的动作已经完成,状态寄存器重新变成了 ready 状态,我们的 CPU 才能发送下一个字符和命令。
当然,在实际情况中,打印机里通常不只有数据寄存器,还会有数据缓冲区。我们的 CPU也不是真的一个字符一个字符这样交给打印机去打印的,而是一次性把整个文档传输到打印机的内存或者数据缓冲区里面一起打印的。
信号和地址
搞清楚了实际的 I/O 设备和接口之间的关系,一个新的问题就来了。那就是,我们的 CPU到底要往总线上发送一个什么样的命令,才能和 I/O 接口上的设备通信呢?
和访问我们的主内存一样,使用“内存地址”。为了让已经足够复杂的 CPU 尽可能简单,计算机会把 I/O 设备的各个寄存器,以及 I/O 设备内部的内存地址,都映射到主内存地址空间里来。主内存的地址空间里,会给不同的 I/O 设备预留一段一段的内存地址。CPU 想要和这些 I/O 设备通信的时候呢,就往这些地址发送数据。这些地址信息,就是通过上一讲的地址线来发送的,而对应的数据信息呢,自然就是通过数据线来发送的了。
而我们的 I/O 设备呢,就会监控地址线,并且在 CPU 往自己地址发送数据的时候,把对应的数据线里面传输过来的数据,接入到对应的设备里面的寄存器和内存里面来。CPU 无论是向 I/O 设备发送命令、查询状态还是传输数据,都可以通过这样的方式。这种方式呢,叫作内存映射IO(Memory-Mapped I/O,简称 MMIO)。
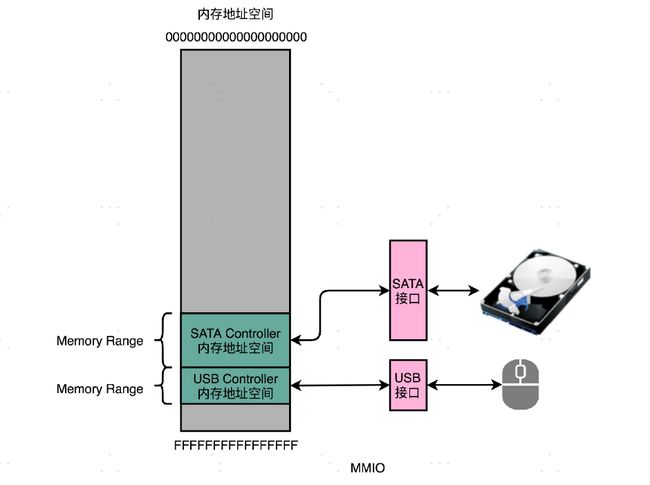
MMIO 是不是唯一一种 CPU 和设备通信的方式呢?答案是否定的。精简指令集MIPS 的 CPU 特别简单,所以这里只有 MMIO。而我们有 2000 多个指令的 Intel X86 架构的计算机,自然可以设计专门的和 I/O 设备通信的指令,也就是 in 和 out 指令。
Intel CPU 虽然也支持 MMIO,不过它还可以通过特定的指令,来支持端口映射I/O(Port-Mapped I/O,简称 PMIO)或者也可以叫独立输入输出(Isolated I/O)。其实 PMIO 的通信方式和 MMIO 差不多,核心的区别在于,PMIO 里面访问的设备地址,不再是在内存地址空间里面,而是一个专门的端口(Port)。这个端口并不是指一个硬件上的插口,而是和 CPU 通信的一个抽象概念。
无论是 PMIO 还是 MMIO,CPU 都会传送一条二进制的数据,给到 I/O 设备的对应地址。设备自己本身的接口电路,再去解码这个数据。解码之后的数据呢,就会变成设备支持的一条指令,再去通过控制电路去操作实际的硬件设备。对于 CPU 来说,它并不需要关心设备本身能够支持哪些操作。它要做的,只是在总线上传输一条条数据就好了。这个,其实也有点像我们在设计模式里面的 Command 模式。我们在总线上传输的,是一个个数据对象,然后各个接受这些对象的设备,再去根据对象内容,进行实际的解码和命令执行。
磁盘IO的性能
如果去看硬盘厂商的性能报告,通常你会看到两个指标。一个是响应时间(ResponseTime),另一个叫作数据传输率(Data Transfer Rate)。
我们现在常用的硬盘有两种。一种是 HDD 硬盘,也就是我们常说的机械硬盘。另一种是SSD 硬盘,一般也被叫作固态硬盘。现在的 HDD 硬盘,用的是 SATA 3.0 的接口。而SSD 硬盘呢,通常会用两种接口,一部分用的也是 SATA 3.0 的接口;另一部分呢,用的是 PCI Express 的接口。
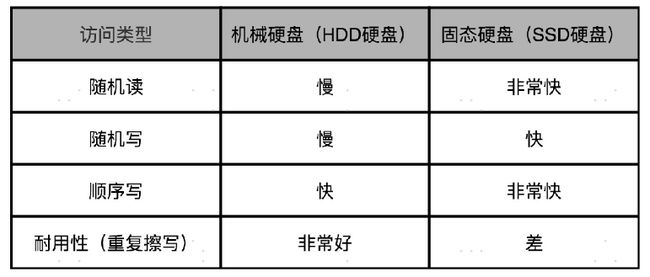
在顺序读取的情况下,无论是 HDD 硬盘还是 SSD 硬盘,性能看起来都是很不错的。不过,等到进行随机读取测试的时候,硬盘的性能才能见了真章。因为在大部分的应用开发场景下,我们关心的并不是在顺序读写下的数据量,而是每秒钟能够进行输入输出的操作次数,也就是 IOPS 这个核心性能指标。
你会发现,即使是使用 PCI Express 接口的 SSD 硬盘,IOPS 也就只是到了 2 万左右。这个性能,和我们 CPU 的每秒 20 亿次操作的能力比起来,可就差得远了。所以很多时候,我们的程序对外响应慢,其实都是 CPU 在等待 I/O 操作完成。
在 Linux 下,我们可以通过 top 这样的命令,来看整个服务器的整体负载。在应用响应慢的时候,我们可以先通过这个指令,来看 CPU 是否在等待 I/O 完成自己的操作。进一步地,我们可以通过 iostat 这个命令,来看到各个硬盘这个时候的读写情况。而 iotop 这个命令,能够帮助我们定位到到底是哪一个进程在进行大量的 I/O 操作。
硬盘
机械硬盘(HDD)

无论是作为个人电脑的数据盘,还是在数据中心里面用作海量数据的存储,机械硬盘仍然在被大量使用。不仅如此,随着成本的不断下降,机械硬盘还替代掉了很多传统的存储设备,比如,以前常常用来备份冷数据的磁带。
物理构造
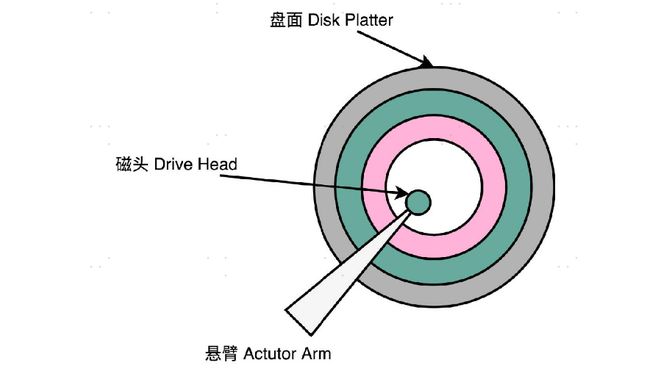
**盘面:**盘面其实就是我们实际存储数据的盘片。如果你剪开过软盘的外壳,或者看过光盘 DVD,那你看到盘面应该很熟悉。盘面其实和它们长得差不多。盘面本身通常是用的铝、玻璃或者陶瓷这样的材质做成的光滑盘片。然后,盘面上有一层磁性的涂层。我们的数据就存储在这个磁性的涂层上。盘面中间有一个受电机控制的转轴。这个转轴会控制我们的盘面去旋转。
我们平时买硬盘的时候经常会听到一个指标,叫作这个硬盘的转速。我们的硬盘有 5400 转的、7200 转的,乃至 10000 转的。这个多少多少转,指的就是盘面中间电机控制的转轴的旋转速度,英文单位叫RPM,也就是每分钟的旋转圈数(Rotations Per Minute)。所谓 7200 转,其实更准确地说是 7200RPM,指的就是一旦电脑开机供电之后,我们的硬盘就可以一直做到每分钟转上 7200 圈。如果折算到每一秒钟,就是 120 圈。
磁头: 我们的数据并不能直接从盘面传输到总线上,而是通过磁头,从盘面上读取到,然后再通过电路信号传输给控制电路、接口,再到总
**线上的。**通常,我们的一个盘面上会有两个磁头,分别在盘面的正反面。盘面在正反两面都有对应的磁性涂层来存储数据,而且一块硬盘也不是只有一个盘面,而是上下堆叠了很多个盘面,各个盘面之间是平行的。每个盘面的正反两面都有对应的磁头。
**悬臂:悬臂链接在磁头上,并且在一定范围内会去把磁头定位到盘面的某个特定的磁道(Track)**上。
固态硬盘(SSD)
千万不要使用碎片整理的功能!!!

一块普通的 SSD 硬盘,可以轻松支撑 10000 乃至 20000 的 IOPS。但是如果我们需要频繁地重复写入删除数据,那么机械硬盘要比 SSD 性价比高很多。
要想知道为什么 SSD 的耐用性不太好,我们先要理解 SSD 硬盘的存储和读写原理。
我们之前说过,CPU Cache 用的 SRAM 是用一个电容来存放一个比特的数据。对于 SSD 硬盘,我们也可以先简单地认为,它是由一个电容加上一个电压计组合在一起,记录了一个或者多个比特。
SLC、MLC、TLC 和 QLC
能够记录一个比特很容易理解。给电容里面充上电有电压的时候就是 1,给电容放电里面没有电就是 0。采用这样方式存储数据的 SSD 硬盘,我们一般称之为使用了 SLC 的颗粒,全称是 Single-Level Cell,也就是一个存储单元中只有一位数据。
但是,这样的方式会遇到和 CPU Cache 类似的问题,那就是,同样的面积下,能够存放下的元器件是有限的。如果只用 SLC,我们就会遇到,存储容量上不去,并且价格下不来的问题。于是呢,硬件工程师们就陆续发明了MLC(Multi-Level Cell)、TLC(Triple-Level Cell)以及QLC(Quad-Level Cell),也就是能在一个电容里面存下 2 个、3 个乃至 4 个比特。
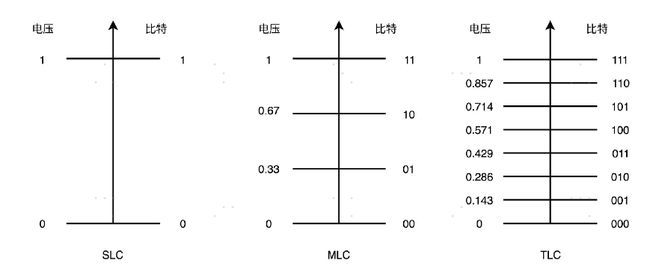
只有一个电容,我们怎么能够表示更多的比特呢?别忘了,这里我们还有一个电压计。4 个比特一共可以从 0000-1111 表示 16 个不同的数。那么,如果我们能往电容里面充电的时候,充上 15 个不同的电压,并且我们电压计能够区分出这 15 个不同的电压。加上电容被放空代表的 0,就能够代表从 0000-1111 这样 4 个比特了。
P/E擦写问题
如果我们去看一看 SSD 硬盘的硬件构造,可以看到,它大概是自顶向下是这么构成的。
SSD的构成:
- 接口和控制电路,在控制电路里,有一个很重要的模块,叫作FTL(Flash-Translation Layer),也就是闪存转换层。这个可以说是 SSD 硬盘的一个核心模块,SSD硬盘性能的好坏,很大程度上也取决于 FTL 的算法好不好。
- 实际I/O设备,它其实和机械硬盘很像。现在新的大容量 SSD 硬盘都是 3D 封装的了,也就是说,是由很多个裸片(Die)叠在一起的,就好像我们的机械硬盘把很多个盘面(Platter)叠放再一起一样,这样可以在同样的空间下放下更多的容量。
一张裸片上可以放多个平面(Plane),一般一个平面上的存储容量大概在 GB 级别。一个平面上面,会划分成很多个块(Block),一般一个块(Block)的存储大小, 通常几百 KB 到几 MB 大小。一个块里面,还会区分很多个页(Page),就和我们内存里面的页一样,一个页的大小通常是 4KB。
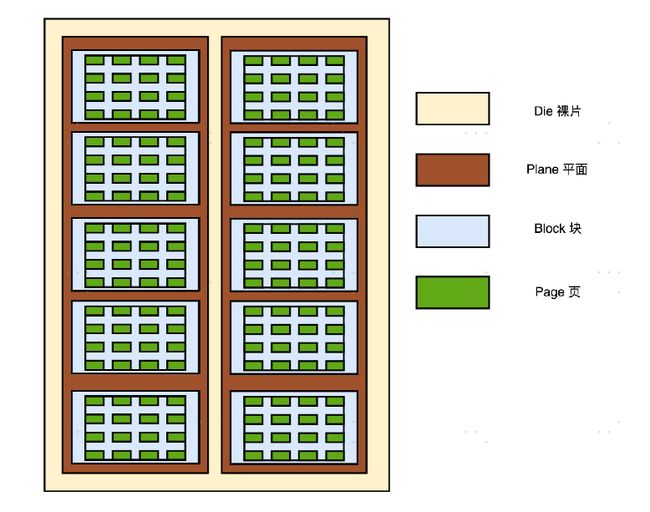
在这一层一层的结构里面,处在最下面的两层块和页非常重要。对于 SSD 硬盘来说,数据的写入叫作 Program。写入不能像机械硬盘一样,通过覆写(Overwrite)来进行的,而是要先去擦除(Erase),然后再写入。SSD 的读取和写入的基本单位,不是一个比特(bit)或者一个字节(byte),而是一个页(Page)。SSD 的擦除单位就更夸张了,我们不仅不能按照比特或者字节来擦除,连按照页来擦除都不行,我们必须按照块来擦除。
SSD 的使用寿命,其实是每一个块(Block)的擦除的次数。
你可以把 SSD 硬盘的一个平面看成是一张白纸。我们在上面写入数据,就好像用铅笔在白纸上写字。如果想要把已经写过字的地方写入新的数据,我们先要用橡皮把已经写好的字擦掉。但是,如果频繁擦同一个地方,那这个地方就会破掉,之后就没有办法再写字了
我们上面说的 SLC 的芯片,可以擦除的次数大概在 10 万次,MLC 就在 1 万次左右,而TLC 和 QLC 就只在几千次了。这也是为什么,你去购买 SSD 硬盘,会看到同样的容量的价格差别很大,因为它们的芯片颗粒和寿命完全不一样。
SSD 读写的生命周期
下面我们来实际看一看,一块 SSD 硬盘在日常是怎么被用起来的。
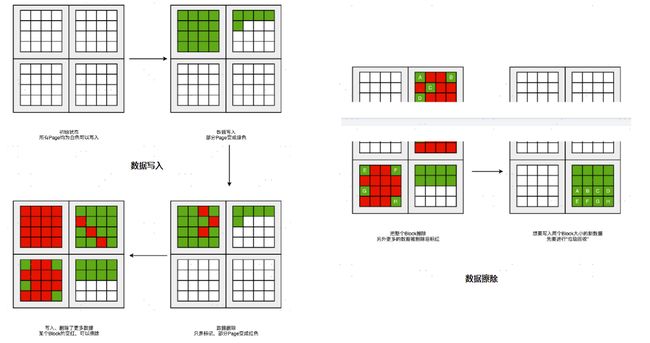
- 一开始,所有块的每一个页都是白色的。随着我们开始往里面写数据,里面的有些页就变成了绿色。
- 因为我们删除了硬盘上的一些文件,所以有些页变成了红色。但是这些红色的页,并不能再次写入数据。因为 SSD 硬盘不能单独擦除一个页,必须一次性擦除整个块,所以新的数据,我们只能往后面的白色的页里面写。这些散落在各个绿色空间里面的红色空洞,就好像硬盘碎片。
- 如果有哪一个块的数据一次性全部被标红了,那我们就可以把整个块进行擦除。它就又会变成白色,可以重新一页一页往里面写数据。
- 随着硬盘里面的数据越来越多,红色空洞占的地方也会越来越多。于是,你会发现,我们就要没有白色的空页去写入数据了。这个时候,我们要做一次类似于 Windows 里面“磁盘碎片整理”或者 Java 里面的“内存垃圾回收”工作。
- 不过,这个“磁盘碎片整理”或者“内存垃圾回收”的工作,我们不能太主动、太频繁地去做。因为 SSD 的擦除次数是有限的。如果动不动就搞个磁盘碎片整理,那么我们的 SSD硬盘很快就会报废了。
这是不是说,我们的 SSD 硬盘的容量是用不满的?因为我们总会遇到一些红色空洞?
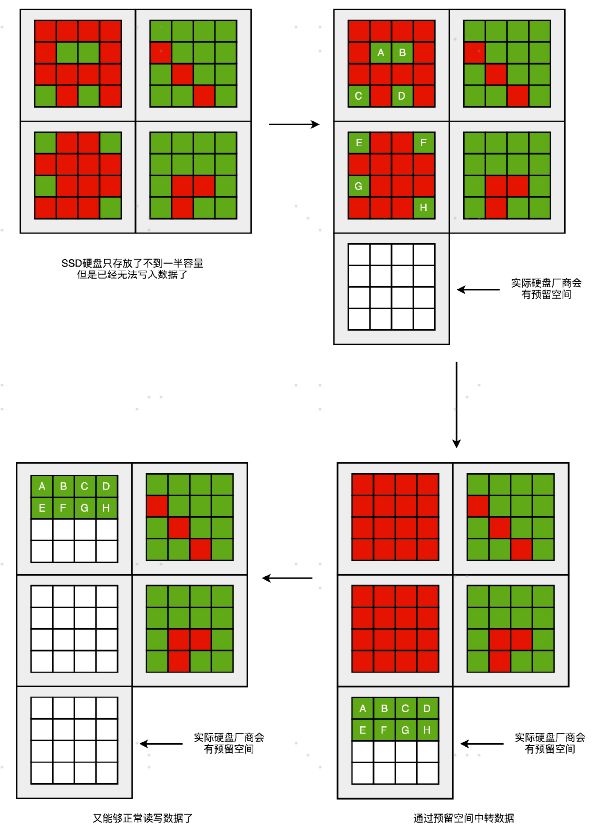
没错,一块 SSD 的硬盘容量,是没办法完全用满的。不过,为了不得罪消费者,生产 SSD硬盘的厂商,其实是预留了一部分空间,专门用来做这个“磁盘碎片整理”工作的。一块标成 240G 的 SSD 硬盘,往往实际有 256G 的硬盘空间。SSD 硬盘通过我们的控制芯片电路,把多出来的硬盘空间,用来进行各种数据的闪转腾挪,让你能够写满那 240G 的空间。这个多出来的 16G 空间,叫作预留空间(Over Provisioning),一般 SSD 的硬盘的预留空间都在 7%-15% 左右。
**实战总结:**你会发现 SSD 硬盘,特别适合读多写少的应用。
在日常应用里面:
-
我们的系统盘适合用 SSD。
-
但是,如果我们用 SSD 做专门的下载盘,一直下载各种影音数据,然后刻盘备份就不太好了,特别是现在 QLC 颗粒的 SSD,它只有几千次可擦写的寿命啊。
在数据中心里面:SSD 的应用场景也是适合读多写少的场景。
- 我们拿 SSD 硬盘用来做数据库,存放电商网站的商品信息很合适。
- 但是,用来作为 Hadoop 这样的 Map-Reduce 应用的数据盘就不行了。因为 Map-Reduce 任务会大量在任务中间向硬盘写入中间数据再删除掉,这样用不了多久,SSD 硬盘的寿命就会到了。
为什么SSD硬盘不建议使用碎片整理
一旦主动去运行磁盘碎片整理功能,就会发生一次块的擦除,对应块的寿命就少了一点点。这个 SSD 的擦除寿命的问题,不仅会影响像磁盘碎片整理这样的功能,其实也很影响我们的日常使用。
我们的操作系统上,并没有 SSD 硬盘上各个块目前已经擦写的情况和寿命,所以它对待SSD 硬盘和普通的机械硬盘没有什么区别。
我们日常使用 PC 进行软件开发的时候,会先在硬盘上装上操作系统和常用软件,比如Office,或者工程师们会装上 VS Code、IDEA 这样的集成开发环境。这些软件所在的块,写入一次之后,就不太会擦除了,所以就只有读的需求。一旦开始开发,我们就会不断添加新的代码文件,还会不断修改已经有的代码文件。因为SSD 硬盘没有覆写(Override)的功能,所以,这个过程中,其实我们是在反复地写入新的文件,然后再把原来的文件标记成逻辑上删除的状态。等 SSD 里面空的块少了,我们会用“垃圾回收”的方式,进行擦除。这样,我们的擦除会反复发生在这些用来存放数据的地方。

有一天,这些块的擦除次数到了,变成了坏块。但是,我们安装操作系统和软件的地方还没有坏,而这块硬盘的可以用的容量却变小了。
磨损均衡(FTL)、TRIM 和写入放大效应
那么,我们有没有什么办法,不让这些坏块那么早就出现呢?我们能不能,匀出一些存放操作系统的块的擦写次数,给到这些存放数据的地方呢?
相信你一定想到了,其实我们要的就是想一个办法,让 SSD 硬盘各个块的擦除次数,均匀分摊到各个块上。这个策略呢,就叫作磨损均衡(Wear-Leveling)。实现这个技术的核心办法,和我们前面讲过的虚拟内存一样,就是添加一个间接层。这个间接层,就是 FTL 这个闪存转换层。
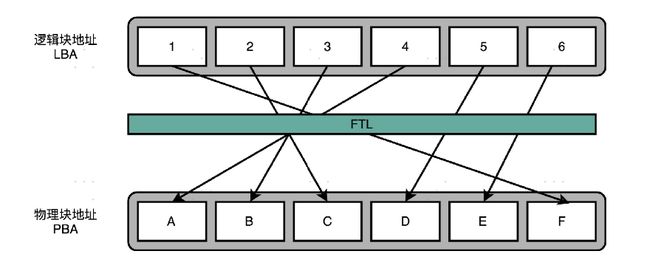
就像在管理内存的时候,我们通过一个页表映射虚拟内存页和物理页一样,在 FTL 里面,存放了逻辑块地址(Logical Block Address,简称 LBA)到物理块地址(Physical BlockAddress,简称 PBA)的映射。
**操作系统访问的硬盘地址,其实都是逻辑地址。**只有通过 FTL 转换之后,才会变成实际的物理地址,找到对应的块进行访问。操作系统本身,不需要去考虑块的磨损程度,只要和操作机械硬盘一样来读写数据就好了。
操作系统所有对于 SSD 硬盘的读写请求,都要经过 FTL。FTL 里面又有逻辑块对应的物理块,所以 FTL 能够记录下来,每个物理块被擦写的次数。如果一个物理块被擦写的次数多了,FTL 就可以将这个物理块,挪到一个擦写次数少的物理块上。但是,逻辑块不用变,操作系统也不需要知道这个变化。
这也是我们在设计大型系统中的一个典型思路,也就是各层之间是隔离的,操作系统不需要考虑底层的硬件是什么,完全交由硬件的控制电路里面的 FTL,来管理对于实际物理硬件的写入。
TRIM 指令的支持
不过,操作系统不去关心实际底层的硬件是什么,在 SSD 硬盘的使用上,也会带来一个问题。这个问题就是,操作系统的逻辑层和 SSD 的逻辑层里的块状态,是不匹配的。
我们在操作系统里面去删除一个文件,其实并没有真的在物理层面去删除这个文件,只是在文件系统里面,把对应的 inode 里面的元信息清理掉,这代表这个 inode 还可以继续使用,可以写入新的数据。这个时候,实际物理层面的对应的存储空间,在操作系统里面被标记成可以写入了。
所以,其实我们日常的文件删除,都只是一个操作系统层面的逻辑删除。这也是为什么,很多时候我们不小心删除了对应的文件,我们可以通过各种恢复软件,把数据找回来。同样的,这也是为什么,如果我们想要删除干净数据,需要用各种“文件粉碎”的功能才行。
这个删除的逻辑在机械硬盘层面没有问题,因为文件被标记成可以写入,后续的写入可以直接覆写这个位置。但是,在 SSD 硬盘上就不一样了。我在这里放了一张详细的示意图。
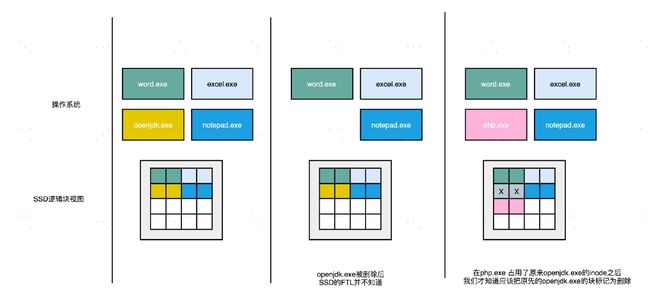
所以,在使用 SSD 的硬盘情况下,你会发现,操作系统对于文件的删除,SSD 硬盘其实并不知道。这就导致,我们为了磨损均衡,很多时候在都在搬运很多已经删除了的数据。这就会产生很多不必要的数据读写和擦除,既消耗了 SSD 的性能,也缩短了 SSD 的使用寿命。
为了解决这个问题,现在的操作系统和 SSD 的主控芯片,都支持TRIM 命令。这个命令可以在文件被删除的时候,让操作系统去通知 SSD 硬盘,对应的逻辑块已经标记成已删除了。现在的 SSD 硬盘都已经支持了 TRIM 命令。无论是 Linux、Windows 还是 MacOS,这些操作系统也都已经支持了 TRIM 命令了。
当 SSD 硬盘的存储空间被占用得越来越多,每一次写入新数据,我们都可能没有足够的空白。我们可能不得不去进行垃圾回收,合并一些块里面的页,然后再擦除掉一些页,才能匀出一些空间来。这个时候,从应用层或者操作系统层面来看,我们可能只是写入了一个 4KB 或者 4MB 的数据。但是,实际通过 FTL 之后,我们可能要去搬运 8MB、16MB 甚至更多的数据。我们通过**“实际的闪存写入的数据量 / 系统通过 FTL 写入的数据量 = 写入放大”**,可以得到,写入放大的倍数越多,意味着实际的 SSD 性能也就越差,会远远比不上实际 SSD 硬盘标称的指标。而解决写入放大,需要我们在后台定时进行垃圾回收,在硬盘比较空闲的时候,就把搬运数据、擦除数据、留出空白的块的工作做完,而不是等实际数据写入的时候,再进行这样的操作。
AeroSpike这是一个专门为SSD设计的key-value数据库,可以了解一下。
DMA
过去几年里,整个计算机产业届,都在尝试不停地提升 I/O 设备的速度。把 HDD 硬盘换成 SSD 硬盘,我们仍然觉得不够快;用 PCI Express 接口的 SSD 硬盘替代 SATA 接口的SSD 硬盘,我们还是觉得不够快,所以,现在就有了傲腾(Optane)这样的技术。但是,无论 I/O 速度如何提升,比起 CPU,总还是太慢。SSD 硬盘的 IOPS 可以到 2 万、4 万,但是我们 CPU 的主频有 2GHz 以上,也就意味着每秒会有 20 亿次的操作。如我们对于 I/O 的操作,都是由 CPU 发出对应的指令,然后等待 I/O 设备完成操作之后返回,那 CPU 有大量的时间其实都是在等待 I/O 设备完成操作。但是,这个 CPU 的等待,在很多时候,其实并没有太多的实际意义。我们对于 I/O 设备的大量操作,其实都只是把内存里面的数据,传输到 I/O 设备而已。在这种情况下,其实CPU 只是在傻等而已。特别是当传输的数据量比较大的时候,比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。
因此,计算机工程师们,就发明了 DMA 技术,也就是直接内存访问(Direct MemoryAccess)技术,来减少 CPU 等待的时间。
理解DMA,一个协处理器
其实 DMA 技术很容易理解,本质上,DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
DMAC 最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用 CPU 来搬运的话,肯定忙不过来,所以可以选择 DMAC。而当数据传输很慢的时候,DMAC 可以等数据到齐了,再发送信号,给到 CPU 去处理,而不是让 CPU 在那里忙等待。
这里面的“**协”**字。DMAC 是在“协助”CPU,完成对应的数据传输工作。在DMAC 控制数据传输的过程中,我们还是需要 CPU 的。
除此之外,DMAC 其实也是一个特殊的 I/O 设备,它和 CPU 以及其他 I/O 设备一样,通过连接到总线来进行实际的数据传输。总线上的设备呢,其实有两种类型。一种我们称之为主设备(Master),另外一种,我们称之为从设备(Slave)。
**想要主动发起数据传输,必须要是一个主设备才可以,CPU 就是主设备。**而我们从设备(比如硬盘)只能接受数据传输。所以,如果通过 CPU 来传输数据,要么是 CPU 从 I/O设备读数据,要么是 CPU 向 I/O 设备写数据。
**我们的 I/O 设备不能向主设备发起请求么?**可以是可以,不过这个发送的不是数据内容,而是控制信号。I/O 设备可以告诉 CPU,我这里有数据要传输给你,但是实际数据是 CPU 从拉走的,而不是 I/O 设备推给 CPU 的。
DMAC ,它既是一个主设备,又是一个从设备。对于 CPU 来说,它是一个从设备;对于硬盘这样的 IO 设备来说呢,它又变成了一个主设备。那使用 DMAC进行数据传输的过程究竟是什么样的呢?下面我们来具体看看。

- 首先,CPU 还是作为一个主设备,向 DMAC 设备发起请求。这个请求,其实就是在DMAC 里面修改配置寄存器。
- CPU 修改 DMAC 的配置的时候,会告诉 DMAC 这样几个信息:
- 源地址的初始值以及传输时候的地址增减方式。
- 目标地址初始值和传输时候的地址增减方式。
- 要传输的数据长度
- 设置完这些信息之后,DMAC 就会变成一个空闲的状态(Idle)。
- 如果我们要从硬盘上往内存里面加载数据,这个时候,硬盘就会向 DMAC 发起一个数据传输请求。这个请求并不是通过总线,而是通过一个额外的连线。
- 然后,我们的 DMAC 需要再通过一个额外的连线响应这个申请。
- 于是,DMAC 这个芯片,就向硬盘的接口发起要总线读的传输请求。数据就从硬盘里面,读到了 DMAC 的控制器里面。
- 然后,DMAC 再向我们的内存发起总线写的数据传输请求,把数据写入到内存里面。
- DMAC 会反复进行上面第 6、7 步的操作,直到 DMAC 的寄存器里面设置的数据长度传输完成。
- 数据传输完成之后,DMAC 重新回到第 3 步的空闲状态。
所以,整个数据传输的过程中,我们不是通过 CPU 来搬运数据,而是由 DMAC 这个芯片来搬运数据。但是 CPU 在这个过程中也是必不可少的。因为传输什么数据,从哪里传输到哪里,其实还是由 CPU 来设置的。这也是为什么,DMAC 被叫作**“协处理器”**。
今天,各种 I/O 设备越来越多,数据传输的需求越来越复杂,使用的场景各不相同。加之显示器、网卡、硬盘对于数据传输的需求都不一样,所以各个设备里面都有自己的 DMAC 芯片了。

开发中的问题
为什么Kafka这么快?
Kafka很好的利用了DMA的数据传输方式,通过DMA的方式实现了非常大的性能提升。
Kafka 是一个用来处理实时数据的管道,我们常常用它来做一个消息队列,或者用来收集和落地海量的日志。作为一个处理实时数据和日志的管道,瓶颈自然也在 I/O 层面。
Kafka 里面会有两种常见的海量数据传输的情况。一种是从网络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失。另一种情况呢,则是从本地磁盘上读取出来,通过网络发送出去。
从本地磁盘上读取出来,通过网络发送出去:
从磁盘读数据发送到网络上去。如果我们自己写一个简单的程序,最直观的办法,自然是用一个文件读操作,从磁盘上把数据读到内存里面来,然后再用一个 Socket,把这些数据发送到网络上去。
在这个过程中,数据一共发生了四次传输的过程。其中两次是 DMA 的传输,另外两次,则是通过 CPU 控制的传输。下面我们来具体看看这个过程。
- 从硬盘上,读到操作系统内核的缓冲区里。这个传输是通过 DMA 搬运的。
- 需要从内核缓冲区里面的数据,复制到我们应用分配的内存里面。这个传输是通过 CPU 搬运的。
- 要从我们应用的内存里面,再写到操作系统的 Socket 的缓冲区里面去。这个传输,还是由 CPU 搬运的。
- 最后一次传输,需要再从 Socket 的缓冲区里面,写到网卡的缓冲区里面去。这个传输又是通过 DMA 搬运的。

我们只是要“搬运”一份数据,结果却整整搬运了四次。而且这里面,从内核的读缓冲区传输到应用的内存里,再从应用的内存里传输到Socket 的缓冲区里,其实都是把同一份数据在内存里面搬运来搬运去,特别没有效率。我们就需要尽可能地减少数据搬运的需求。
事实上,Kafka 做的事情就是,把这个数据搬运的次数,从上面的四次,变成了两次,并且只有 DMA 来进行数据搬运,而不需要 CPU。
如果你层层追踪 Kafka 的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法
Kafka 的代码调用了 Java NIO 库,具体是 FileChannel 里面的 transferTo 方法。我们的数据并没有读到中间的应用内存里面,而是直接通过 Channel,写入到对应的网络设备里。并且,对于 Socket 的操作,也不是写入到 Socket 的 Buffer 里面,而是直接根据描述符(Descriptor)写入到网卡的缓冲区里面。于是,在这个过程之中,我们只进行了两次数据传输。

并且没有通过 CPU 来进行数据搬运,所有的数据都是通过 DMA 来进行传输的。在这个方法里面,我们没有在内存层面去“复制(Copy)”数据,所以这个方法,也被称之为零拷贝(Zero-Copy)。