Seaborn系列(三):分布统计绘图(distribution)
Seaborn系列目录
文章目录
- 1. 分布统计绘图API概述
- 2. displot单变量分布图(直方图、核密度、累积分布)
-
- 2.1 displot函数绘制单变量分布图
- 2.2 displot直方图kde图同时叠加绘制
- 2.3 displot绘图同时叠加rug图
- 2.4 displot双变量分布图(直方图、核密度)
- 2.5 displot分组统计绘图
- 2.6 displot绘制多个子图
- 3 displot、histplot直方图详解
-
- 3.1 直方图基本参数设置
-
- 3.1.1 横向直方图
- 3.1.2 直方柱数量
- 3.1.3 直方图样式
- 3.2 直方图统计方式
- 3.3 分组直方图样式
- 4 displot、kdeplot核分布图详解
-
- 4.1 kde平滑参数
- 4.2 kde分组绘图
- 4.3 双参数kde绘图
- 4.4 kde样式
- 5 ecdfplot,displot绘制累积分布图
-
- 5.1 ecdf图基本方法
- 5.2 互补ecdf
- 6 rugplot绘制累积分布图
-
- 6.1 rug图绘制方法
- 6.2 改变rug短线长度
- 6.3 rug图嵌入其他图形
分布分析(了解变量的分布)是数据分析和建模非常重要且必要的步骤,也是统计学中最基本的方法。
1. 分布统计绘图API概述
分布就是了解数据变量的分布规律的。seaborn中“分布”绘图函数共5个:
displot():通过kind参数指定为"hist",“kde”,“ecdf”。默认为hist。histplot():直方图kdeplot():核密度分布ecdfplot():累积分布rugplot():地毯图(用短线密度表示分布)。rugplot可以在其他图形(hist,kde,ecdf)中显示。
- displot函数为figure级函数,返回FacetGrid对象,类似于figure。
- histplot, kdeplot, ecdfplot和rugplot函数为axes级函数,返回axes对象。
- 注意rugplot函数和另外几个函数有一点不太相同。displot的kind参数不支持rug,但是displot函数有个rug参数,可以在其他图绘制的时候同时绘制rug图。
figure级函数与axes级函数区别见Seaborn系列(一):绘图基础、函数分类、长短数据类型支持
2. displot单变量分布图(直方图、核密度、累积分布)
sns.displot(x=None,y=None,data=None,kind="hist"):根据kind绘制分布图。
常用参数简介:displot函数同样可以用数组、字典和DataFrame作为数据。
- data参数:data为类字典数据或DataFrame。数组为参数时不需要指定data。
- x,y参数:只指定x时,表示统计单变量x的分布。x,y都指定时表示双变量分布。
- kind参数:绘图类型。“hist”:直方图,"kde"核密度图,"ecdf"累积分布图。
分组聚合参数
- hue参数:用不同颜色对数组分组。hue可以是列表或者data的key。hue的每一个数据绘制一组分布图,给一个图例标签。
- row,col:把row,col指定的数据按照行或列排列到不同的子图。
- palette参数:指定hue分组的每组曲线的颜色。
legend、height、aspect参数与relplot类似
- legend参数:图例显示方式。False不现实图例。brief则hue和size的分组都取等间距样本作为图例。full则把分组内所有数值都显示为图例。auto则自动选择brief或full。
- height参数:每个子图的高度(单位inch)
- aspect参数:宽度=aspect×高度
以企鹅penguins数据集为例。(由物种、岛、鸟嘴长度、鸟嘴宽度、鳍足长度、体重、性别组成。)
>>> penguins=sns.load_dataset("penguins")
>>> penguins
species island bill_length_mm ... flipper_length_mm body_mass_g sex
0 Adelie Torgersen 39.1 ... 181.0 3750.0 Male
1 Adelie Torgersen 39.5 ... 186.0 3800.0 Female
2 Adelie Torgersen 40.3 ... 195.0 3250.0 Female
3 Adelie Torgersen NaN ... NaN NaN NaN
4 Adelie Torgersen 36.7 ... 193.0 3450.0 Female
.. ... ... ... ... ... ... ...
339 Gentoo Biscoe NaN ... NaN NaN NaN
340 Gentoo Biscoe 46.8 ... 215.0 4850.0 Female
341 Gentoo Biscoe 50.4 ... 222.0 5750.0 Male
342 Gentoo Biscoe 45.2 ... 212.0 5200.0 Female
343 Gentoo Biscoe 49.9 ... 213.0 5400.0 Male
[344 rows x 7 columns]
2.1 displot函数绘制单变量分布图
import matplotlib.pyplot as plt
import seaborn as sns
penguins=sns.load_dataset('penguins')
sns.displot(data=penguins,x="bill_length_mm")
sns.displot(data=penguins,x="bill_length_mm",kind='kde')
sns.displot(data=penguins,x="bill_length_mm",kind='ecdf')
plt.show()
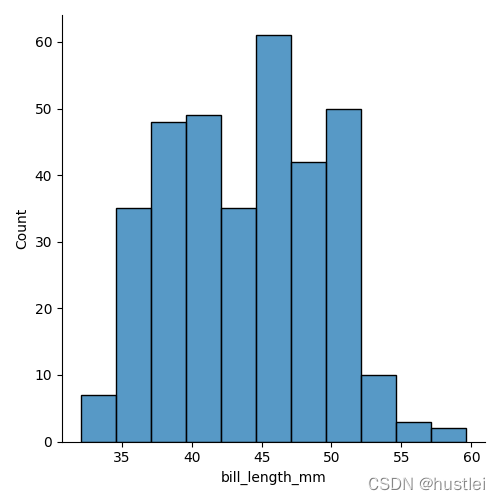
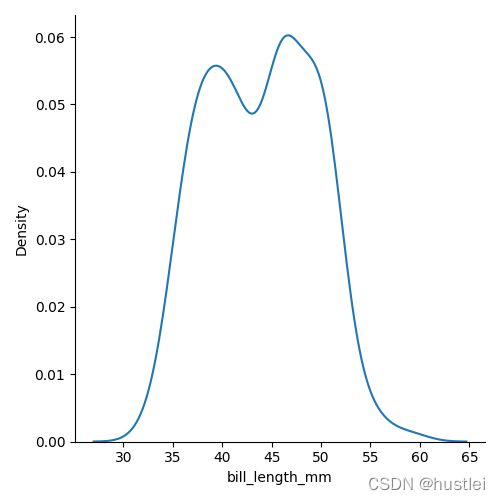
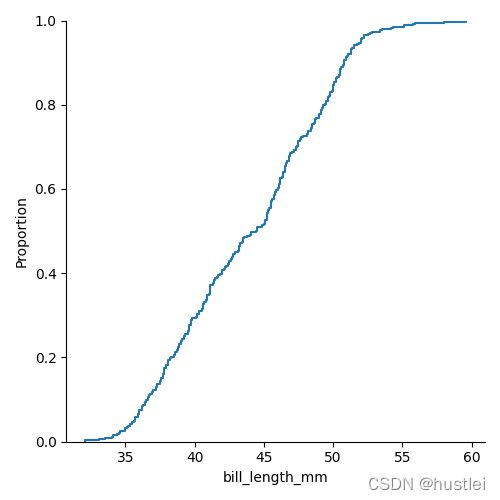
2.2 displot直方图kde图同时叠加绘制
displot绘制直方图时可以叠加核密度图。
绘制直方图不能叠加ecdf图。
sns.displot(data=penguins, x="bill_length_mm", kde=True) # 在直方图中同时绘制核密度图
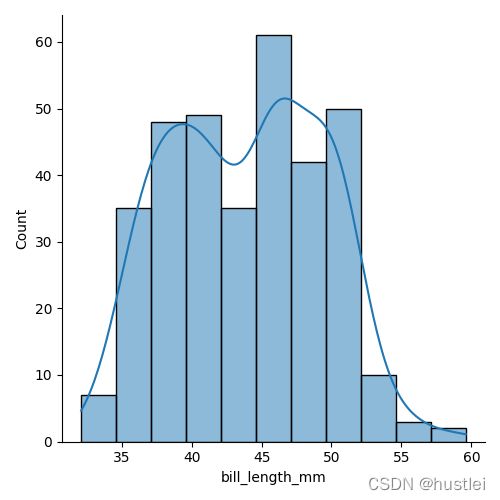
注意反过来在kde图上叠加直方图是不行的。
2.3 displot绘图同时叠加rug图
直方图、核密度图、累积分布图都可以叠加rug图。
rug图是在坐标轴上用短线的疏密表示分布的图形。短线有点像坐标刻度,长度相同,分布多的位置短线更密。可能细线像地毯的边缘,所以叫rug图
sns.displot(data=penguins, x="bill_length_mm", rug=True)
sns.displot(data=penguins, x="bill_length_mm", kind="kde", rug=True)
2.4 displot双变量分布图(直方图、核密度)
sns.displot(data=penguins, x="flipper_length_mm", y="bill_length_mm")
sns.displot(data=penguins, x="flipper_length_mm", y="bill_length_mm", kind="kde")
双变量图也可以用rug参数叠加rug图。但是不能叠加直方图和kde图。
sns.displot(
data=penguins, x="flipper_length_mm", y="bill_length_mm", kind="kde", rug=True
)
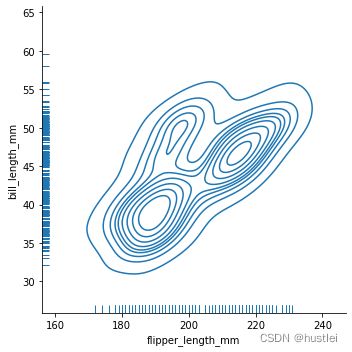
2.5 displot分组统计绘图
类似relplot使用hue参数可以用不同颜色绘制指定参数的分布图。
注意displot只能使用hue分组。没有style和size分组功能。
sns.displot(data=penguins, x="flipper_length_mm", hue="species")
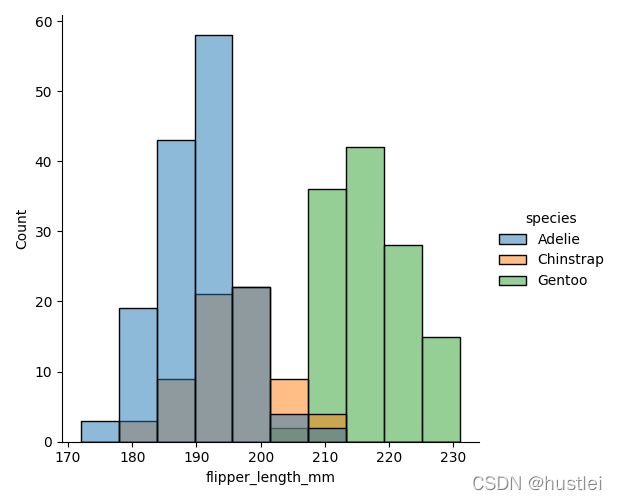
sns.displot(data=penguins, x="flipper_length_mm", kind="kde", hue="species")

sns.displot(data=penguins, x="flipper_length_mm", kind="ecdf", hue="species")
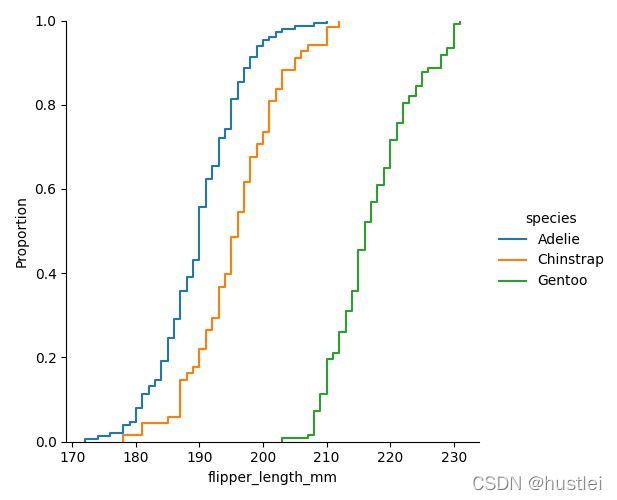
省略x,y参数,只指定data时,
sns.displot(data=penguins,kind="...")将把data当做宽数据,为每列绘制分别绘制图形。
2.6 displot绘制多个子图
用row和col参数可以根据指定参数在不同的行列中绘制子图。
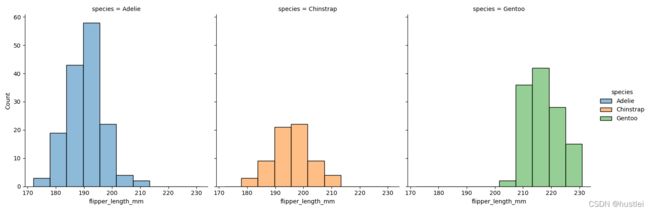
sns.displot(data=penguins, x="flipper_length_mm", col="species")
sns.displot(data=penguins, x="flipper_length_mm", hue="species",col="species")
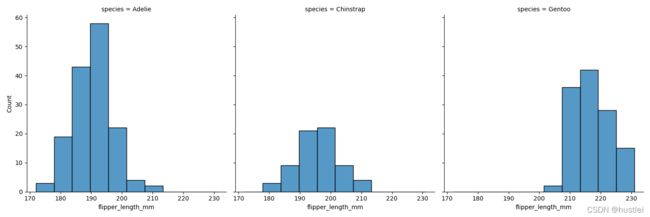
3 displot、histplot直方图详解
displot为figure级函数,histplot为axes级函数,都可以绘制直方图,参数用法基本相同。
3.1 直方图基本参数设置
bins=20:设置直方柱数量。也可以用列表[1,2,3]方式指定边界binwidth=3:设置直方柱范围数值,即bin=(max(x)-min(x))/bins。设置binwidth后bins参数无效。discrete=True:离散方法绘图,即binwidth=1。
fill=False:是否填充log_scale=True:是否对数坐标element="step":cumulative=True
3.1.1 横向直方图
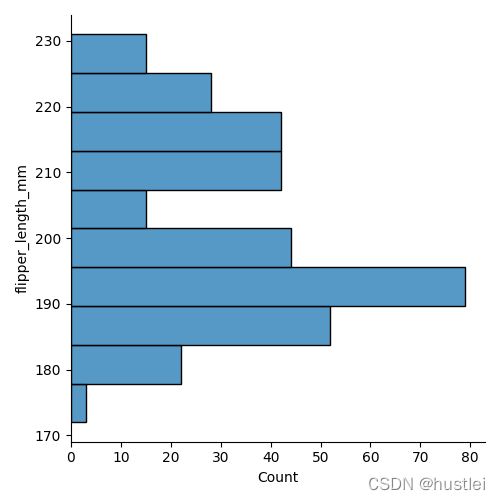
只指定x参数表示绘制垂直方向直方图,只指定y参数表示绘制横向直方图,同时指定x,y表示二维直方图。
sns.displot(data=penguins, y="flipper_length_mm")
#sns.histplot(data=penguins, y="flipper_length_mm")
3.1.2 直方柱数量
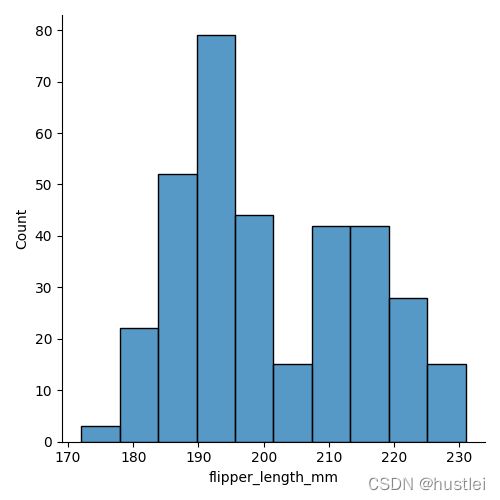
bins、binwidth、discrete参数作用相同。只是指定方式不同,bins表示范围内直方柱数量,binwidth表示单个直方柱范围,即bins和binwidth乘积为参数范围。disctret表示binwidth=1。
sns.displot(data=penguins, x="flipper_length_mm",bins=10)
3.1.3 直方图样式
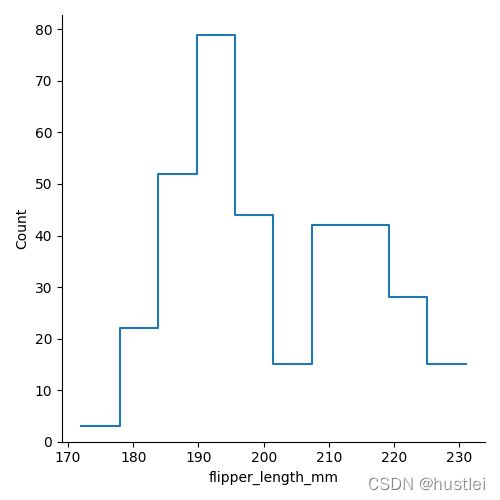
- fill参数可以指定直方柱是否填充
- element参数可以设置直方图的样式。
- “bars”:默认直方图样式
- “step”:阶梯样式
- “poly”:用折线代替直方图表示分布
sns.displot(data=penguins, x="flipper_length_mm",fill=False,element="step")
sns.displot(data=penguins, x="flipper_length_mm",fill=False,element="poly")
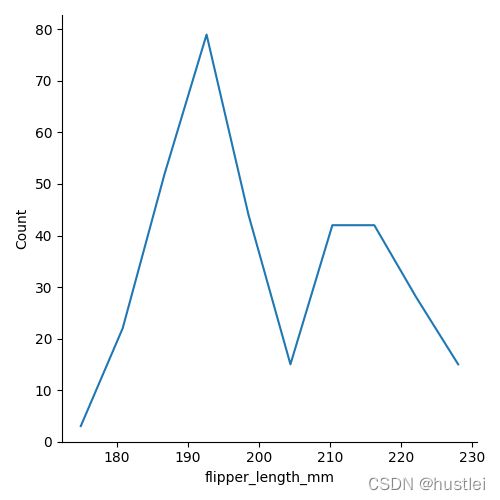
3.2 直方图统计方式
直方图高度默认统计的是变量在区间内数据个数,用stat参数可以设置显示数据占比或者其他统计方式。
- stat=“count”:参数指示直方图高度显示的统计内容
- “count”:默认值,每个区间数据总数
- “frequency”:单位区间数据数量
- “probability"or"proprotion”:0-1表示占比
- “percent”:百分比
- “density”:标准化表示,总面积等于1
sns.displot(data=penguins, x="flipper_length_mm",stat="probability")
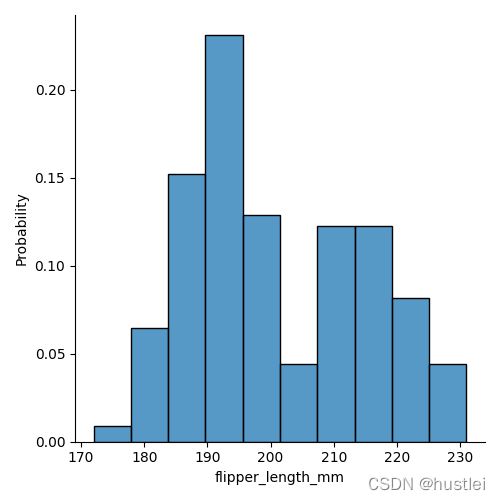
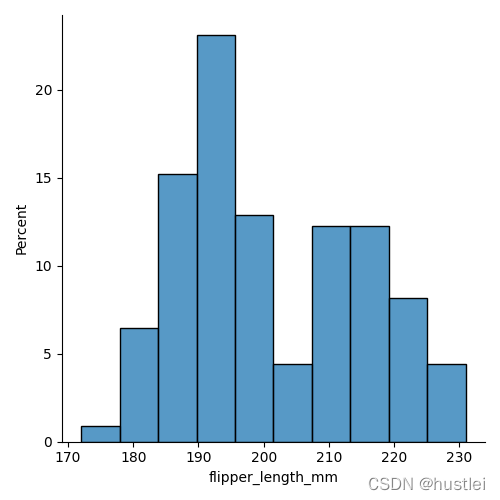
sns.displot(data=penguins, x="flipper_length_mm",stat="percent")
3.3 分组直方图样式
- multiple=“layer”:参数指示直方图分组绘制时的样式
- “layer”:默认值,在不同的图层中叠加绘制
- “stack”:高度方向叠加绘制
- “dodge”:绘制成不同的直方柱
- “fill”:每个直方柱总高度都为1
sns.displot(data=penguins, x="flipper_length_mm",hue="species",multiple="layer")
sns.displot(data=penguins, x="flipper_length_mm",hue="species",multiple="stack")
sns.displot(data=penguins, x="flipper_length_mm",hue="species",multiple="dodge")
sns.displot(data=penguins, x="flipper_length_mm",hue="species",multiple="fill")
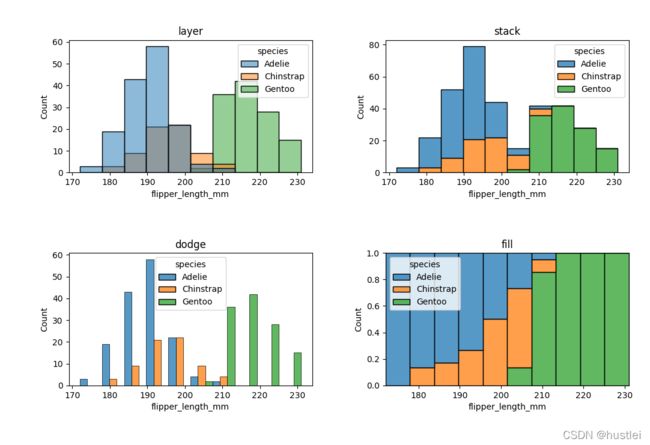
multiple参数必须和hue一起使用
4 displot、kdeplot核分布图详解
displot为figure级函数,kdeplot为axes级函数,都可以绘制核分布图,参数用法基本相同。
核密度估计(KDE)图与直方图相似,使用连续概率密度曲线来表示数据。
4.1 kde平滑参数
相对于直方图,KDE图不是使用离散的方柱,而是使用高斯核平滑观测值,从而生成连续的密度估计值。
但是,如果基础分布是有界的或不平滑的,则有可能引入失真。使用如下参数可以调整平滑度:
bw_method=0.5:使用的平滑带宽的方法。用于计算估计器带宽的方法。bw_adjust=1:bw_method缩放所使用的因子。增加将使曲线更平滑。
bw_method和bw_adjust参数可以参考scipy.stats.gaussian_kde。
sns.kdeplot(data=penguins, x="flipper_length_mm",bw_method=0.5)
sns.kdeplot(data=penguins, x="flipper_length_mm",bw_adjust=0.5)
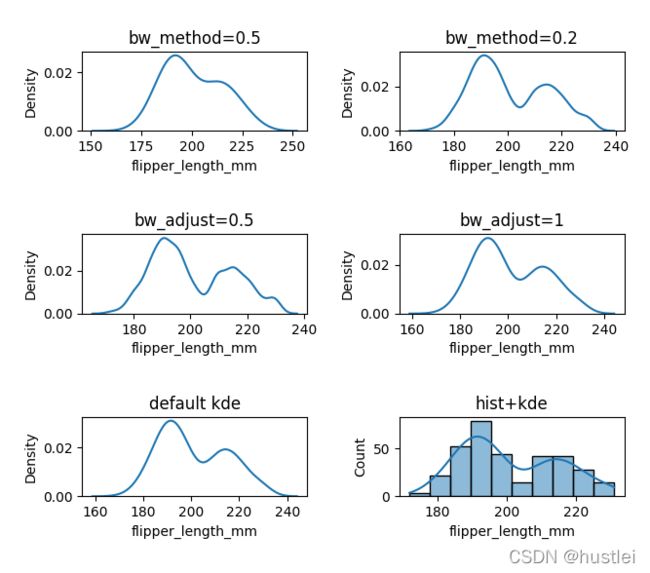
平滑核的带宽参数与直方图中带宽的选择非常相似
过度平滑的曲线可以擦除分布的真实特征,而平滑度不足的曲线可能会因随机变异性而产生假特征。设置默认带宽的经验法则在真实分布平滑、单峰且大致呈钟形时效果最佳。
取值越大越平滑,可以大于1。
4.2 kde分组绘图
- hue参数:指定按颜色分组绘制
- multiple参数:指定样式
- “layer”:默认值,在不同的图层中叠加绘制
- “stack”:高度方向叠加绘制
- “fill”:总高度为1
kdeplot的multiple参数不支持dodge。
sns.kdeplot(data=penguins, x="flipper_length_mm",hue="species",multiple="stack")
#sns.kdeplot(data=penguins, x="flipper_length_mm",hue="species",multiple="fill")
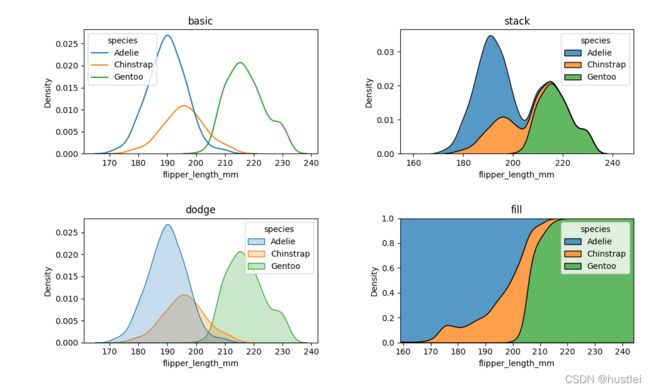
4.3 双参数kde绘图
geyser = sns.load_dataset("geyser")
sns.kdeplot(data=geyser, x="waiting", y="duration")
sns.kdeplot(data=geyser, x="waiting", y="duration", hue="kind")
sns.kdeplot(data=geyser, x="waiting", y="duration", hue="kind",levels=5)
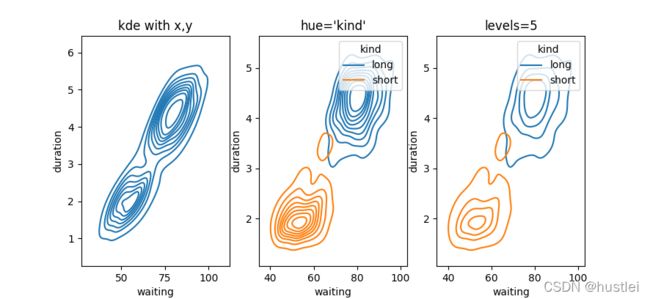
4.4 kde样式
alpha=.5, linewidth=0参数可以设置样式
cmap可以设置颜色
sns.kdeplot(data=geyser, x="waiting", y="duration", alpha=.5, linewidth=0, fill=True, cmap="hsv")
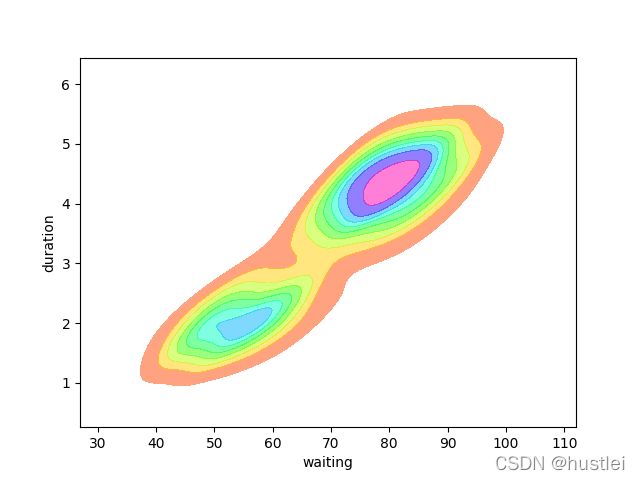
5 ecdfplot,displot绘制累积分布图
ecdf可以认为是分布的积分。ecdf不支持双参数分布绘制。
5.1 ecdf图基本方法
hue、stat等参数与kdeplot函数相同
geyser = sns.load_dataset("geyser")
sns.ecdfplot(data=geyser, x="waiting")
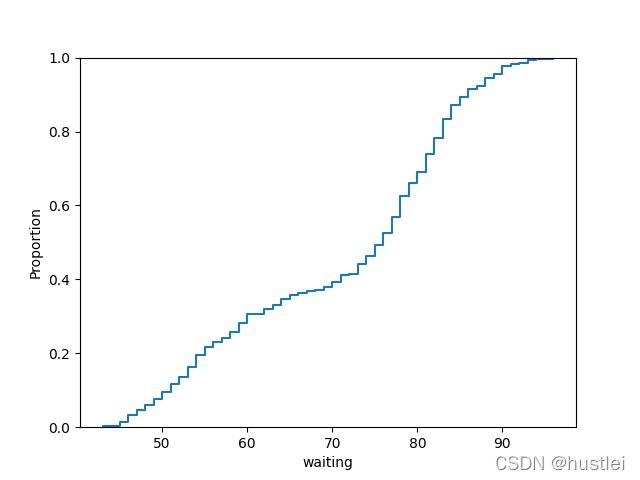
geyser = sns.load_dataset("geyser")
sns.ecdfplot(data=geyser, x="waiting",hue="kind")
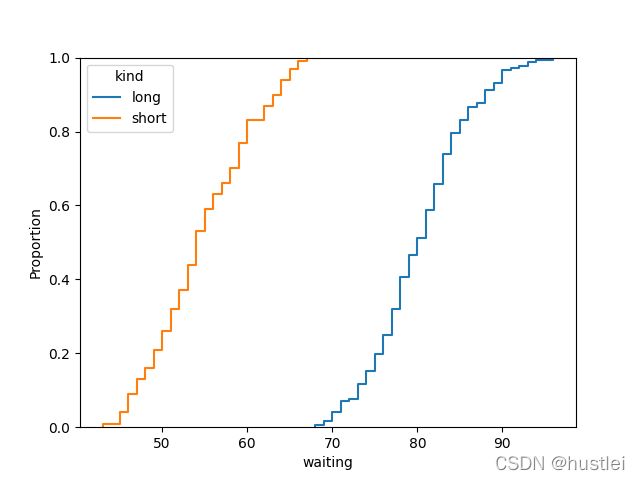
geyser = sns.load_dataset("geyser")
sns.ecdfplot(data=geyser, x="waiting",stat="count")

5.2 互补ecdf
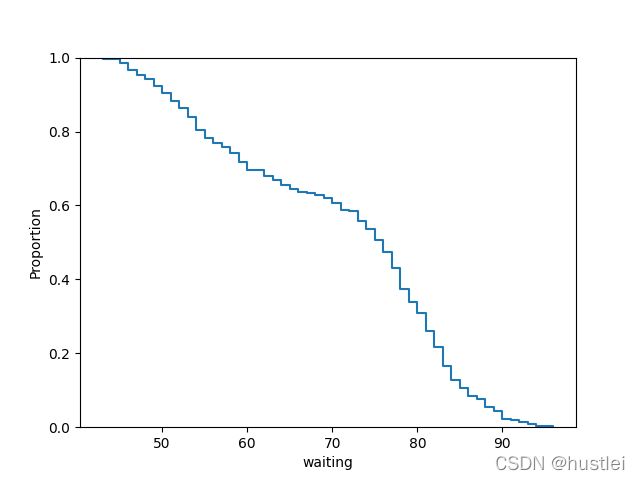
ecdf绘制的y轴值cdf,用complementary=True设置互补后y轴值取1-cdf
geyser = sns.load_dataset("geyser")
sns.ecdfplot(data=geyser, x="waiting",complementary=True)
6 rugplot绘制累积分布图
rugplot不能使用figure级函数displot绘制。
6.1 rug图绘制方法
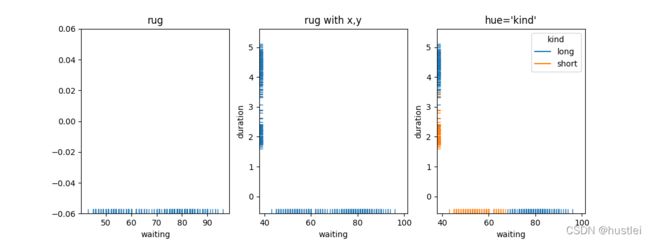
geyser = sns.load_dataset("geyser")
sns.rugplot(data=geyser, x="waiting")
sns.rugplot(data=geyser, x="waiting", y="duration")
sns.rugplot(data=geyser, x="waiting", y="duration",hue="kind")
6.2 改变rug短线长度
height参数可以设置rug短线的长度
sns.rugplot(data=geyser, x="waiting", height=0.5)
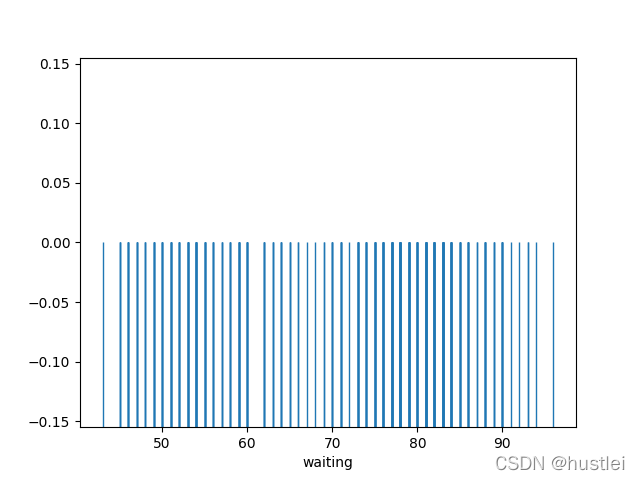
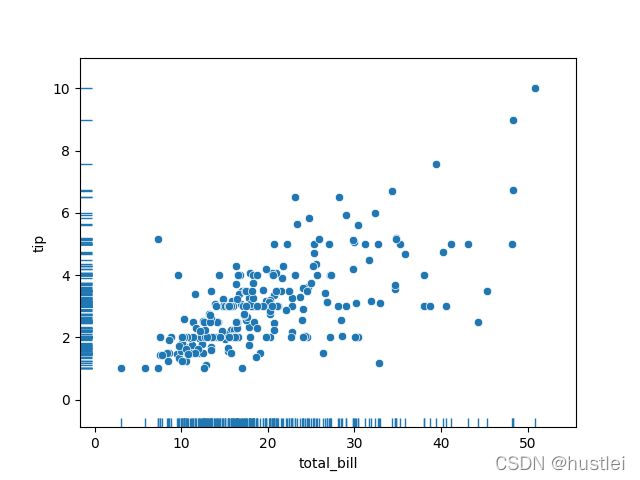
6.3 rug图嵌入其他图形
rug图单独绘制意义不大,通常和其他图形合并显示。可以通过displot函数绘制,也可以通过axes级函数在同一个axes中绘制。
geyser = sns.load_dataset("geyser")
sns.displot(data=geyser, x="waiting", kind="kde", rug=True)

tips=sns.load_dataset("tips")
sns.scatterplot(data=tips, x="total_bill", y="tip")
sns.rugplot(data=tips, x="total_bill", y="tip")
Seaborn系列目录
个人总结,部分内容进行了简单的处理和归纳,如有谬误,希望大家指出,持续修订更新中。
修订历史版本见:https://github.com/hustlei/AI_Learning_MindMap
未经允许请勿转载。