B站刘二大人up主pytorch教程P7代码+tips
1.读取数据的问题说明
请注意:up主的diabetes.csv.gz是自己创建的,他把x,y合并到了一个文件之中,且x的形状为(759,8)
而如果我们用sklearn文件夹下的两个文件分别读取,不仅会产生报错(下图所示),而且x的大小还和视频中的不一致。
#####sklearn文件夹下数据
import torch
import numpy as np
import matplotlib.pyplot as plt
x = np.loadtxt('diabetes_data.csv.gz',delimiter= ',',dtype=np.float32)
y = np.loadtxt('diabetes_target.csv.gz',delimiter= ',',dtype=np.float32)
x_data = torch.from_numpy(x)
y_data = torch.from_numpy(y)
print(x_data.size(),x_data)
print("___________________________")
print(y_data.size(),y_data)报错:
![]()
这是因为CSV表格中是以空格来划分数字的,我们将“,”改为“ ”
#####sklearn文件夹下数据
import torch
import numpy as np
import matplotlib.pyplot as plt
x = np.loadtxt('diabetes_data.csv.gz',delimiter= ' ',dtype=np.float32)
y = np.loadtxt('diabetes_target.csv.gz',delimiter= ' ',dtype=np.float32)
x_data = torch.from_numpy(x)
y_data = torch.from_numpy(y)
print(x_data.size(),x_data)
print("___________________________")
print(y_data.size(),y_data)会得到以下结果:

所显示的x大小为(442,10),因此如果直接将这个输入网络一定会出现维度不匹配的报错!
![]()
所以!!!
要用up主提供的diabetes.csv.gz文件
附上链接:https://pan.baidu.com/s/1Snf5mrC14bbNeKNBLlh0zA
提取码:kd03
解决了数据集问题P7的代码就没有难度啦!
2.全部代码
我使用了不同的激活函数(relu+sigmoid)收敛更快些!
import numpy as np
xy = np.loadtxt('diabetes.csv.gz',delimiter=',',dtype = np.float32)
x_data = torch.from_numpy(xy[:,:-1])
print(x_data.size())
y_data = torch.from_numpy(xy[:,[-1]])
print(y_data.size())
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) ####8为输入维度 1为输出维度 改为(8,2)可在后边再加一层(2,1)的层
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activate1 = torch.nn.ReLU()
self.activate2 = torch.nn.Sigmoid()
def forward(self,x):
x = self.activate1(self.linear1(x))
x = self.activate1(self.linear2(x))
x = self.activate2(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(),lr = 0.1)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()输出结果:

1000个epoch后,loss可以达到0.46左右~
还有好像 用up主的代码会出现一些warning,应该是这里:
criterion = torch.nn.BCELoss(size_average = True)根据信息改为:
criterion = torch.nn.BCELoss(reduction='mean')就OK了!
附上绘制loss图和acc图的代码:(就绘制了一下 没调参优化 意思到了~~)
import numpy as np
import torch
import matplotlib.pyplot as plt
#####新建空列表存储绘图所用的数据
epoch_list = []
loss_list = []
acc_list = []
xy = np.loadtxt('diabetes.csv.gz',delimiter=',',dtype = np.float32)
x_data = torch.from_numpy(xy[:,:-1])
print(x_data.size())
y_data = torch.from_numpy(xy[:,[-1]])
print(y_data.size())
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6) ####8为输入维度 1为输出维度 改为(8,2)可在后边再加一层(2,1)的层
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activate1 = torch.nn.ReLU()
self.activate2 = torch.nn.Sigmoid()
def forward(self,x):
x = self.activate1(self.linear1(x))
x = self.activate1(self.linear2(x))
x = self.activate2(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(),lr = 0.1)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_list.append(epoch)
loss_list.append(loss.item())
y_pred_label = torch.where(y_pred >= 0.5, torch.tensor([1.0]), torch.tensor([0.0]))
accuracy = torch.eq(y_pred_label, y_data).sum().item() / y_data.size(0)
acc_list.append(accuracy)
print("loss = ", loss.item(), "acc = ", accuracy)
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
plt.plot(epoch_list,acc_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()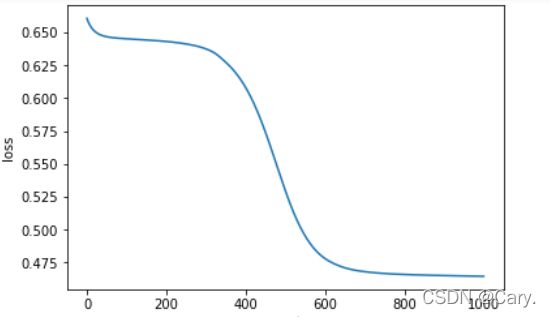
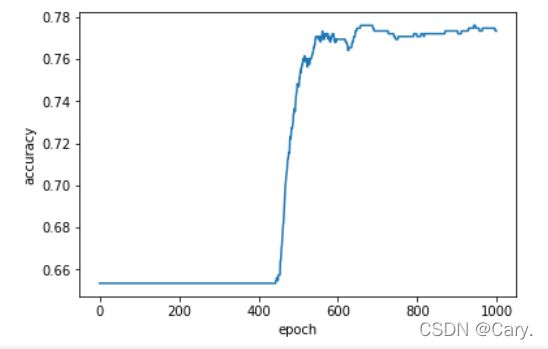
(救命,好丑...)
如果以十个epoch为单位作图应该会得到比较好看的图...