5-3 Seaborn 分布绘图
Seaborn 分布绘图
- 3. 分布绘图
-
- 3.1 单变量分布
- 3.2 二变量分布
-
- 3.2.1 散点图
- 3.2.2 六边形图
- 3.2.3 jointplot其他常用参数
- 3.3 成对绘图(pairplot)
Seaborn是基于 Matplotlib 的图形可视化库。该库提前定义好了一套自己的风格,也封装了一系列的方便的绘图函数,之前通过 matplotlib 需要很多代码才能完成的绘图,使用 seaborn 可能就是一行代码的事情。总结一句话:使用 seaborn 绘图比 matplotlib 更美观、简单。
3. 分布绘图
分布绘图分为单一变量分布,多变量分布,成对绘图。
3.1 单变量分布
单一变量主要就是通过直方图来绘制。在 seaborn 中直方图的绘制采用的是 distplot ,其中 dist 是 distribution 的简写,不是 histogram 的简写。 distplot 不仅仅可以绘制直方图,还可以绘制 KDE 曲线以及 rug 线。该函数有以下常用参数:
(1) kde(核密度曲线):这个代表是否要显示 kde 曲线,默认是显示的,如果显示 kde 曲线,那么 y 轴表示的就是概率,而不是数量。也可以设置为 False
(2) bins:代表的这个直方图显示的数量,也可以通过自己设置
(3) rug:代表是否需要显示底部的胡须下线,下面的胡须线越密集的地方,说明数据量越多。
(4) hist:设置为False不展示直方图
#开启默认样式
sns.set(color_codes=True)
the_titanic = titanic[~np.isnan(titanic['age'])]
#查看titanic数据集中年龄的分布情况
sns.distplot(the_titanic['age'],kde=False,bins=30,rug=True)

3.2 二变量分布
多变量分布图可以看出多个变量之间的分布关系。一般都是采用多个图进行表示。多变量分布图采用的函数是 jointplot 。
3.2.1 散点图
通过设置 kind = ‘reg’ 可以设置回归绘图和核密度曲线。
tips = pd.read_csv("dataset/tips.csv")
sns.jointplot(x="total_bill",y="tip",data=tips,kind="reg")

3.2.2 六边形图
对于一些数据量特别大的数据,用散点图不太利于观察。可以采用六边形图来绘制,也就是将之前的散点变成六边形,六边形有一个区间大小,之前这些点落在这个六边形中越多颜色越深。默认情况下,在 x 轴的区间内,可以展示 100 个六边形,所以默认情况下六边形的尺寸会比较小,如果想要展示得更大一点,那么可以设置减少六边形的个数,通过 gridsize 设置。
athletes = pd.read_csv("athlete_events.csv")
china_athletes = athletes[athletes['NOC']=='CHN']
sns.jointplot(x="Height",y="Weight",data=china_athletes,kind="hex",gridsize=50)

3.2.3 jointplot其他常用参数
- x,y,data:绘制图的数据
- kind:scatter、reg、resid、kde、hex
- color:绘制元素的颜色
- height:图的大小,图会是一个正方形
- ratio:主图和副图的比例,只能为一个整型
- space:主图和副图的间距
- dropna:是否需要删除 x 或者 y 值中出现了 NAN 的值
- marginal_kws:副图的一些属性,比如设置 bins、rug、kde等
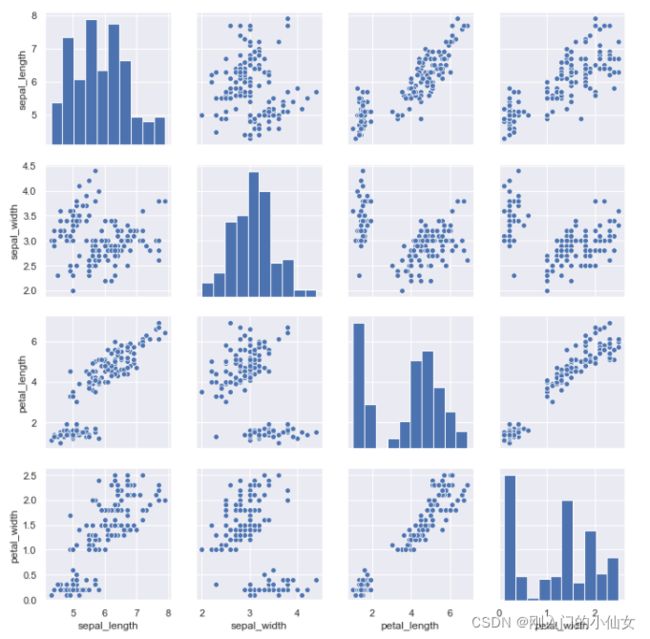
3.3 成对绘图(pairplot)
pairplot 可以把某个数据集中某几个字段之间的关系图一次性绘制出来。默认情况下,对角线的图( x 和 y 轴的列相同)是直方图,其他地方的图是散点图,如果想要修改这两种图,可以通过 diag_kind 和 kind 来实现,其中这两个参数可取的值为:
(1) diag_kind:auto,hist,kde
(2) kind:scatter,reg
#iris鸢尾花数据
#绘制petal_width、petal_height、sepal_width以及sepal_height之间的关系
iris = pd.read_csv("dataset/iris.csv")
#默认取所有数值列进行绘图
sns.pairplot(iris)
#vars指定字段
sns.pairplot(tips,vars=['total_bill','tip'])

#kind参数默认为散点图 diag_kind默认为直方图
sns.pairplot(iris,vars=['sepal_length','sepal_width','petal_length'],kind="reg",diag_kind="kde")
