Seaborn系列(一):绘图基础、函数分类、长短数据类型支持
Seaborn系列目录
文章目录
- 1. Seaborn特点
- 2. 基本绘图方法
-
- 2.1 numpy数组数据绘图
- 2.2 pandas数组数据绘图
- 3. Seaborn函数分类
-
- 3.1 根据图形控制级别分类
- 3.2 绘图函数功能分类
- 4. 长格式、短格式数据Seaborn绘图
-
- 4.1 长格式、短格式数据
- 4.2 宽格式数据绘图
- 4.3 长格式数据绘图
- 4.4 凌乱数据
1. Seaborn特点
Seaborn是一个基于matplotlib,进行了二次封装的可视化绘图库。
相比matplotlib:
- 绘图函数接口简洁,对数据统计支持更好。绘图函数主要分为关系、分布、统计、绘图等几类,对功能进行了定制。
- 对pandas数据类型支持更加友好(matplotlib不依赖scipy和pandas,但是seaborn依赖scipy和pandas)
- 预定义风格、样式好看
2. 基本绘图方法
常用的numpy数组和pandas数据都可以非常方便的直接用于Seaborn绘图(当然python原生列表等数据也ok)。简单示例如下:
2.1 numpy数组数据绘图
import numpy as np
import seaborn as sns #惯例将seaborn导入为sns
import matplotlib.pyplot as plt #显示图形还是需要依靠matplotlib
#准备数据
x=np.linspace(0, 4*np.pi,100)
y=np.sin(x)
#绘图
sns.relplot(x=x,y=y,kind="line") #用关系绘图函数绘制折线图
#显示图形
plt.show()
2.2 pandas数组数据绘图
import pandas as pd
import seaborn as sns #惯例将seaborn导入为sns
import matplotlib.pyplot as plt #显示图形还是需要依靠matplotlib
#准备数据
df=pd.DataFrame({'x':[1,2,3,4,5] ,'y':[1,3,2,4,5]})
#绘图
sns.relplot(x='x',y='y',data=df,kind="line") #用关系绘图函数绘制折线图
#显示图形
plt.show()
注意seaborn是基于matplotlib的,显示还是要调用matplotlib的plt.show()。
3. Seaborn函数分类
3.1 根据图形控制级别分类
Seaborn绘图函数根据图形层级分为两种类型:
- axes级:绘图函数在单个axes上绘图,函数返回值就是axes对象。
- figure级:绘图函数在figure上绘图,返回一个FacetGrid对象,类似Figure对象,可以管理figure。
3.2 绘图函数功能分类
seaborn绘图函数根据功能可以分为关系绘图、统计绘图、分组绘图等,每组功能都提供了一个figure级函数(可以实现所有本组函数绘图功能,api统一),同时提供若干个axes级函数。
Seaborn的API是扁平结构的,所有绘图函数都直接在seaborn根模块下,函数数量也非常少。seaborn并非为了替代matplotlib,但是在很多情况下,seaborn会更加方便,尤其是统计相关绘图。
- relplot(关系绘图):figure级函数
- scatterplot:axes级函数(散点图)
- lineplot:axes级函数(折线图)
- displot(分布统计绘图):figure级函数
- histplot:axes级函数(直方图)
- kdeplot:axes级函数(核密度图)
- ecdfplot:axes级函数(累积分布图)
- rugplot:axes级函数(地毯图)
- distplot:官方已废弃的过时api
- catplot(类别统计绘图):figure级函数
- striplot:axes级函数(分类散点条图)
- swarmplot:axes级函数(分类散点簇图)
- boxplot:axes级函数(箱形图)
- violinplot:axes级函数(提琴图)
- barplot:axes级函数(柱形图)
- pointplot:axes级函数(分类统计点图)
- countplot:axes级函数(数量统计图)
- lmplot(回归统计绘图)::figure级函数
- regplot:axes级函数(回归拟合图)
- residplot:axes级函数(回归拟合误差图)
- clustermap(矩阵绘图):figure级函数
- heatmap:axes级函数(热度图)
- 两个特殊的figure级函数(多图组合)
- jointplot:figure级函数,返回JointGrid对象。同时绘制3个子图,在绘制二维图的基础上,在图行上方和右侧绘制分布图。
- pairplot:figure级函数,返回PairGrid对象。(配对分布统计图)
jointplot和pairplot函数也是figure级函数,但是是两个比较特殊且重要的函数。都是将多个子图组合的图形。
以上即为seaborn所有的绘图函数,当然seaborn还包含一些样式设置、数据集相关函数。
figure函数直接在figure中绘制图形。axes绘图函数则是在axes中绘图,可以在函数中用ax参数指定要绘图的axes。
因此,多个axes级函数可以在同一个axes中叠加绘图,但是figure级函数不行,axes级函数灵活度更高。
几乎所有的axes级函数绘制的图形,都可以用figure级函数实现相同效果。比如直方图用displot和histplot都可以绘制,只需要把displot的kind参数设置为"hsit"就可以了。
figure级函数api统一,功能强大,因此,官方文档建议大多数情况下优先使用figure级函数。
- figure级函数优点
- 函数api统一
- 容易进行figure级参数设置。
- 可以在坐标系外部绘制图例(figure级别图例)。
- figure级函数的缺点
- 部分控制参数并不在函数参数中。(当然可以通过返回值进行控制)
- 由于自己控制figure,很难在像axes级函数一样多种图像在同一个figure中绘制。
虽然figure级函数可以通过访问函数返回的对象添加其他元素。但是,当需要绘制复杂的、由多种不同类型图形组合的figure时,建议用matplotlib设置figure,用axes级函数绘图。
4. 长格式、短格式数据Seaborn绘图
seaborn支持多种不同数据集格式。大多数函数接受pandas、numpy以及python类型(如列表和字典)数据。
4.1 长格式、短格式数据
即使对于同一中数据,我们在记录或者表示的时候,会经常遇到两种完全不同的形式:
1) 长格式
year month passengers
0 1949 Jan 112
1 1949 Feb 118
2 1949 Mar 132
3 1949 Apr 129
4 1949 May 121
.. ... ... ...
139 1960 Aug 606
140 1960 Sep 508
141 1960 Oct 461
142 1960 Nov 390
143 1960 Dec 432
- 宽格式
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
year
1949 112 118 132 129 121 135 148 148 136 119 104 118
1950 115 126 141 135 125 149 170 170 158 133 114 140
1951 145 150 178 163 172 178 199 199 184 162 146 166
1952 171 180 193 181 183 218 230 242 209 191 172 194
1953 196 196 236 235 229 243 264 272 237 211 180 201
1954 204 188 235 227 234 264 302 293 259 229 203 229
1955 242 233 267 269 270 315 364 347 312 274 237 278
1956 284 277 317 313 318 374 413 405 355 306 271 306
1957 315 301 356 348 355 422 465 467 404 347 305 336
1958 340 318 362 348 363 435 491 505 404 359 310 337
1959 360 342 406 396 420 472 548 559 463 407 362 405
1960 417 391 419 461 472 535 622 606 508 461 390 432
宽格式类似于长格式的透视图,可以用pandas的pivot函数把长格式转换为宽格式。
上述数据可以用以下函数得到:
import seaborn as sns flights=sns.load_dataset("flights") flights_wide=flights.pivot(index="year",columns="month",values="passengers")
4.2 宽格式数据绘图
宽格式数据中,每列都是一个数据系列,可以绘制一条曲线。数据形式见3.1。
默认情况下,不需要指定x,y值seaborn就会自动为每一列绘制一条曲线。
import seaborn as sns #惯例将seaborn导入为sns
import matplotlib.pyplot as plt #显示图形还是需要依靠matplotlib
#准备数据
df=sns.load_dataset("flights") #从网络加载指定数据集。见3.1
df_wide=df.pivot(index="year",columns="month",values="passengers") #转换为宽格式
sns.relplot(data=df_wide,kind="line")
#显示图形
plt.show()
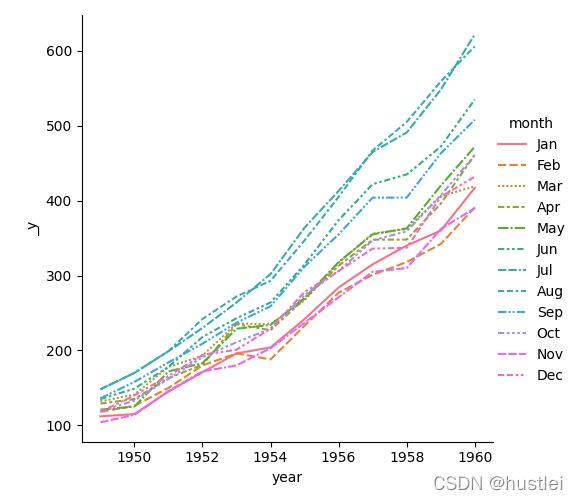
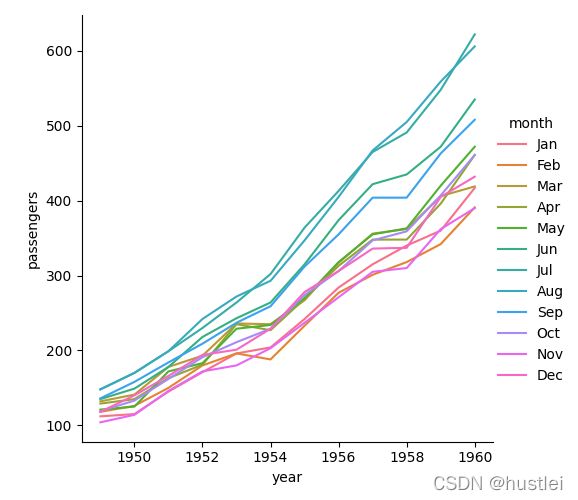
宽格式每行绘图
宽格式数据没行数据其实也是一个系列,因此也可以每行数据绘制一个图形。
sns.relplot(data=df_wide.T,kind="line") #df_wide.transpose()也行
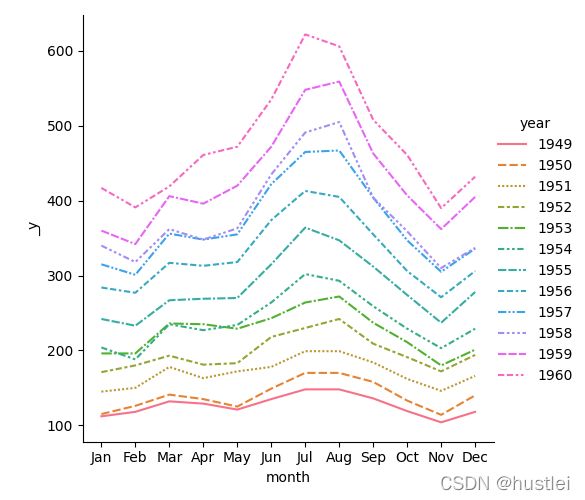
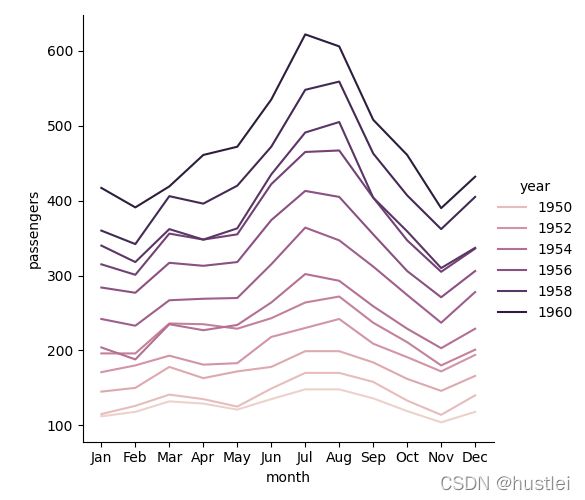
4.3 长格式数据绘图
长格式数据通常和人脑中的数据模型并不一致,宽格式数据于人脑中数据更加一致,见3.1。注意,这里并非说宽格式数据比长格式数据更优。
seaborn可以直接用长格式数据绘图,用hue参数指定用于分组的列(即转宽格式后变为列标签的列)。
import seaborn as sns #惯例将seaborn导入为sns
import matplotlib.pyplot as plt #显示图形还是需要依靠matplotlib
df=sns.load_dataset("flights") #准备数据,从网络加载指定数据集。见3.1
sns.relplot(data=df,x="year",y="passengers",hue='month',kind="line") #绘图
#sns.relplot(data=df,x="month",y="passengers",hue='year',kind="line") #绘图
plt.show() #显示
4.4 凌乱数据
很多数据很难用长格式或宽格式表达,这些数据属于模糊“凌乱”的数据集。凌乱的数据:
- 既不像长格式数据那样,变量由键唯一定义
- 也不像宽格式数据那样,变量由表头定义
以seaborn的“anagrams”数据为例。
>>> df=sns.load_dataset("anagrams")
>>> df
subidr attnr num1 num2 num3
0 1 divided 2 4.0 7
1 2 divided 3 4.0 5
2 3 divided 3 5.0 6
3 4 divided 5 7.0 5
4 5 divided 4 5.0 8
5 6 divided 5 5.0 6
6 7 divided 5 4.5 6
7 8 divided 5 7.0 8
8 9 divided 2 3.0 7
9 10 divided 6 5.0 6
10 11 focused 6 5.0 6
11 12 focused 8 9.0 8
12 13 focused 6 5.0 9
13 14 focused 8 8.0 7
14 15 focused 8 8.0 7
15 16 focused 6 8.0 7
16 17 focused 7 7.0 6
17 18 focused 7 8.0 6
18 19 focused 5 6.0 6
19 20 focused 6 6.0 5
"anagrams"数据是一个心理学实验数据集。对二十个测试者进行测试,他们注意力被分为分散(divided)和集中(focused)两种,分别进行一个叫做回文字(anagrams)的记忆游戏,针对他们的记忆打分。num1-3分别是游戏不同情况的得分,有一种解的游戏得分,有两种解的得分,有三种解的得分。
回文字是指给定一个单词,修改字母顺序得到一个新单词
比如:
who有一种解:how
there有两种解:ether,three
rat有三种解决方案:art, tar, tra
这种数据很难说是“长格式”或者是“宽格式”。
- 按宽格式数据处理,无法将"divided"和"focused"分开。
- 按长格式数据处理,又无法同时分析num1,num2,num3。
抛弃’subidr’列,把num1,num2,num3进行melt(反透视)融合到一列,这样就可以当做长格式数据处理。
分别分析"divided"和"focused"下的情况,以num1-3为变量,分数为数据。
>>> df1=df.melt(id_vars=['subidr','attnr'])
>>> df1
subidr attnr variable value
0 1 divided num1 2.0
1 2 divided num1 3.0
2 3 divided num1 3.0
3 4 divided num1 5.0
4 5 divided num1 4.0
5 6 divided num1 5.0
...
55 16 focused num3 7.0
56 17 focused num3 6.0
57 18 focused num3 6.0
58 19 focused num3 6.0
59 20 focused num3 5.0
>>> sns.relplot(x='variable',y='value',hue='attnr',data=df1,kind='line')
>>> plt.show()
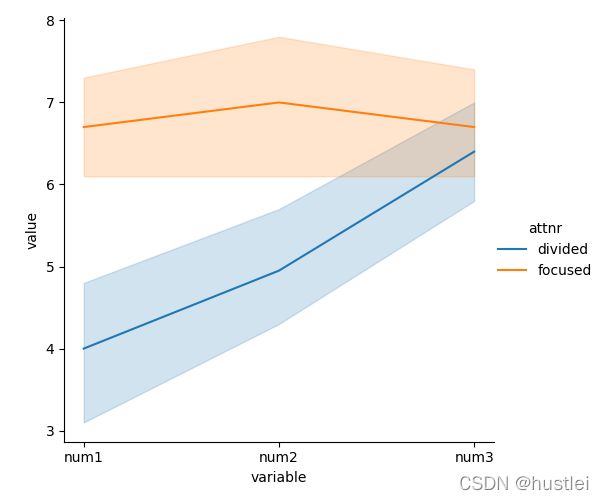
由于每个x坐标对应的y有多个,所以上图中的曲线图还有个上下限。
在凌乱的数据类型中,用长格式具有更明显的优势
当然,我们也可以通过pandas数据处理,转换为更加容易理解的
>>> df1.groupby('variable').mean()
subidr value
variable
num1 10.5 5.350
num2 10.5 5.975
num3 10.5 6.550
Seaborn系列目录
个人总结,部分内容进行了简单的处理和归纳,如有谬误,希望大家指出,持续修订更新中。
修订历史版本见:https://github.com/hustlei/AI_Learning_MindMap
未经允许请勿转载。