大数据架构系列:如何理解湖仓一体?

导语 | 本文推选自腾讯云开发者社区-【技思广益 · 腾讯技术人原创集】专栏。该专栏是腾讯云开发者社区为腾讯技术人与广泛开发者打造的分享交流窗口。栏目邀约腾讯技术人分享原创的技术积淀,与广泛开发者互启迪共成长。本文作者是腾讯后台开发工程师叶强盛。
 引言
引言
这十多年大数据技术蓬勃发展,从市场的表现来看基于大数据的数据存储和计算是非常有价值的,其中以云数据仓库为主打业务的公司Snowflake市值最高(截止当前449亿美元),另一家以湖仓一体为方向公司Databricks估值或达380亿美元;各大伺机而动的云厂商也纷纷推出自己的数据湖、云数据仓库、湖仓一体产品。
大数据领域概念(术语)还是非常多的,大多数时候都是先射箭再画靶,先有的需求大家搞了一段时间,然后由一些权威人士提出一些概念(术语)用于描述,所以不能严格用数学的定义方式去框定这些概念(术语)的边界;且很多时候一个术语“形象”比“准确”更易传播,形象意味着易懂,准确意味着信息量巨大(参考数学定义)。建议可以从需求的角度去切入理解这些大数据概念和技术,不要过于追求准确的定义。
无论是数据湖还是数据仓库最后还是面向于解决用户的问题,用户要的其实是数据里的信息,依赖于湖和仓的数据摄取、存储、计算能力主要是因为海量多元的数据,如果用户数据小业务简单完全可以用本地Excel导入数据进行各种有效分析。以下讨论数据湖、数据仓库、湖仓一体都是基于用户的数据是海量且复杂多元的。

如上图,在一个复杂场景里,数据分析人员需要进行业务建模、数据建模;技术人员需要进行数据架构的设计、开发、维护;用户可以使用业务模型、数据模型后产生业务价值;App根据算法、模型、用户画像等提供功能和推荐。

What: 什么是数据湖、数据仓库?
说明一下,当前主流的数据湖技术对二进制数据(图片、音频等)不友好,文章上下文说的都是分析型(结构化、半结构化)数据。
只要业务场景复杂数据多元化,无论是你基于任何一个存储框架也得存储各种各样的数据,然后你得有计算引擎可以计算这些数据;同时由于业务要求,你需要对数据进行实时分析。数据湖技术把上述的过程集成化、标准化了;在数据入湖一开始就对数据按照指定标准进行组织,支持流批一体,不同框架有不同的组织方式(对特定场景有优化),但是目的都差不多;入湖后,提供标准化的数据读取方式,支持各种MPP引擎的计算;因为数据提前组织过,所以写入性能下降,查询性能提升。所以你可能之前一直在用数据湖,只是没用到数据湖技术。
数据仓库在入库之前,一般需要进行数据建模;接着按照表的格式对数据进行标准化和表指定的存储引擎进行数据组织,此时可能会损失掉一些信息;计算层通常都会对存储引擎的数据结构进行优化,以此来获得极致的查询体验。日常我们在进行大数据架构的设计实现时,一般会做的比数据仓库限定的范围多,但是我们还是称为数据仓库,所以还是再次提一下,不要太追求准确的定义。

(以上图片来自阿里云)
 Why:业界为什么要做湖仓一体?
Why:业界为什么要做湖仓一体?
我来形象地描述一下:集合两者的优势,像数据仓库一样管理的数据湖,像数据湖一样开放的数据仓库。
从What描述中数据湖和数据仓库的描述可以看出,业内常用的大数据架构基本上就是湖仓一体,即拓宽的数据仓库的功能,也会主动的规范数据的存储和使用。业内目前分享出来的信息来看,主要还是为了替换掉老的Lambda和Kappa架构,想通过一个相对简单的架构进行降本提效。
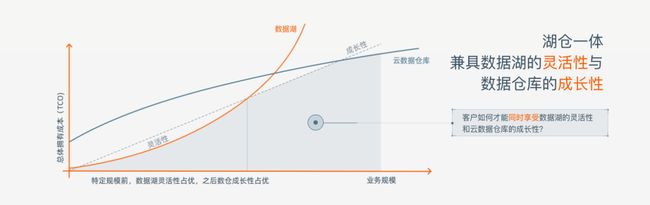
(以上图片来自阿里云)

How:业界怎么做湖仓一体?
目前业内的湖仓一体的架构一般都叫基于某某数据仓库的湖仓一体架构,用户会把热数据(频繁查询)放在数据仓库中,无论在存储和计算上都有大量的优化,计算速度快、成本高;冷数据放在数据湖中,计算慢、成本低,当用户要查询时,直接通过数据仓库的计算层来远程访问数据湖格式的数据,许多架构中还会来临时扩容弹性计算节点来计算冷数据,避免热数据的高效查询受影响。
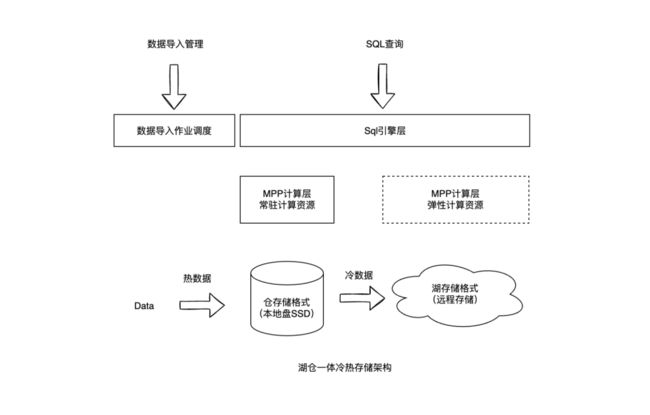 湖仓一体冷热存储架构
湖仓一体冷热存储架构
如上图,近N天的热数据在常驻MPP计算层进行查询,数据变冷后转成数据湖存储格式入湖,后续由弹性MPP计算层对数据进行计算,一般冷数据次数频率较低。
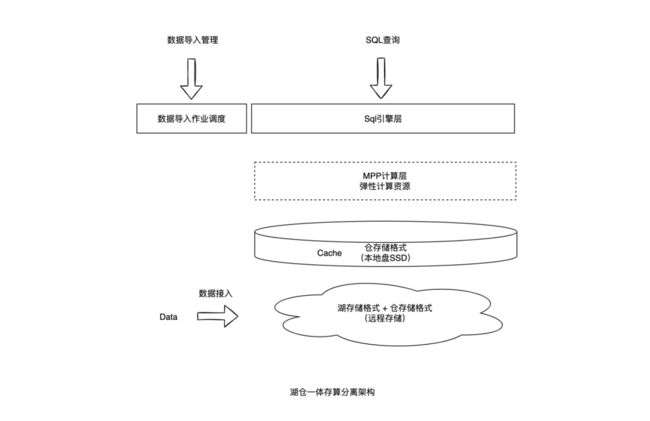
如上图,所有数据异步入湖,数据仓库的元数据会更新,用户查询时会缓存需要扫描的原始数据,通过缓存淘汰机制清理计算频率较低的数据。
真实业务场景可能是同一套架构里面会支持上述两种实现。也有一些湖仓一体的架构中没有数据仓库产品,仅用了Presto作为查询加速(火山引擎、Bilibili),不过整体架构大致也差不多。
以下列举了业界实现的方案:
阿里云 MaxCompute+Hologres
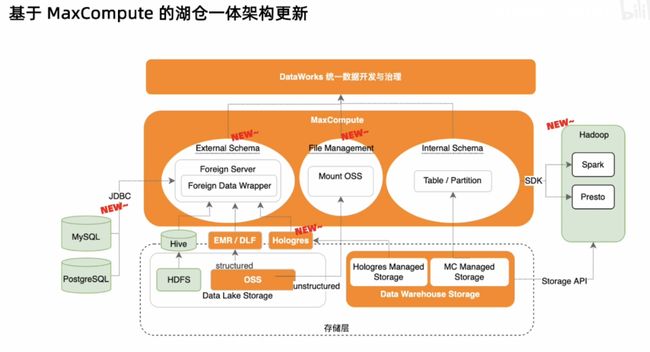
阿里云 EMR+Sarrocks

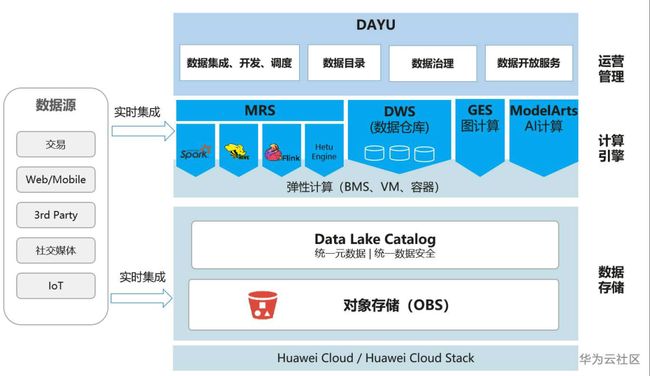
华为云 湖仓一体
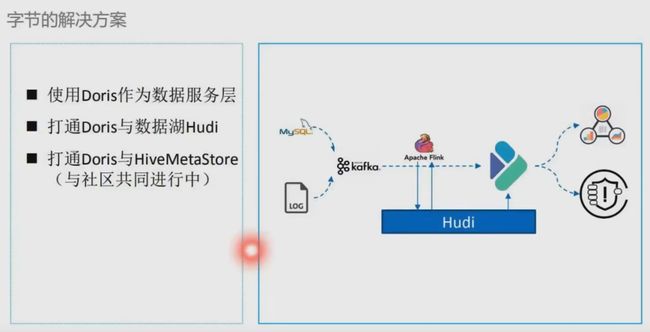
字节跳动 基于Doris的湖仓一体探索
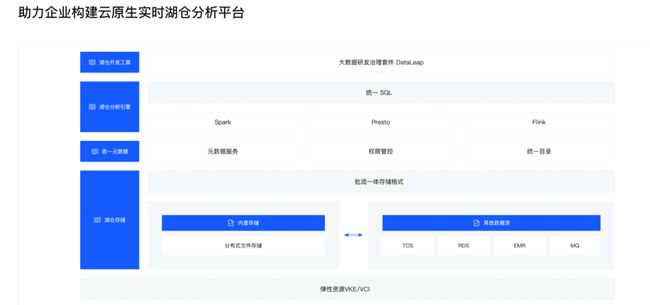
字节跳动-火山引擎 湖仓一体云服务
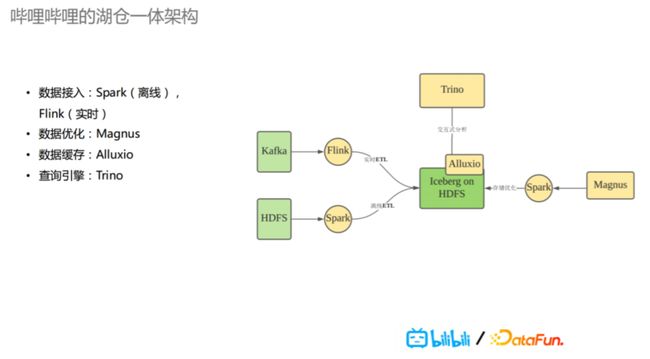
bilibili 湖仓一体架构
Google BigLake
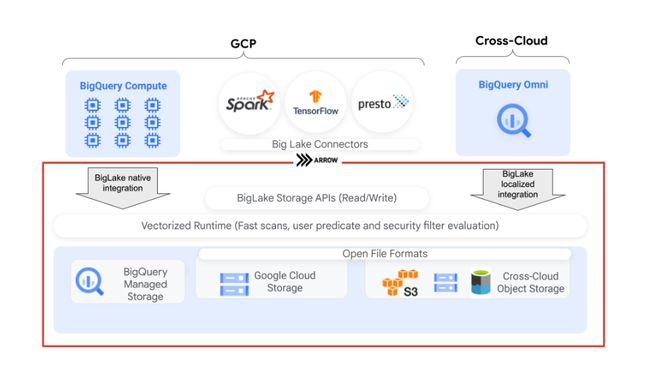
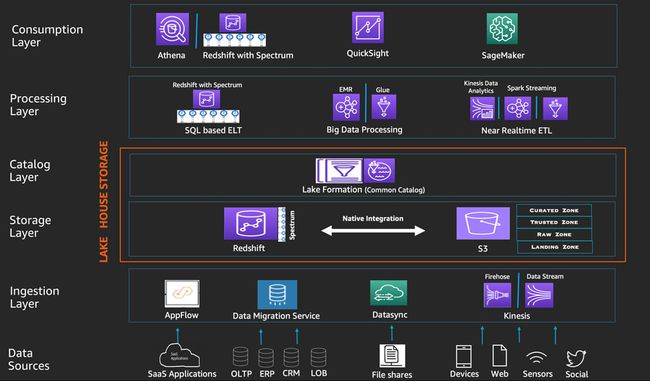
Amazon Lake House
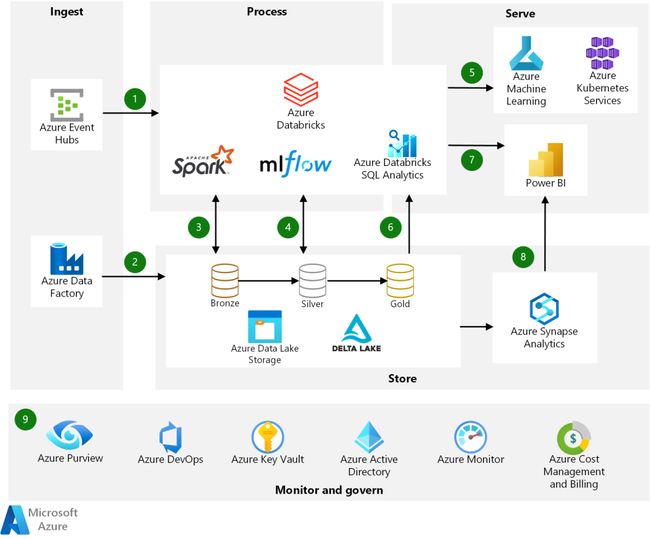
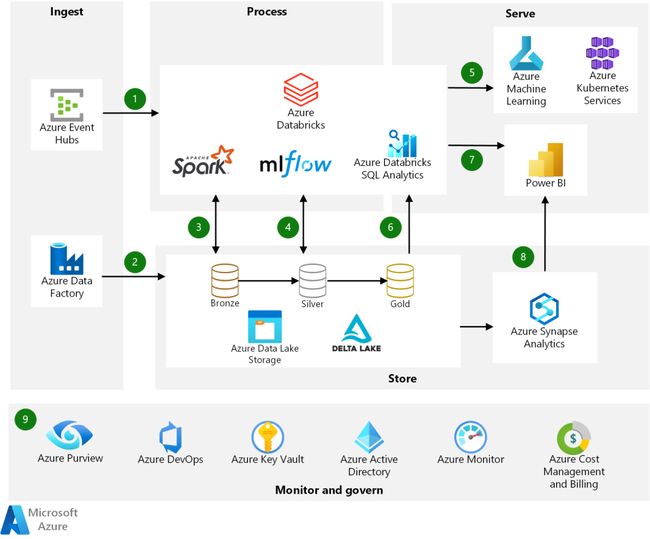
Azure Lake House
SnowFlake Data Lake

总结
当前湖仓一体主要面向于解决用户数据量特别大且多元化的场景,仓的作用在于提速,湖的作用在支持海量的数据并发写入和海量存储;且设计者希望尽量降低架构的复杂度,提高效率。
以下个人评估,仅供参考:
SnowFlake在分析型数据场景下基本上就是天生的湖仓一体,优势巨大。
Doris/Starrocks的架构也会往Snowflake方向改进,潜力满满。
基于Spark/Presto的湖仓一体,查询的效率会低于上述两种,但是可以作为补足上述的部分场景。
参考资料:
1.多角度解析:数据湖VS数据仓库的根本区别
2.深度对比Delta、Iceberg和Hudi三大开源数据湖方案
3.2万字详解数据湖:概念、特征、架构与案例
4.详解数据湖,概念、特征、架构、方案、场景以及建湖全过程
5.4万字全面掌握数据库、数据仓库、数据集市、数据湖、数据中台
6.大数据发展20年,“仓湖一体”是终局?
7.B站基于Iceberg的湖仓一体架构实践
8.亚马逊湖仓一体
9.构建切实有效的湖仓一体架构
作者简介

叶强盛
腾讯云开发者社区【技思广益·腾讯技术人原创集】作者
腾讯后台开发工程师,目前负责腾讯天穹大数据OLAP引擎相关研发工作,有着丰富的大数据框架研发经验。
推荐阅读
揭秘前端眼中的Rust!
如何基于标准化的OpenTelemetry构建APM探针能力
DevOps难以落地之谜,揭开DevOps的神秘面纱!
看完这篇,轻松get限流!

点击「阅读原文」,注册成为社区创作者,认识大咖,打造你的技术影响力!