Python爬虫实践《流浪地球》豆瓣影评分析及实践心得
一段多余的话
多余的话不多说,我想聊聊在进行实践分析中遇到的困难与心得。
下载jupyter进行分析的一些建议
我们安装juputer前,首先需要安装python,因为本人曾经上过自然语言处理课,所以已经安装完成(3.8版本)。
- jupyter的下载参照官网
- 这里要提一点,最好将anaconda提前下载好,免得像我一样引用库时又要花费不必要的时间等待,除此之外它还能提供代码智能提示等功能。
- 对于驱动浏览器种类与版本的选择,我的是谷歌(87.0.4280.88)版本,,可以通过以下网址找到对应的ChromeDriver:http://chromedriver.storage.googleapis.com/index.html
数据爬取和分析时的困难
- 在爬取网页所需信息时,一般在目标网站中找到所需属性,利用xpath确定文档路径(一般可以通过class标签和span标签来寻找),而在获取数据的时候要注意标签里的元素,比如在爬取豆瓣短评时@class="comment-item ",中的item后面有个空格,小细节有些时候也会节省很多时间。
- 将数据爬取成功后输出的CSV文件有乱码,是因为默认的字符编码对中文不友好,建议改为GB18030。
- 在导入各种库时,推荐使用以下命令:pip --default-timeout=100 install 库名称 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com,亲测有效且更快捷
以下为爬取分析的全部代码:
1. 爬取短评数据
def get_web_data(dom=None, cookies=None):
'''
获取每页评论数据
'''
names = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/a/text()')#用户名
ratings = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/span[2]/@class')#用户评分
#times = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/span[3]/@title')#发布时间
times = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/span[@class="comment-time "]/@title')#发布时间
message = dom.xpath('//div[@class="comment-item "]//div[@class="comment"]//span[@class="short"]/text()')#短评正文
user_url = dom.xpath('//div[@class="comment-item "]//span[@class="comment-info"]/a/@href')#用户主页网址
votes = dom.xpath('//div[@class="comment-item "]//div[@class="comment"]//span[@class="votes vote-count"]/text()')#赞同数量
cities = []
load_times = []
for i in user_url:
web_data = requests.get(i, headers=headers, cookies=cookies)
dom_url = etree.HTML(web_data.text, etree.HTMLParser(encoding='utf-8'))
address = dom_url.xpath('//div[@class="basic-info"]//div[@class="user-info"]/a/text()') #用户居住地
load_time = dom_url.xpath('//div[@class="basic-info"]//div[@class="user-info"]/div[@class="pl"]/text()') #用户入会时间
cities.append(address)
load_times.append(load_time)
time.sleep(2)
ratings = ['' if 'rating' not in i else int(re.findall('\d{2}', i)[0]) for i in ratings] #评分数据整理
load_times = ['' if i == [] else i[1].strip()[:-2] for i in load_times] #入会数据整理
cities = ['' if i == [] else i[0] for i in cities] #居住地数据整理
data = pd.DataFrame({
'用户名': names,
'用户居住地': cities,
'用户入会时间': load_times,
'用户评分': ratings,
'发布时间': times,
'短评正文': message,
'赞同数量': votes
})
return data
from selenium import webdriver
from lxml import etree
import requests
import time
import re
import pandas as pd
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome() #启动Chrome浏览器
url = 'https://movie.douban.com/subject/26266893/comments?status=P'
driver.get(url) #获取网页源码
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
cookies_str = 'bid=Ux1GWm3zePM; ap_v=0,6.0; _pk_ses.100001.4cf6=*; __utma=30149280.2113471934.1609764856.1609764856.1609764856.1; __utmb=30149280.0.10.1609764856; __utmc=30149280; __utmz=30149280.1609764856.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=223695111.1176523020.1609764856.1609764856.1609764856.1; __utmb=223695111.0.10.1609764856; __utmc=223695111; __utmz=223695111.1609764856.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); dbcl2="229742964:jFcpDzR4sok"; ck=7sW-; _pk_id.100001.4cf6=bf2fc7feffa8cf64.1609764855.1.1609764878.1609764855.; push_noty_num=0; push_doumail_num=0'
cookies = {}
for i in cookies_str.split(';'): #将cookies整理成所需格式
k, v = i.split('=', 1)
cookies[k] = v
#对所有页面进行数据爬取及解析操作,并进行数据保存
all_data = pd.DataFrame()
wait = WebDriverWait(driver, 10)
while True:
wait.until(
EC.element_to_be_clickable( #通过该项条件确认网页是否已经加载进来
(By.CSS_SELECTOR, '#comments > div:nth-child(20) > div.comment > h3 > span.comment-info > a') #当前页最后一个“用户”按钮是否可以
)
)
dom = etree.HTML(driver.page_source, etree.HTMLParser(encoding='utf-8'))#网页源码解析,得到一个dom文件
data = get_web_data(dom=dom, cookies=cookies)
all_data = pd.concat([all_data, data], axis = 0)
if driver.find_element_by_css_selector('#paginator > a.next') == []: #判定是否还有“后页”按钮
break
confirm_bnt = wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#paginator > a.next')
)
)
confirm_bnt.click() #执行翻页操作
all_data.to_csv('douban111.csv', index=None, encoding='GB18030') #将数据以csv的方式写出
这里要注意,因为豆瓣有反爬取措施,所以只爬取了500条数据,接下来的分析也是围绕着所爬取的500条数据进行一系列操作。
2. 分析好评与差评的关键信息
import pandas as pd
import jieba
from tkinter import _flatten
import matplotlib.pyplot as plt
from wordcloud import WordCloud
with open('stoplist.txt', 'r', encoding='utf-8') as f:
stopWords = f.read()
stopWords = ['\n', '', ' '] + stopWords.split()
stopWords
data = pd.read_csv('douban111.csv', encoding='GB18030')
dataCut = data['短评正文'].apply(jieba.lcut) #分词
def my_word_cloud(data=None, stopWords=None, img=None):
dataCut = data.apply(jieba.lcut) #分词
dataAfter = dataCut.apply(lambda x: [i for i in x if i not in stopWords]) #去除停用词
wordFre = pd.Series(_flatten(list(dataAfter))).value_counts() #统计词频
mask = plt.imread(img)
wc = WordCloud(font_path='C:/Windows/Fonts/simkai.ttf', mask=mask, background_color='white')
wc.fit_words(wordFre)
plt.imshow(wc)
plt.axis('off')
index_negative = data['用户评分'] < 30 #差评数据的索引
index_positive = data['用户评分'] >= 30 #好评数据的索引
my_word_cloud(data=data['短评正文'][index_positive], stopWords=stopWords, img='aixin.jpg') #好评数据词云
my_word_cloud(data=data['短评正文'][index_negative], stopWords=stopWords, img='aixin.jpg') #差评数据词云
my_word_cloud(data=data['短评正文'], stopWords=stopWords, img='aixin.jpg') #整体评论数据词云
3. 分析评论数量及评分与时间的关系
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('douban111.csv', encoding='GB18030')
data
num = data['用户评分'].value_counts()
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.pie(num, autopct='%.2f %%', labels=num.index)
plt.title('《流浪地球》豆瓣短评评分分数图')
num = data['发布时间'].apply(lambda x: x.split(' ')[0]).value_counts()
num = num.sort_index()
plt.plot(range(len(num)), num)
plt.xticks(range(len(num)), num.index, rotation=45)
plt.title('评论数量随日期的变化情况')
plt.grid()
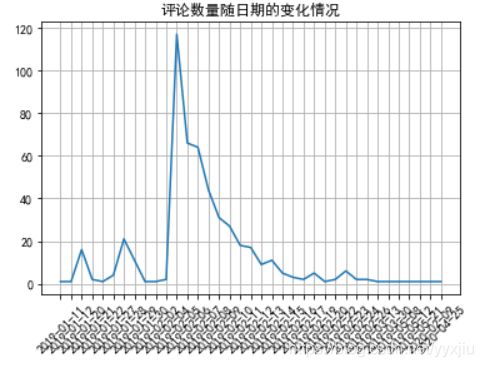
num = pd.to_datetime(data['发布时间']).apply(lambda x: x.hour).value_counts()
num = num.sort_index()
plt.plot(range(len(num)), num)
plt.xticks(range(len(num)), num.index)
plt.title('评论时刻随时刻的变化情况')
plt.grid()
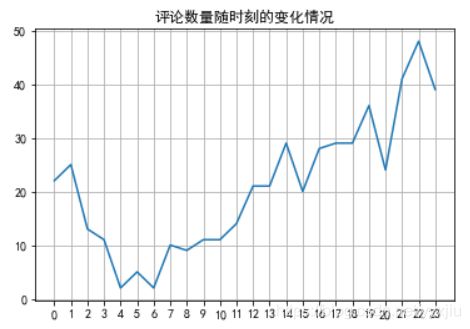
data.loc[:, ['发布时间', '用户评分']]
data['发布时间'] = data['发布时间'].apply(lambda x: x.split(' ')[0])
tmp = pd.DataFrame(0,
index = data['发布时间'].drop_duplicates().sort_values(),
columns= data['用户评分'].drop_duplicates().sort_values())
data.loc[:, ['发布时间', '用户评分']]
for i, j in zip(data['发布时间'], data['用户评分']):
tmp.loc[i, j] += 1
tmp = tmp.iloc[:, :-1]
tmp
n, m = tmp.shape
plt.figure(figsize=(10, 5))
plt.rcParams['axes.unicode_minus'] = False
for i in range(m):
plt.plot(range(n), (-1 if i < 2 else 1) * tmp.iloc[:, i])
plt.fill_between(range(n), (-1 if i < 2 else 1) * tmp.iloc[:, i], alpha = 0.5)
# plt.plot(tmp[10.0])
# plt.plot(tmp[20.0])
# plt.plot(tmp[30.0])
# plt.plot(tmp[40.0])
# plt.plot(tmp[50.0])
plt.grid()
plt.title('评论评分随日期的变化图')
plt.legend(tmp.columns)
plt.xticks(range(n), tmp.index, rotation = 45)
plt.show()
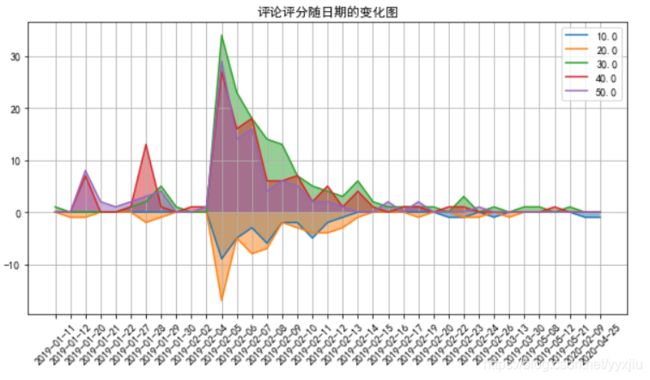
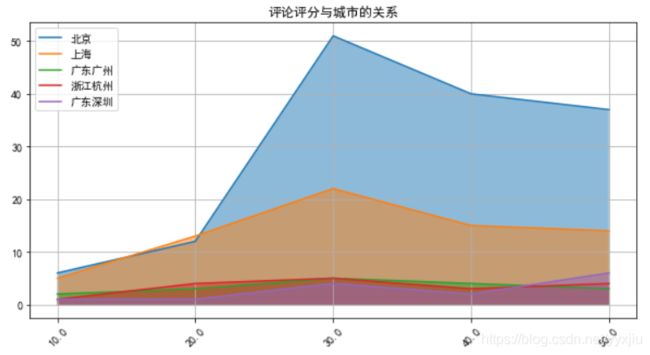
4. 分析评论者的城市分布情况
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('douban111.csv', encoding='GB18030')
num = data['用户居住地'].value_counts()[:10]
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.bar(range(10), num)
plt.xticks(range(10), num.index, rotation = 45)
plt.title('评论数量最多的前十个城市')
for i, j in enumerate(num):
plt.text(i, j, j, ha='center', va='bottom')
plt.show()
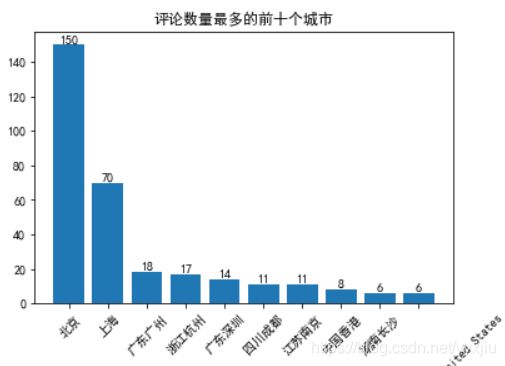
tmp = pd.DataFrame(0,
index=data['用户评分'].drop_duplicates().sort_values(),
columns=data['用户居住地'].drop_duplicates())
for i, j in zip(data['用户评分'], data['用户居住地']):
tmp.loc[i, j] += 1
tmp = tmp.loc[:, cities] #选取评论数前5的城市数据
tmp = tmp.iloc[:5, :] #去除NaN评分数据
n, m = tmp.shape
plt.figure(figsize=(10, 5))
plt.rcParams['axes.unicode_minus'] = False
for i in range(m):
plt.plot(range(n), tmp.iloc[:, i])
plt.fill_between(range(n), tmp.iloc[:, i], alpha = 0.5)
# plt.plot(tmp[10.0])
# plt.plot(tmp[20.0])
# plt.plot(tmp[30.0])
# plt.plot(tmp[40.0])
# plt.plot(tmp[50.0])
plt.grid()
plt.title('评论评分与城市的关系')
plt.legend(tmp.columns)
plt.xticks(range(n), tmp.index, rotation = 45)
plt.show()
参考文献
- https://blog.csdn.net/sinat_26811377/article/details/99698807
- https://www.py.cn/tools/anaconda/16425.html
- https://blog.csdn.net/sheqianweilong/article/details/89843250