推荐算法之Embedding方法汇总
前言
推荐算法的效果离不开embedding的使用,embedding是推荐算法中很重要的一个组成部分,不过也是根据不同的业务需求和数据采取不同的embedding方式,在这里我也是稍微总结常用的几种embedding方法吧。
用一句话来总结一下embedding就是将稀疏矩阵向量,变成稠密矩阵向量。
1、word2vec和item2vec
word2vec这是一款很经典的embedding方法了,源自于nlp中。在nlp中CBOW( Continuous Bagof-Words)和 Skip-gram 语言模型的工具就是Word2vec。在这里我是用skip-gram来引出word2vec。
在一个语言数列中,Skip-gram的目的是推测当前单词可能的前后单词。我们设想一下滑动窗在训练数据时如下图所示(绿框中的词语是输入词,粉框则是可能的输出结果):

不断地移动滑动窗口我们可以得到一批样本。在推荐系统中也就是我们的特征向量。在训练过程开始之前,我们预先处理我们正在训练模型的文本。在这一步中,我们确定一下词典的大小(我们称之为vocab_size,比如说10,000)以及哪些词被它包含在内。在训练阶段的开始,我们创建两个矩阵——Embedding矩阵和Context矩阵。这两个矩阵在我们的词汇表中嵌入了每个单词(所以vocab_size是他们的维度之一)。第二个维度是我们希望每次嵌入的长度,即embedding的长度。
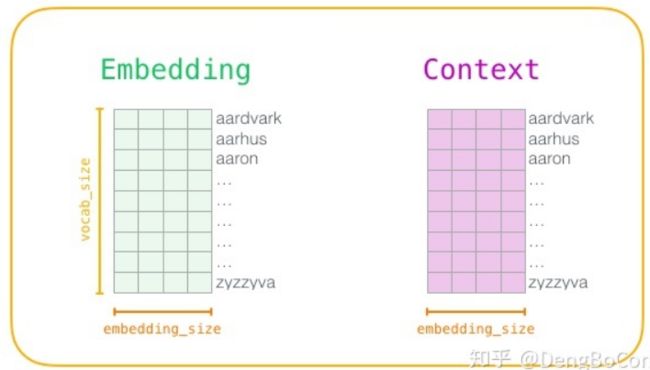
上面的矩阵就是embedding网络了,即一个三层神经网络。在word2vec诞生之后,embedding的思想迅速从NLP领域扩散到几乎所有机器学习的领域,我们既然可以对一个序列中的词进行embedding,那自然可以对用户购买序列中的一个商品,用户观看序列中的一个电影进行embedding。而广告、推荐、搜索等领域用户数据的稀疏性几乎必然要求在构建DNN之前对user和item进行embedding后才能进行有效的训练。具体来讲,如果item存在于一个序列中,item2vec的方法与word2vec没有任何区别。而如果我们摒弃序列中item的空间关系,在原来的目标函数基础上,自然是不存在时间窗口的概念了,取而代之的是item set中两两之间的条件概率。
2、DeepWalk
我们都知道在数据结构中,图是一种基础且常用的结构。现实世界中许多场景可以抽象为一种图结构,如社交网络,交通网络,电商网站中用户与物品的关系等。这里先看下Graph Embedding的相关内容。Graph Embedding技术将图中的节点以低维稠密向量的形式进行表达,要求在原始图中相似(不同的方法对相似的定义不同)的节点其在低维表达空间也接近。得到的表达向量可以用来进行下游任务,如节点分类,链接预测,可视化或重构原始图等。
我们都知道在NLP任务中,word2vec是一种常用的word embedding方法,word2vec通过语料库中的句子序列来描述词与词的共现关系,进而学习到词语的向量表示。DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(RandomWalk)的方式在图中进行节点采样。RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。获取足够数量的节点访问序列后,使用skip-gram model 进行向量学习。
3、Node2vec
Node2vec核心思想在于同质性与结构性的权衡。同质性指的图中距离近的节点应该尽量相似(倾向于DFS),结构性指图中节点所处结构位置相似的应该尽量相似(倾向于BFS)。Node2vec设置了跳转概率,使当前游走过程可能朝着更深的方向(同质性),或是返回之前的方向(结构性)。

node2vec 依然采用随机游走的方式获取顶点的近邻序列,不同的是 node2vec 采用的是一种有偏的随机游走。给定当前顶点 v,访问下一个顶点 x 的概率为:
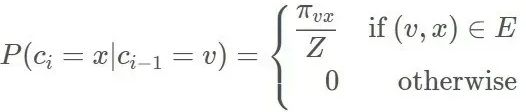
Π 是顶点 v 和顶点 x 之间的未归一化转移概率,Z 是归一化常数。node2vec 引入两个超参数 p 和 q 来控制随机游走的策略。

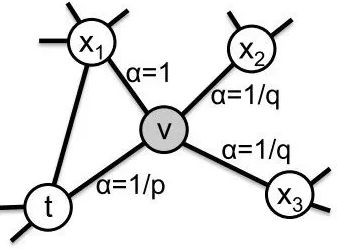
参数p控制重复访问刚刚访问过的顶点的概率。 注意到p仅作用于 d=0的情况,而 d=0表示顶点 x就是访问当前顶点v 之前刚刚访问过的顶点。 那么若 p 较高,则访问刚刚访问过的顶点的概率会变低,反之变高。
q控制着游走的方向是向内还是向外,若q>1,随机游走倾向于BFS,反之则倾向于DFS。
4、EGES
EGES(基于边信息的增强图Embedding)引入边信息作为物品embedding的补充信息,边信息可以是基于知识图谱获得的信息(这类信息包括特征信息)。EGES的方法是对Item及其特征一起进行embedding建模,最终得到的单个Item的embedding向量是该item及其特征的加权平均。EGES对缺少历史数据的Item更为亲切。
eges的提出背景,解决三个推荐系统中应用算法存在的问题:
1、Scalability: 可扩展性,说白了就是你这个算法在小数据集上跑的很ok,效果好,速度也不慢,但是到了大数据集上慢的要死根本没法用则可扩展性很渣;
2、Sparsity: 数据本身的稀疏性,简单来说就是你的特征矩阵中很多缺失值(或者0),模型没法充分学习,则模型不能很好handle稀疏性;
3、cold start:冷启动,比稀疏性很惨,全缺失
原始的deepwalk并没有引入edge的信息,可以使用item的辅助信息来增强graph embedding的效果。在电子商务中,RS是指items的类别,商店,价格等,它在排名阶段被广泛用作关键特征,而在匹配阶段却很少应用。可以通过在图嵌入中合并辅助信息来缓解冷启动问题。例如,优衣库(同一家商店)的两个帽衫(相同类别)可能看起来相似,并且喜欢尼康镜头的人也可能对佳能相机(相似类别和相似品牌)感兴趣。这意味着具有相似辅助信息的物品在嵌入空间中应该更靠近。
为此设计了GES方法:

这里看一个博主手绘的图吧:
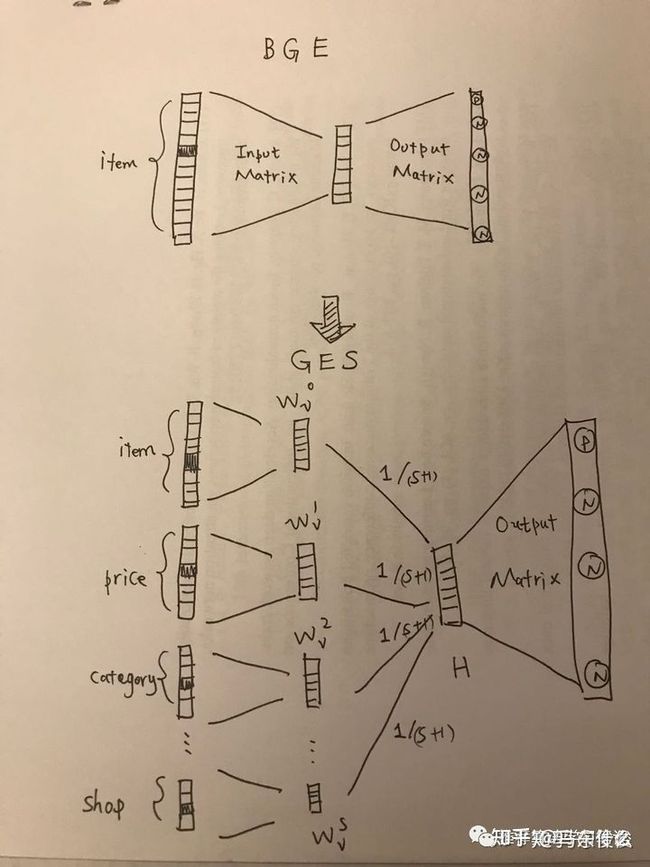
这个结构的指导意义还是很不错的,实际上就是word2vec的多个embedding的版本,我们传统的word2vec的结构中单个input 对应一个词,而这里,单个input对应一个向量,以item2vec为例,单个input就是一个item,而这里单个input包括了[item ,item的价格,item的商品类型,item所在的shop...]并且为每一个属性都建立了一个input embedding,然后这些input embeddings做一个mean pooling就重新变成了一个常规的单个item的input embedding的形式,原论文中对price category shop这些的embedding的size取的大小和item embedding相同,这样才可以直接mean pooling,否则维度不同只能concat了;
这种方式可以很好地环节冷启动问题,对于新的item来说,在embedding的时候 item对应的input在 item embedding的矩阵中是找不到,可能会使用随机初始化或者直接取item embedding矩阵的平均(没有看到复现代码暂时不知道这块儿使用了什么策略),但是像shop id,category、price这些即使是新品也是会存在这些属性的,那么就可以到对应的embedding矩阵中去寻找对应的的embedding了。
EGES:
尽管GES的性能相对于简单的deepwalk有所提高,但在嵌入过程中集成不同类型的side information(为了避免歧义,下面还是用节点特征来描述)仍然存在一个问题:
不同类型的节点特征对最终嵌入的贡献相等并不符合实际的情况, 例如,购买过iPhone的用户往往会因为“苹果”这个品牌而查看Macbook或 Pad,或者,用户则可能在淘宝的同一家商店购买不同品牌的衣服,以获得方便和更低的价格。 因此,不同类型的节点特征对用户的购买行为中共现的items这一现象有不同的贡献。
解决的方法就是 加权求和:
PS:今天有点累,写不动了,就先这样吧,有时间再补。