dbscan算法python实现_Python实现DBScan
Python实现DBScan
运行环境
Pyhton3
numpy(科学计算包)
matplotlib(画图所需,不画图可不必)
计算过程
st=>start: 开始
e=>end: 结束
op1=>operation: 读入数据
cond=>condition: 是否还有未分类数据
op2=>operation: 找一未分类点扩散
op3=>operation: 输出结果
st->op1->op2->cond
cond(yes)->op2
cond(no)->op3->e
输入样例
/* 788points.txt */
15.55,28.65
14.9,27.55
14.45,28.35
14.15,28.8
13.75,28.05
13.35,28.45
13,29.15
13.45,27.5
13.6,26.5
12.8,27.35
12.4,27.85
12.3,28.4
12.2,28.65
13.4,25.1
12.95,25.95
788points.txt完整文件:下载
代码实现
# -*- coding: utf-8 -*-
__author__ = 'Wsine'
import numpy as np
import matplotlib.pyplot as plt
import math
import time
UNCLASSIFIED = False
NOISE = 0
def loadDataSet(fileName, splitChar='\t'):
"""
输入:文件名
输出:数据集
描述:从文件读入数据集
"""
dataSet = []
with open(fileName) as fr:
for line in fr.readlines():
curline = line.strip().split(splitChar)
fltline = list(map(float, curline))
dataSet.append(fltline)
return dataSet
def dist(a, b):
"""
输入:向量A, 向量B
输出:两个向量的欧式距离
"""
return math.sqrt(np.power(a - b, 2).sum())
def eps_neighbor(a, b, eps):
"""
输入:向量A, 向量B
输出:是否在eps范围内
"""
return dist(a, b) < eps
def region_query(data, pointId, eps):
"""
输入:数据集, 查询点id, 半径大小
输出:在eps范围内的点的id
"""
nPoints = data.shape[1]
seeds = []
for i in range(nPoints):
if eps_neighbor(data[:, pointId], data[:, i], eps):
seeds.append(i)
return seeds
def expand_cluster(data, clusterResult, pointId, clusterId, eps, minPts):
"""
输入:数据集, 分类结果, 待分类点id, 簇id, 半径大小, 最小点个数
输出:能否成功分类
"""
seeds = region_query(data, pointId, eps)
if len(seeds) < minPts: # 不满足minPts条件的为噪声点
clusterResult[pointId] = NOISE
return False
else:
clusterResult[pointId] = clusterId # 划分到该簇
for seedId in seeds:
clusterResult[seedId] = clusterId
while len(seeds) > 0: # 持续扩张
currentPoint = seeds[0]
queryResults = region_query(data, currentPoint, eps)
if len(queryResults) >= minPts:
for i in range(len(queryResults)):
resultPoint = queryResults[i]
if clusterResult[resultPoint] == UNCLASSIFIED:
seeds.append(resultPoint)
clusterResult[resultPoint] = clusterId
elif clusterResult[resultPoint] == NOISE:
clusterResult[resultPoint] = clusterId
seeds = seeds[1:]
return True
def dbscan(data, eps, minPts):
"""
输入:数据集, 半径大小, 最小点个数
输出:分类簇id
"""
clusterId = 1
nPoints = data.shape[1]
clusterResult = [UNCLASSIFIED] * nPoints
for pointId in range(nPoints):
point = data[:, pointId]
if clusterResult[pointId] == UNCLASSIFIED:
if expand_cluster(data, clusterResult, pointId, clusterId, eps, minPts):
clusterId = clusterId + 1
return clusterResult, clusterId - 1
def plotFeature(data, clusters, clusterNum):
nPoints = data.shape[1]
matClusters = np.mat(clusters).transpose()
fig = plt.figure()
scatterColors = ['black', 'blue', 'green', 'yellow', 'red', 'purple', 'orange', 'brown']
ax = fig.add_subplot(111)
for i in range(clusterNum + 1):
colorSytle = scatterColors[i % len(scatterColors)]
subCluster = data[:, np.nonzero(matClusters[:, 0].A == i)]
ax.scatter(subCluster[0, :].flatten().A[0], subCluster[1, :].flatten().A[0], c=colorSytle, s=50)
def main():
dataSet = loadDataSet('788points.txt', splitChar=',')
dataSet = np.mat(dataSet).transpose()
# print(dataSet)
clusters, clusterNum = dbscan(dataSet, 2, 15)
print("cluster Numbers = ", clusterNum)
# print(clusters)
plotFeature(dataSet, clusters, clusterNum)
if __name__ == '__main__':
start = time.clock()
main()
end = time.clock()
print('finish all in %s' % str(end - start))
plt.show()
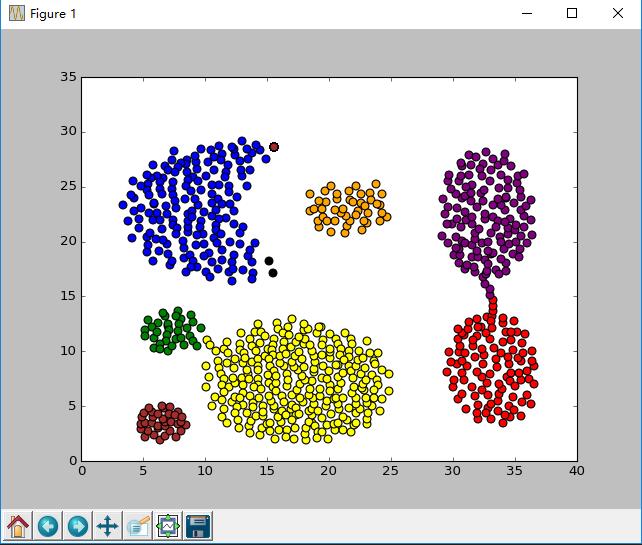
输出样例
cluster Numbers = 7
finish all in 32.712135628590794
Python机器学习——DBSCAN聚类
密度聚类(Density-based Clustering)假设聚类结构能够通过样本分布的紧密程度来确定.DBSCAN是常用的密度聚类算法,它通过一组邻域参数(ϵϵ,MinPtsMinPts)来描述样 ...
Python实现DBSCAN聚类算法(简单样例测试)
发现高密度的核心样品并从中膨胀团簇. Python代码如下: # -*- coding: utf-8 -*- """ Demo of DBSCAN clustering ...
密度聚类 - DBSCAN算法
参考资料:python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan import numpy as np from sklearn.cluster impo ...
(数据科学学习手札15)DBSCAN密度聚类法原理简介&;Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
DBSCAN——python实现
# -*- coding: utf-8 -*- from matplotlib.pyplot import * from collections import defaultdict import r ...
挑子学习笔记:DBSCAN算法的python实现
转载请标明出处:https://www.cnblogs.com/tiaozistudy/p/dbscan_algorithm.html DBSCAN(Density-Based Spatial Clu ...
[MCM] K-mean聚类与DBSCAN聚类 Python
import matplotlib.pyplot as plt X=[56.70466067,56.70466067,56.70466067,56.70466067,56.70466067,58.03 ...
吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
随机推荐
[转]在Ubuntu 14.04安装和使用Docker
在Ubuntu 14.04安装和使用Docker 作者:chszs,版权所有,未经同意,不得转载.博主主页:http://blog.csdn.net/chszs Docker是一个开源软件,它可以把一 ...
关于ASP.NET或VS2005 搭建三层架构的理解
最近想学习ASP.NET建网站,关于ASP.NET或VS2005 搭建三层架构的理解,网上摘录了一些资料,对于第(2)点的讲解让我理解印象深刻,如下: (1)为何使用N层架构? 因为每一层都可以在仅仅 ...
apache 配置https
1.生成密钥# openssl genrsa 1024 > server.key这是用128位rsa算法生成密钥,并保存到server.key文件 2.生成证书请求文件# openssl req ...
(理论篇)53个要点提高PHP编程效率
用单引号代替双引号来包含字符串,这样做会更快一些.因为php会在双引号包围的字符串中搜寻变量,单引号则不会,注意:只有echo能这么做,它是一种可以把多个字符串当作参数的"函数"( ...
Sikuli简介
Sikuli是利用屏幕上能够看到的图型做自动化,能够通过这个手段来识别和控制元素,非常适合和Selenium和Robot Framework一起结合起来做自动化. 1.Sikuli主页 http:// ...
JAVA中,JSON MAP LIST的相互转换
1 JSON包含对象和数组,对应于JAVA中的JSONObject,JSONArray 2 String 转JSON对象 JSONObject.fromObject("String" ...
protobuf NET使用
首先,开源项目地址为: protobuf NET的GITHUB地址 下载下来后,打开项目,找到目录:Core/protobuf-net,生成一下,然后就可以在bin里得到protobuf-net.dl ...
MySQL InnoDB 存储引擎探秘
在MySQL中InnoDB属于存储引擎层,并以插件的形式集成在数据库中.从MySQL5.5.8开始,InnoDB成为其默认的存储引擎.InnoDB存储引擎支持事务.其设计目标主要是面向OLTP的应用, ...
SharePoint如何配置Ipad跳转等问题
如何配置Ipad跳转 Apple iPad 设备上不支持 SharePoint 标准视图.用户可以改用移动视图在 iPad 设备上查看 SharePoint 内容.默认情况下,iPad 用户被重定向到 ...
asp.net core 依赖注入实现全过程粗略剖析(1)
转载请注明出处: https://home.cnblogs.com/u/zhiyong-ITNote/ 常用扩展方法 注入依赖服务: new ServiceCollection().AddSingle ...