一份Slide两张表格带你快速了解目标检测
关注公众号,发现CV技术之美
目录
P1:目标检测的需求与应用
P2:目标检测的相关定义
2.1 目标检测的定义
2.2 目标检测的核心问题
2.3 理想检测器的条件
2.4 从两个要求看关键挑战
从精度角度看挑战
从效率角度看挑战
一个挑战解决方法的例子
2.5 目标检测损失函数的发展
概述
IOU的发展变化
2.6 评价指标概述
常见指标概述
AP与mAP
2.7 数据集与标注软件
常见数据集
两大主流数据集
两大标注软件
三种常用标签格式
P3:方法回顾
3.1 目标检测算法发展的概览
发展历史轴(时间轴线图)
算法方法概览(思维导图)
3.2 传统的目标检测
基于特征的传统算法
基于分割的传统算法
传统算法的一般流程
经典的传统算法
传统算法总结
3.2 后处理算法NMS的发展
NMS概览
传统NMS
soft-NMS
Weighted-NMS
分类置信度优先NMS总结
IOU-Guided NMS(IOU-Net)
softer NMS
Adaptive NMS
DIOU-NMS
NMS总结
3.3 Anchor-based的目标检测
3.3.1 Two-stage方法
3.3.2 One-stage方法
3.3.3 Anchor-based总结
3.4 Anchor-free的目标检测
3.4.1 背景与定义
3.4.2 Anchor-free概述
3.4.3 早期探索型
3.4.4 基于关键点系列(源于姿态估计)
3.4.4 基于密集型系列(源于语义分割)
3.4.5 总结与思考
3.5 Transformer-based的目标检测
3.5.1 引言
3.5.2 概述
3.5.3 发展轴预览
3.5.4 CNN-backbone系列
3.5.5 Transformer-backone系列
3.6 总结与思考
P4:总结与思考
4.1 总结
4.2 思考
4.3 作业
注:本文仅供学习,未经同意勿转。

前言:本文梳理了目标检测的相关背景,定义,挑战,损失函数及模型方法的发展,为希望学习相关知识的新手提供了相对比较全面易懂的简要介绍,同时结合本笔者自身研究方向的知识展开了相关的思考。

P1:目标检测的需求与应用

第一部分我们主要回答两个问题:目标检测在实际中有哪些应用以及为什么我们需要研究它的原因。
问题1:在我们日常生活中有哪些可以想到的目标检测应用呢?

比如,打卡时需要人脸检测,购物时可以进行商品检测与文本提取,检血时可能需要细胞检测与病理检测,垃圾分类时可使用垃圾检测避免误分类现象等。

这些都说明:目标检测不管是在我们的日常生活领域,交通领域,工商业领域还是医学领域中都有着广大的应用需求与前景。再回到我们日常的校园生活中,学校的智能食堂及智能MY PASS门禁系统也都需要目标检测技术的支持。
问题2:为什么我们需要目标检测?

由此可见,目标检测存在于我们生活中的方方面面,为我们的生活生产提供了极大的便利与高效的技术支持。虽然目前目标检测技术已经有着众多的落地应用,算法也相对成熟并取得十分不错的效果,但它还有许多挑战值得我们去研究(这个我们后面会讲到)。正所谓:没有最好,只有更好。
P2:目标检测的相关定义

第二部分,我们主要会介绍目标检测的相关定义,挑战,经典的数据集以及相关的评价指标。在介绍数据集之前,我们会先结合目标检测的定义及挑战,以损失函数的角度概览目标检测的相关改进发展。从而使大家更好地理解后面所介绍的目标检测模型方法。
2.1 目标检测的定义
首先,目标检测在CV领域中所处的地位是怎么样的?与其它任务的区别是?
目标检测与分类、分割并称为CV的三大主要任务,他们之间的区别主要如下图所示。
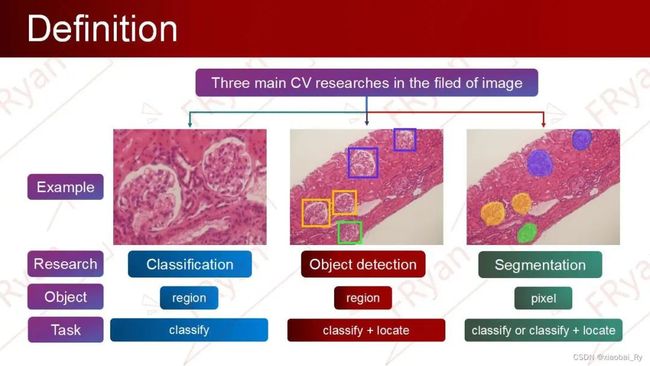
与分类的区别:相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
与分割的区别:分割分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
从任务的角度来看,目标检测可以看成是分类与分割任务的一座过度桥。这也是目标检测研究的重要性所在原因之一。
那到底什么是目标检测呢?或者说目标检测的任务是什么呢?
目标检测实际上就是找出图像中所有感兴趣的目标(object),并获得这一目标的类别信息和位置信息。因此,目标检测任务可以解耦成分类任务和定位任务。
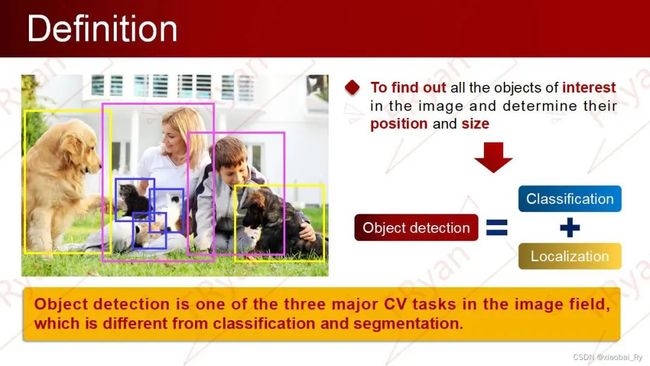
2.2 目标检测的核心问题
从目标的定位角度出发,目标检测需要解决的核心问题主要有3个:

大小的多样性同一张图像上可能同时出现多个不同或相同的目标,他们之间的大小差异大
位置的任意性目标可以出现在图像的任意位置
形态的差异性同一物体目标的形态差异可能很大,目标可能有各种不同的形状
2.3 理想检测器的条件
那么对于一个理想的目标检测器,我们当然希望它能够在解决上述核心问题的前提下,具有高的准确度及效率。

因此,为了实现我们所想要的检测器,我们需要解决什么问题?或者说我们将会面临怎么样的挑战呢?
2.4 从两个要求看关键挑战
从精度角度看挑战
从高准确度的角度来看,在现实场景中常见的挑战主要有:
类内的差异性种类内自身材料、纹理、姿态等带来的多样性干扰,如黄色框图中椅子的制作材料及形态差异很大,但是它们都属于椅子的大类别
外部环境的干扰外部环境带来的噪声干扰,比如蓝色框中光照、迷雾、遮挡等带来的识别及回归挑战。

类间的相似性类间因纹理、姿态所带来的相似性干扰,比如黄色框图中是不同品种的动物,但是它们之间的差异又很小;这里实际上可以衍生为细粒度识别领域
集群小目标问题集群目标检测所面临的数量多,类别多样化的问题,比如行人检测,遥感检测等。

从效率角度看挑战
目标检测是一个非常接地气的实际应用技术,它通常需要应用在实时处理的场景之中,比如自动驾驶系统。而且它还有可能需要同时处理成千上万的数据。因此,除了考虑高准确度还需要考虑处理时间,占用内存,消耗流量等方面的效率问题。

那么面对上面的挑战,我们一般有什么方法去解决它呢?下面给出一个示例短暂快速的了解一番。
一个挑战解决方法的例子
在现实中常见的场景有小目标检测场景。我们认为小目标检测场景就很好的包含了上述所提及的所有可能的问题与挑战。对于低像素问题,多数研究采用图像重构方法来解决,对于易遮挡问题,大多研究通过上下文语义信息来辅助检测,对于小尺寸问题则通过尺度自适应变换来解决,对于大批量数据问题可通过降低参数来实现。

从任务上来看,目标检测的挑战是分类挑战与定位挑战的结合。对于两个挑战,我们应该如何去优化?
2.5 目标检测损失函数的发展
概述
对于两个挑战的优化,目标检测损失函数的发展可以由上图来概括。不管是分类任务还是定位任务都可能面临样本分布不均匀,数据分布不一致等问题,因此,后面所提出的优化损失函数也包含对这些问题的改善。比如,Focal loss和DR loss,AP loss,Balanced L1 loss都解决了不平衡的问题。其中:
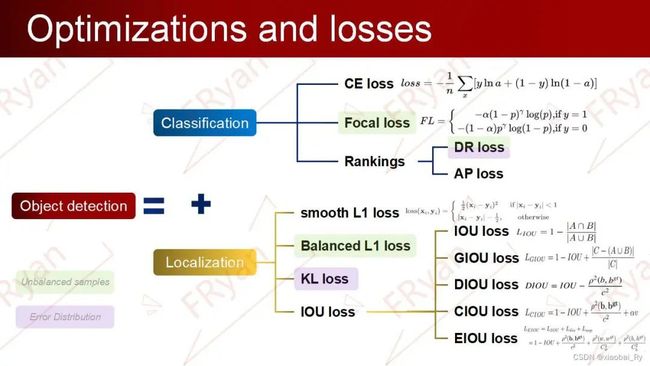
一般来说,样本量多的类型,模型更容易学习到其相对应的特征,反之,相反。所以Focal loss是通过改变模型对难易样本学习的权重来提高模型对不均衡样本的学习。
而DR loss和AP loss则主要是将分类问题转化为排序问题,从而避免正负样本不均衡的问题。
Balanced L1 loss解决的是定位上的平衡问题,主要是在找一个平衡的点,能让easy和hard的sample所占的梯度贡献差不多。
KL loss主要就是拉近两个分布之间的距离。
由于篇幅及时间的限制,我们主要的关注点是在IOU loss上(与后面讲的评价指标息息相关),因此这里我只对上面的损失函数发展做一个简单概述。
IOU的发展变化
目标检测在定位上的准确度会对模型分类的结果有所影响。因此,好的定位有利于模型精度的提高。在IOU Loss提出来之前,检测上有关候选框的回归主要是通过坐标的回归损失来优化。但很明显L1和L2 Loss存在比较大的问题:
L1 Loss的问题:损失函数对x的导数为常数,在训练后期,x很小时,如果learning rate 不变,损失函数会在稳定值附近波动,很难收敛到更高的精度。
L2 Loss的问题:损失函数对x的导数在x值很大时,其导数也非常大,在训练初期不稳定。
而且,基于L1/L2 Loss的坐标回归不具有尺度不变性,且并没有将四个坐标之间的相关性考虑进去。因此,像L1/L2 Loss直接的坐标回归实际上很难描述两框之间的相对位置关系。
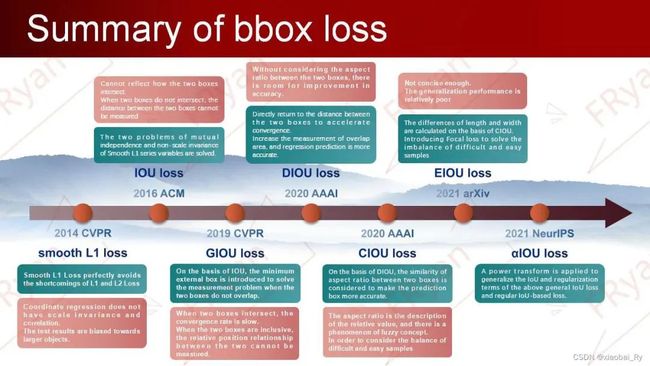
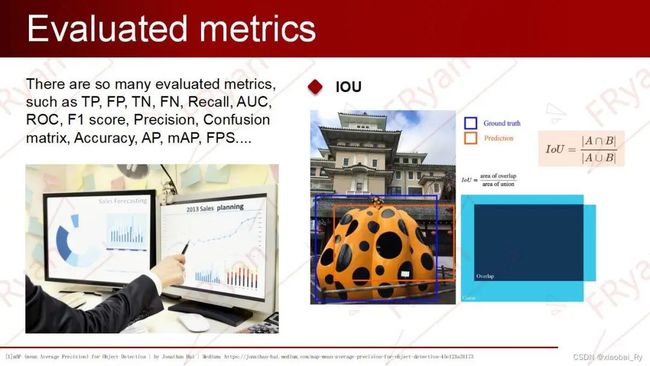
IOU
因此,在ACM2016的论文中提出了IOU loss,它将四个坐标点看成一个整体进行计算,具有尺度不变性(也就是对尺度不敏感)。IOU Loss的定义是先求出预测框和真实框之间的交集和并集之比,再求负对数,但是在实际使用中我们常常将IOU Loss写成1-IOU。如果两个框重合则交并比等于1,Loss为0说明重合度非常高。因此,IOU的取值范围为[0,1]。

虽然IOU Loss虽然解决了Smooth L1系列变量相互独立和不具有尺度不变性的两大问题,但是它也存在两个问题:

当预测框和目标框不相交时,即IOU(A,B)=0时,不能反映A,B距离的远近,此时损失函数不可导,IOU Loss 无法优化两个框不相交的情况。
如上图三个框,假设预测框和目标框的大小都确定,只要两个框的相交值是确定的,即其IoU值相同时,IOU值不能反映两个框是如何相交的。
因此,IOU Loss虽然比较简单直观,但它不是最好的选择!
GIOU
针对IOU无法反映两个框是如何相交的问题,GIOU通过引入预测框和真实框的最小外接矩形(类似于图像处理中的闭包区域)来获取预测框、真实框在闭包区域中的比重。这样子,GIOU不仅可以关注重叠区域,还可以关注其他非重合区域,能比较好的反映两个框在闭包区域中的相交情况。

从公式上来看,GIOU是一种IOU的下界,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1。因此,与IOU相比,GIoU是一个比较好的距离度量指标。

DIOU
虽然GIOU通过引入闭包区域缓解了预测框与真实框相交位置的衡量问题,但其实际上仍存在两个问题:

对每个预测框与真实框均要去计算最小外接矩形,计算及收敛速度受到限制。【能不能直接最小化距离?,以达到更快的速度?】
当预测框在真实框内部时,GIOU退化为IOU,也无法区分相对位置关系。【能不能在两者有重叠时甚至包含时回归更加准确】
因此,考虑到GIOU的缺点,DIOU在IOU的基础上直接回归两个框中心点的欧式距离==,加速了收敛速度。DIOU的惩罚项是基于中心点的距离和对角线距离的比值。这样就避免了GIOU在两框距离较远时产生较大闭包时所造成的Loss值较大而难以优化的情况。

CIOU
虽然DIOU Loss通过中心点回归缓解了两框距离较远时难优化的问题,但DIoU Loss仍存在两框中心点重合,但宽高比不同时,DIOU Loss退化为IOU Loss的问题。因此,为了得到更加精准的预测框,CIOU在DIOU的基础上增加了一个影响因子,即增加了预测框与真实框之间长宽比的一致性的考量(v值)。

CIOU Loss虽然考虑了边界框回归的重叠面积、中心点距离及长宽比。但是其公式中的v反映的时长宽比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化。

EIOU
因此,EIOU在CIOU的基础上将长宽比拆开,分别计算长、宽的差异,同时引入Fcoal loss解决了难易样本不平衡的问题。

IOU loss的总结

2.6 评价指标概述
常见指标概述
前面说IOU与目标检测评价息息相关,主要是因为目标检测在进行性能比较时一般会说明对应的IOU阈值。那目前大家一般采用的评价指标有哪些呢?从目标检测的两个要求来看(精度和效率):一般精度大家都会计算各种IOU阈值下的mAP值和F1分数等。mAP的计算依赖于TP,FP,TN,FN等的计算,也就是依赖Precision和Recall来计算的。因为大家或多或少都会接触过Pr和Re的计算,这里我就不详细说明了。但mAP我在下一页中会介绍。而效率大家一般都会比较FPS和参数量。当然,一般论文在这里都必须指明是在什么样的硬件条件下进行实验比较的。
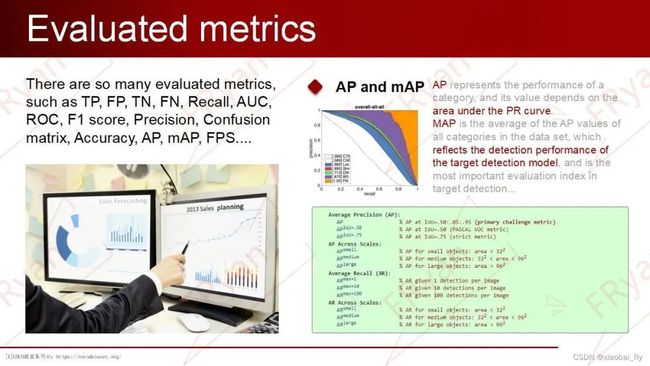
主要评价指标:MAP(平均准确度均值,精度评价) 检测速度(FPS即每秒处理的图片数量或者处理每张图片所需的时间,当然必须在同一硬件条件下进行比较) 召回率(Recall)= (TP)/(TP+FN):每个类被正确分类的概率
其他性能指标:准确率 (Accuracy) 精确率(Precision) 混淆矩阵 (Confusion Matrix) precision-recall曲线 平均正确率(AP) ROC曲线(Receiver Operating Characteristic) AUC曲线(Area Under Curve)即为ROC曲线下的面积 交除并IOU(Intersection Over Union)预测框A和真实框B的重叠程度 非极大值抑制(NMS)
作为目标检测的主要指标,mAP指的是什么?
AP与mAP
AP是指PR曲线下(调整置信度阈值变化,得到不同置信度阈值下Re与Pr之间的关系)的面积,是判断改类别分类器表现性能好坏的标准。其表现了分类器在Pr与Re之间的权衡,当AP值较高~=PR曲线向右上方拟合,也就说明Recall在增长的同时Precision也稳定在一个较高的值附近。
mAP值是AP的均值,代表的是整个检测模型的表现性能。
2.7 数据集与标注软件
常见数据集
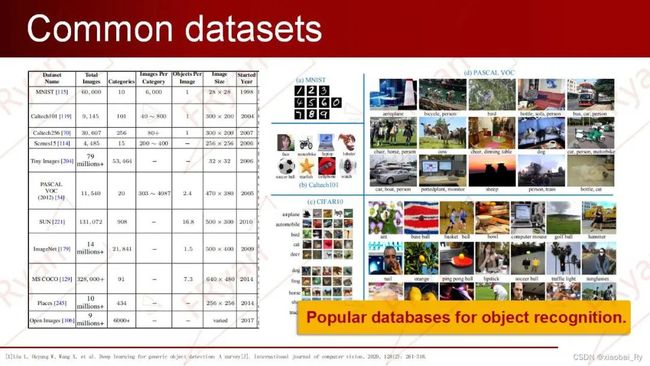
从应用的角度出发,模型的设计与数据息息相关的。有关目标检测公开的数据集也有很多,比如最初的MNIST、ImageNet等数据集。这些数据集的大小、数量及主要面临的挑战都大不相同。
两大主流数据集
虽然公开的数据集很多,但目前最为流行的经典数据集还是COCO和PASCAL VOC。一般做通用任务或backbone时,我们都至少需要比较这两个数据集中的一个。

两大标注软件
为便于COCO和PASCAL VOC数据集的采集制作,目标检测领域有两款开源的主流标注软件:labelme和labelImg。这两大软件都有对应的python包,所生成的数据格式为常见的三种数据集格式VOC格式,COCO格式和YOLO格式。

三种常用标签格式
这三种数据格式的区别主要在于标签文件类型和bbox格式。VOC采用的是图像文件与xml标签文件,而COCO采用的是json格式,YOLO采用的是txt文本格式。如果大家有接触过一点前端的知识或者有接触过目标检测,应该是知道这三种标签文件的优劣势所在。【个人看法:json格式可以很好的将各种数据集成到一个文件中去,具有占用空间小,检索迅速的优势。而txt文本格式则具有简单易处理的有点。xml格式介于两者之间吧】

这里为什么讲数据格式,是为了方便大家快速的了解目前经典开源框架大多会采用什么样的数据书写模式,以便于大家在探索目标检测领域时能够快速的利用目前现有的代码资源。但不管是什么样的数据格式,最主要的数据导入完全解决于自己习惯的代码书写。

P3:方法回顾

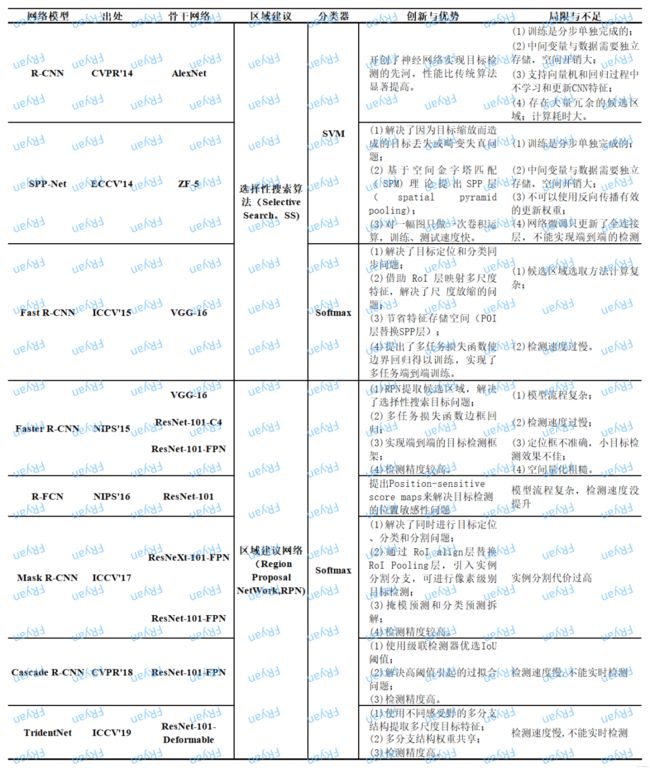
第三部分,我们将系统地回顾一下目标检测的方法,包括传统的目标检测方法和基于深度学习的方法。虽然传统的目标检测方法现在比较少用,但我们认为有必要了解其手工设计的特征,因为现在在工业和医学领域这些手工特征与深度学习方法的融合也带来了不错的效果。当然,我们的汇报仍然是以基于深度学习的方法为主。==这里由于时间限制,而且anchor-based的方法已经有很多博文都有介绍,我就不详细介绍(只给出两张我自己整理的表单来带大家快速了解一下)==
3.1 目标检测算法发展的概览
发展历史轴(时间轴线图)
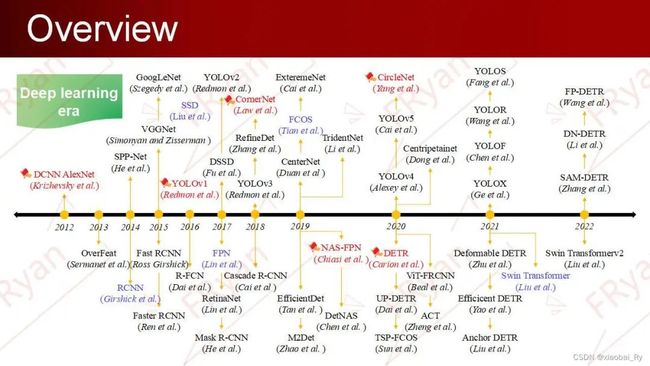
目标检测的算法发展可以追溯到很久之前,这里我根据前两年的综述论文加上这两年的发展也画了两个部分的相关模型发展轴。可以看到,目标检测算法在2012年前均采用传统算法进行处理。

但在2012年之后随着算力及数据的提升,大量的深度学习模型涌现。最开始的模型主要采用的是以RCNN为首的two-stage目标检测模型。但随着移动端对目标检测效率要求的提高,16年之后模型开始往以YOLO为首的one-stage模型发展。但前面两种模型都比较依赖anchor的设定,因此,为减少anchor对模型的影响,18年以后开始兴起了对以CornerNet为首的anchor-free研究。17年底谷歌推出了Transformers模型,随后在19年开始大火并快速地应用于CV领域。在20年时,Facebook AI团队首次将Transformers模型应用于目标检测领域,开启了目标检测新的研究浪潮,包括最近很火的Swin Transformer模型。
算法方法概览(思维导图)
从上面模型的发展来看,目标检测算法可以主要可以分为以下五类。其中,传统算法比较依赖于手工特征的设计。对Anchor based的方法,可以从两个角度来看待其模型的发展,一是训练模式,二是Anchor的形状。从训练模式来看的话,Anchor based的目标检测模型主要可以分为One-stage和Two-stage模型。One-stage模型因为检测速率较快的优点多用于移动端场景,而Two-stage模型因为检测精度较高的优点多用于精装设备场景。从Anchor形态来看,对于不同的物体用更加贴合其自身形态的anchor会更加精确。其中,矩形和多边形多用于遥感和文字检测场景,而椭圆及圆形多用于遥感和医学领域。

下图是我罗列出不同类型目标检测算法中比较经典的模型及算法,在后面的讲解中主要只讲解所提到的比较经典的方法。

注:虽然上图我把YOLO Family归到Anchor based去,但不是所有的YOLO衍生算法都是Anchor based,比如YOLO就是Anchor Free,这里只不过是为了介绍方便。其他类似。
3.2 传统的目标检测

基于传统的目标检测算法主要可以分为基于特征和基于分割两个方向。
基于特征的传统算法
其中,基于特征的目标检测算法主要是通过找到对象的某种属性(可以是手工设计的特征也可以是算法提取的抽象特征)来实现检测与识别。
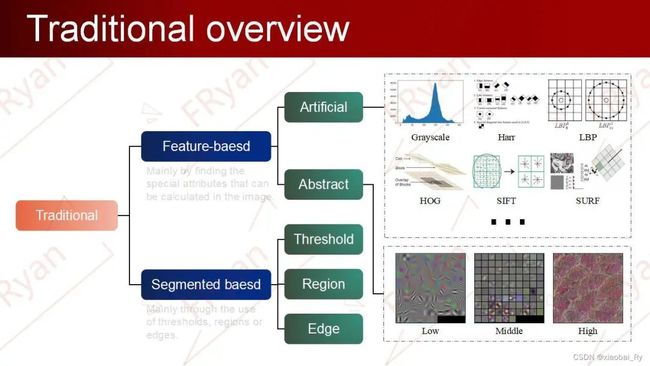
在传统的算法中,主要的特征如下图所示,有Harr特征、HOG特征、灰度特征、SIFT特征及SURF特征等。

基于分割的传统算法
而基于分割的目标检测算法则主要通过区域、颜色及边缘的特性来实现检测与识别。【对应的相关算法我PPT里面都有放,这里就不一一罗列啦】

传统算法的一般流程
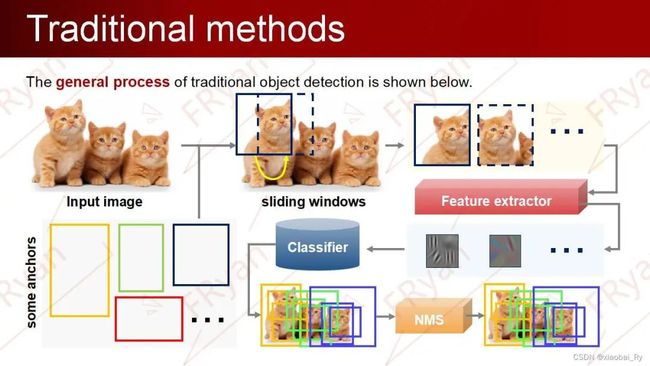
传统算法的一般处理流程包括下图的六个步骤,其主要的思路就是:

首先,利用滑动窗口或者选择性搜索等方法方法对一幅图像进行处理获取候选框;
其次,对每个框提取特征(Harr、HOG…), 判断是不是目标,若判定为目标则同时记录其位置坐标(x,y,w,h)–定位;
然后, 利用分类器(Adaboost、决策树)对目标进行分类–识别。
最后,对分类识别的结果进行一系列的后处理操作,比如说NMS(非极大值抑制)来去除掉多余的候选框,得到最佳的物体检测位置。
下图是传统算法的一个可视化示例:
经典的传统算法
经典的传统检测算法主要有Viola Jones检测器(人脸检测),HOG检测器(行人检测),基于部件的可变形模型(DPM,物体检测)这三种。

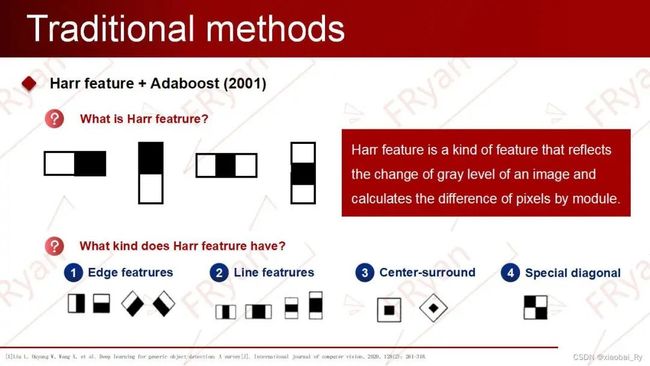
Harr+Adaboost
Viola Jones检测器由三个核心步骤组成,即Haar-like特征和积分图、Adaboost分类器以及级联分类器。

其中,Harr特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征,实际上就是一种梯度算子,主要可以分为线性特征、边缘特征、点特征(中心特征)和对角线特征。
而AdaBoost是"Adaptive Boosting"(自适应增强)的缩写,是一种以集成学习为核心思想的迭代算法,其自适应性在于前一个分类器分错的样本会被用来训练下一个分类器。因此,Adaboost算法基本原理就是通过alpha将多个Weak Classifier进行合理的结合,使其成为一个强分类器。如下图所示,AdaBoost在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。具体地,每一个训练样本data都被赋予一个权重,表明它被某个分类器选入训练集的概率。如果某个样本点已经被准确地分类,那么在构造下一个Weak Classifier的训练集时,它成为训练数据的概率就被降低;相反,如果某个样本点被误分类,那么它的权重就得到提高。通过这样的方式,AdaBoost方法能“聚焦”到难样本上。虽然AdaBoost方法对噪声及异常数据比较敏感,但与当时的其他算法相比,比较不容易过拟合。

在集成算法一般分为三种:Bagging,Boosting,Stacking(我们可以把它简单地看成并行,串行和树型)。Bagging是把各个基模型的结果组织起来,取一个折中的结果;Boosting是根据旧模型中的错误来训练新模型,层层改进;Stacking是把基模型组织起来,注意不是组织结果,而是组织基模型本身,该方法看起来更灵活,也更复杂。
HOG + SVM
梯度直方图HOG(Histogram of Oriented Gradients)是法国人Dalal在2005年CVPR会议上提出的特征提取算法,并将其与 SVM 配合,用于行人检测。
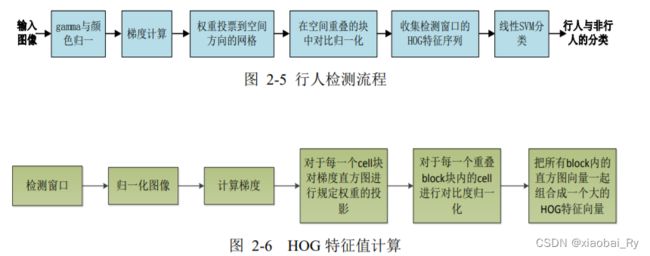
HOG检测器是沿用了最原始的多尺度金字塔+滑窗的思路进行检测。为了检测不同大小的目标,通常会固定检测器窗口的大小,并逐次对图像进行缩放构建多尺度图像金字塔。同时,为了兼顾速度和性能,HOG检测器采用的分类器通常为线性分类器或级联决策分类器等。

其中,HOG特征具有以下的优缺点。
HOG特征的优点:
能较好地捕捉局部形状信息;
对几何和光学变化都有很好的不变性;
HOG隐含了该块与检测窗口之间的空间位置关系。
HOG特征的缺点:
特征描述子获取过程复杂,维数较高,实时性差;
很难处理遮挡问题;
由于梯度的性质,HOG对噪点相当敏感,因此,在实际应用中,在block和Cell划分之后,对于得到各个区域通常需要通过高斯平滑去除噪点。
DPM
DPM特征DPM特征的设计可以看作HOG特征的改进版。它取消了HOG中的块(Block)的设计,只保留了单元(Cell)的划分, 并增加了有符号梯度和无符号梯度的梯度方向区分,如下图所示。

DPM流程DPM算法针对目标的多视角问题,采用了多组件(Component)的策略,针对目标本身的形变问题,采用了基于图结构(Pictorial Structure)的部件模型策略。此外,将样本的所属的模型类别,部件模型的位置等作为潜变量(Latent Variable),采用多示例学习(Multiple-instance Learning)来自动确定。具体的流程如下图所示:

对于任意一张输入图像,提取其DPM特征图,然后将原始图像进行高斯金字塔上采样放大原图像,然后提取其DPM特征图(2倍分辨率)。将原始图像的DPM特征图和训练好的Root filter做卷积操作,从而得到Root filter的响应图。对于2倍图像的DPM特征图,和训练好的Part filter做卷积操作,从而得到Part filter的响应图。然后对其精细高斯金字塔的下采样操作。这样Root filter的响应图和Part filter的响应图就具有相同的分辨率了。然后将其进行加权平均,得到最终的响应图。亮度越大表示响应值越大。
DPM的主要思想可简单理解为将传统目标检测算法中对目标整体的检测问题拆分并转化为对模型各个部件的检测问题,然后将各个部件的检测结果进行聚合得到最终的检测结果,即“从整体到部分,再从部分到整体”的一个过程。上右图为某一尺度下的行人检测流程,其中,左侧为根模型的检测流程,跟模型响应的图中,越亮的区域代表响应得分越高;右侧为各部件模型的检测过程。首先,将特征图像与模型进行匹配得到部件模型响应图。然后,进行响应变换:以锚点为参考位置,综合考虑部件模型与特征的匹配程度和部件模型相对理想位置的偏离损失,得到的最优的部件模型位置和响应得分。
DPM vs HOG

DPM算法优点:方法直观简单;运算速度块;适应动物变形;
DPM算法缺点:
性能一般,无法适应大幅度的旋转,稳定性很差;
激励特征是人为设计的,工作量大;这种方法不具有普适性,因为用来检测人的激励模板不能拿去检测小猫或者小狗,所以在每做一种物件的探测的时候,都需要人工来设计激励模板,为了获得比较好的探测效果,需要花大量时间去做一些设计,工作量很大。
传统算法总结

传统特征虽然在某些方面可以帮助深度学习模型精度的提高,但对于传统检测算法来说,特征的设计与选择极大程度上依赖于人工,其准确度、客观性、鲁棒性与泛化性都受到了一定的制约。同时,传统的算法大多采用滑动窗口算法,其计算时间效率低下,为多流程的步骤处理,处理复杂且准确度低。因此,随着算力及数据的发展,传统的检测算法明显无法满足人们的需求。
3.2 后处理算法NMS的发展
前面我们讲了传统检测在分类器识别之后还需要进行后处理操作,实际上在后面前期发展的深度学习模型也同样需要后处理步骤。因此,在进入深度学习模块的讲述前,我将回顾一下目前目标检测中最常见的后处理算法NMS的相关发展。

NMS概览
从时间的概览上,NMS算法的及其变体主要有六种。

传统NMS
传统的NMS首先根据类别置信度得分对所有的bbox进行降序排列建表,然后将每个类别中置信度最高的bbox作为可靠的bbox,并分别计算其与剩余bbox的IOU,仅保留IOU小于设定阈值的bbox,以此往复循环直到结束。

因此,从公式看,NMS主要有两个度量指标:
分类置信度(NMS中分类置信度越高的框须优先考虑,其他与其重叠超过一定程度的框则要被舍弃)
IOU(在评价两个边框的重合程度时,NMS采用IOU指标。若两框的IoU超过一定阈值时,则得分低的框会被舍弃。)
虽然NMS可以处理掉较多的冗余框,但传统的NMS存在以下局限性:
循环步骤,GPU难以并行处理,运算效率低
以分类置信度为优先衡量指标 分类置信度高的定位不一定最准,降低了模型的定位准确度
直接提高阈值暴力去除bbox 将得分较低的边框强制性地去掉,如果物体出现较为密集时,本身属于两个物体的边框,其中得分较低的框就很有可能被抑制掉,从而降低了模型的召回率,且阈值设定完全依赖自身经验。
soft-NMS
NMS设定的局限性显然,对于IOU≥NMS阈值的相邻框,传统NMS的做法是将其得分暴力置0,相当于被舍弃掉了,这就有可能造成边框的漏检,尤其是有遮挡的场景。
Soft-NMS解决方案对IOU大于阈值的边框,Soft-NMS采取得分惩罚机制,降低该边框的得分,即使用一个与IoU正相关的惩罚函数对得分进行惩罚。当邻居检测框b与当前框M有大的IoU时,它更应该被抑制,因此分数更低。而远处的框不受影响。

从实验结果来看的话,soft-NMS(红色)能够比较好的缓解掉传统NMS(蓝色)暴力剔除所带来的物体遮挡漏检情况。
Soft-NMS的类型(1)线性衰减型(不连续,会发生跳变,导致检测结果产生较大的波动);(2)指数高斯型(更为稳定、连续、光滑)
Soft-NMS的局限性

仍采用循环遍历处理模式,而且它的运算效率比Traditional NMS更低。
对双阶段算法友好,但在一些单阶段算法上可能失效。(所以看soft-NMS论文时会发现它只在two-stage模型上比较,可能是因为one-stage模型在16年才提出来,之后才开始大火)soft-NMS也是一种贪心算法,并不能保证找到全局最优的检测框分数重置。
遮挡情况下,如果存在location与分类置信度不一致的情况,则可能导致location好而分类置信度低的框比location差分类置信度高的框惩罚更多。
评判指标是IoU,即只考虑两个框的重叠面积,这对描述box重叠关系或许不够全面。
Weighted-NMS
如果前面讲的soft NMS是通过抑制机制来改善剔除结果(降低超阈值的得分策略),那么Weighted NMS(W-NMS)则是从极大值这个方面进行改进。W-NMS认为Traditional NMS每次迭代所选出的最大得分框未必是精确定位的,冗余框也有可能是定位良好的。因此,W-NMS通过分类置信度与IOU来对同类物体所有的边框坐标进行加权平均,并归一化。其中,加权平均的对象包括M自身以及IoU≥NMS阈值的相邻框。

优点:Weighted NMS通常能够获得更高的Precision和Recall,一般来说,只要NMS阈值选取得当,Weighted NMS均能稳定提高AP与AR。
缺点:(1)仍为顺序处理模式,且运算效率比Traditional NMS更低。(2)加权因子是IOU与得分,前者只考虑两个框的重叠面积;而后者受到定位与得分不一致问题的限制。
分类置信度优先NMS总结
NMS、soft-NMS及Weighted NMS的局限性:
都是以分类置信度优先的NMS,未考虑定位置信度,即没有考虑定位与分类得分可能出现不一致的情况,特别是框的边界有模棱两可的情形时。

采用的都是传统的IOU,只考虑两包围盒子之间的重叠率,未能充分反映两包围盒子之间相对位置关系。
IOU-Guided NMS(IOU-Net)
前面所提到的NMS方法只将分类的预测值作为边框排序的依据。然而在某些场景下,分类预测值高的边框不一定拥有与真实框最接近的位置,因此这种标准不平衡可能会导致更为准确的边框被抑制掉。

之前NMS的局限性:
分类准确率和定位准确率的误匹配:从左下图看,IOU与定位置信度高度相关(0.617),而与分类置信度几乎无关(0.217)。
边界框回归的非单调性与非可解释性:缺乏localization confidence使得被广泛使用的边界框回归方法缺少可解释性或可预测性。先前的工作曾指出bounding box迭代回归的非单调性,也就是说,应用多次之后bounding box回归可能有损bounding box定位表现。
在此背景下,旷视IOU-Net论文提出了IoU-Guided NMS,即一个预测框与真实框IOU的预测分支来学习定位置信度,进而使用定位置信度来引导NMS的学习。具体来说,就是使用定位置信度作为NMS的筛选依据,每次迭代挑选出最大定位置信度的框M,然后将IOU≥NMS阈值的相邻框剔除,但把冗余框及其自身的最大分类得分直接赋予M。因此,,最终输出的框必定是同时具有最大分类得分与最大定位置信度的框。

IOU-Guided NMS优点:
通过该预测分支解决了NMS过程中分类置信度与定位置信度之间的不一致,可以与当前的物体检测框架一起端到端地训练,在几乎不影响前向速度的前提下,有效提升了物体检测的精度。
IoU-Guided NMS有助于提高严格指标下的精度,如AP75, AP90。(在IOU阈值较高时IOU-guided NMS算法的优势还是比较明显的(比如AP90),原因就在于IOU阈值较高时需要预测框的坐标更加准确才能有较高的AP值,这正好和IOU-guided NMS的出发点吻合。)

IOU-Guided NMS缺点:
顺序处理的模式,运算效率与Traditional NMS相同。
需要额外添加IoU预测分支,造成计算开销。
评判标准为IOU,即只考虑两个框的重叠面积。
softer NMS
总体概览从Softer-NMS的公式来看,Softer-NMS可以看成是前面三种NMS变体的结合,即:其极大值的选择/设定采用了与类似Weighted NMS(加权平均)的方差加权平均操作,其加权的方式采用了类似soft NMS的评分惩罚机制(受Soft-NMS启发,离得越近,不确定性越低,会分配更高的权重),最后,它的网络构建思路与IOU-Guided NMS相类似。
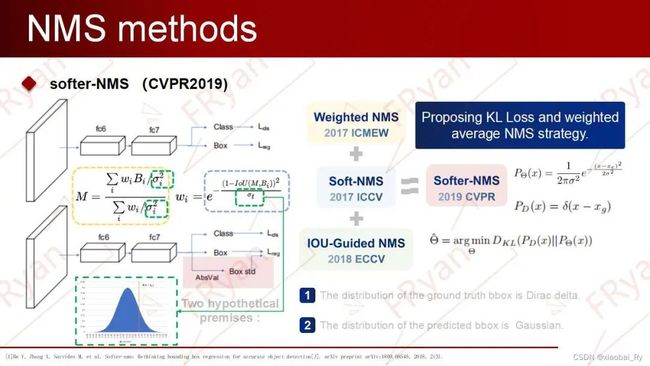
与IOU-Guided NMS区别Softer-NMS与IOU-Guided NMS的出发点同样是解决定位与分类置信度之间非正相关的问题,所采用的思路一样是增加一个定位置信度的预测,但不一样的是前面提到的IOU-Guided NMS采用IOU作为定位置信度来优先排序,而这里Softer-NMS则是通过定位分布的方差来拉近预测边框与真实物体分布,即IOU-Guided NMS采用IOU作为定位置信度而Softer-NMS采用坐标方差作为定位置信度,具体的做法就是通过KL散度来判别两个分布的相似性。其中,Softer NMS论文中有两个先验假设:(1)Bounding box的是高斯分布 (2)ground truth bounding box是狄拉克delta分布(即标准方差为0的高斯分布极限)。

Softer-NMS的优点:
增加了定位置信度的预测,是定位回归更加准确与合理。
使用便捷,可以与Traditional NMS或Soft-NMS结合使用,得到更高的AP与AR。
Softer-NMS的缺点:
顺序处理模式,且运算效率比Traditional NMS更低。
额外增加了定位置信度预测的支路来预测定位方差,造成计算开销。
评判标准是IoU,即只考虑两个框的重叠面积,这对描述box重叠关系或许不够全面。
Adaptive NMS
背景Adaptive NMS是在行人检测问题上来对soft NMS改进的一种自适应阈值处理方法(==即在软化得分的前提下继续软化阈值==)。行人检测任务中,一个最大的问题就是目标在常规场景下一般处于密集状态。如何在解决密集检测以及密集检测之中目标之间相互遮挡的问题是行人检测的一大问题。在以往的研究中,NMS都采用单一阈值的处理方式。使用单一阈值的NMS会面临以下困境:较低的阈值会导致丢失高度重叠的对象(图中蓝框是未检测出来的目标),而较高的阈值会导致更多的误报(红框是检测错误的目标)。
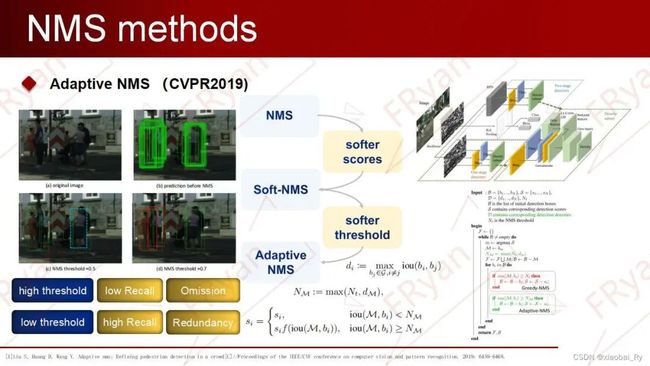
所以,在密集检测场景中,我们希望:(1)在目标密集时,可以使用较大的阈值以保证更高的召回率;(2)在目标稀疏时,可以使用较小的阈值来剔除掉更多冗余的检测框。
思路与方法基于上述背景,Adaptive NMS应用了动态抑制策略,通过设计计了一个Density-subnet网络预测目标周边的密集和稀疏的程度,引入密度监督信息,使阈值随着目标周边的密稀程度而对应呈现上升或衰减。具体做法:
当邻框远离M时(即IoU
对于高度重叠的相邻检测,抑制策略不仅取决于与M的重叠,还取决于M是否位于拥挤区域。
当M处于密集区域时(即Nm>Nt),目标密度dM作为NMS的抑制阈值;若M处于密集区域,其高度重叠的相邻框很可能是另一目标的真正框,因此,应该分配较轻的惩罚或保留。
当M处于稀疏区域时(即Nm≤Nt),初始阈值Nt作为NMS的抑制阈值。若M处于稀疏区域,惩罚应该更高以修剪误报。

Adaptive NMS优点:
可以与前面所述的各种NMS结合使用。
对遮挡案例更加友好。
双阶段和单阶段的检测器都有效果。(CVPR2019 Oral)
Adaptive NMS缺点:
与Soft-NMS结合使用,效果可能倒退 (受低分检测框的影响)。
顺序处理模式,运算效率低。
需要额外添加密度预测模块,造成计算开销。
评判标准是IoU,即只考虑两个框的重叠面积,这对描述box重叠关系或许不够全面。
DIOU-NMS
在以往的NMS中使用的评判指标都是IOU,但就像前面对IOU的介绍,IOU虽然简单直观,但它只考虑两个框的重叠面积(比如下图第一种相比于第三种越不太可能是冗余框)。因此,后面研究相继耶提出了许多IOU变体来使两框之间的相对位置关系描述更加准确。比如DIOU-NMS就直接将IOU指标换为DIOU。当然结合前面对IOU的介绍,这种换掉IOU指标的NMS变体也可以有很多。

DIOU-NMS优点:
从几何直观的角度,将中心点考虑进来有助于缓解遮挡案例。
可以与前述NMS变体结合使用。
保持NMS阈值不变的情况下,必然能够获得更高recall (因为保留的框增多了)。
DIOU-NMS缺点:顺序处理模式,计算更复杂,运算效率更低。
NMS总结
实际上NMS的变体不止上面提到的方法,还有其他的变体,比如从文本场景中,NMS变体主要是一种基于shape的改变;而在遥感等实时场景中,NMS变体主要是加速策略的改变,提高的的计算效率。

从以上NMS的介绍,可以看出:目前,NMS对传统NMS算法的改进主要是从极大值的选择机制,抑制冗余框的机制,IOU的评价指标,anchor的形态、位置及其所处的环境(周边的密度)等方面来进行优化。虽然NMS算法一直在不断的优化,但未来更主流的方式是nms-free。
3.3 Anchor-based的目标检测
由于时间限,而且目前有关anchor-based(one-stage, two-stage)方法的介绍已经很多了,这里就先放两张自己整理的表单吧
3.3.1 Two-stage方法
3.3.2 One-stage方法

3.3.3 Anchor-based总结
从上述总结的目标检测长短板及性能比较的图例来看,由于Two Stage目标检测模型事先基于候选框进行特征提取,其在候选框的定位精度与检测精度方面一般高于 One Stage 模型。虽然随着 Two Stage 模型的发展,其在检测速度方面上有所提升,但由于其复杂的 Two Stage 网络架构,以及其对候选框的提取等操作,使得其与 One Stage 模型 相比,仍具有检测速度慢、计算量庞大的局限性,从而难以落地与实时检测的移动设备。而 One Stage 目标检测模型则由于结构简单直接的优势在检测速度及实时性表现出优异的性能。虽然随着 One Stage 的发展,其在检测精度方面有所改进,但由于其对局部特征的关注较少,所以其在复杂背景场景、小目标场景或多目标场景的检测精度较低。
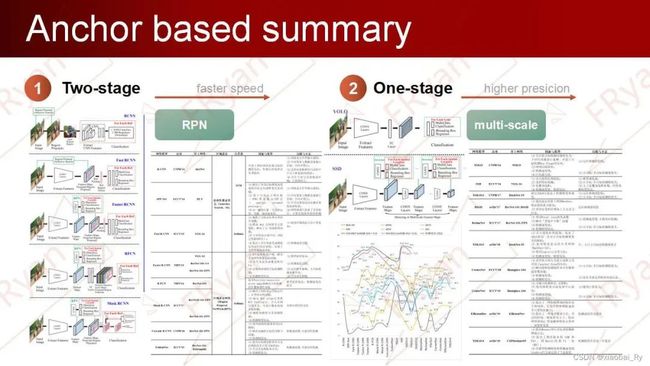
但不管是 One Stage 还是 Two Stage 模型,目标检测的方向均是朝着网络模型更简化,特征描述更简单、检测速度更实时、检测精度更准确与算法可解释的方向发展的。
3.4 Anchor-free的目标检测

3.4.1 背景与定义
前面我们讲的都是anchor-based方法,那么anchor-based methods有什么特征?anchor-based methods的特征就是在同一像素点上生成多个不同大小和比例的候选框(one-stage模型通常采用滑窗(聚类)等式生成,而two-stage模型更多的是采用RPN来生成),并对其进行筛选,然后再进行分类和回归。
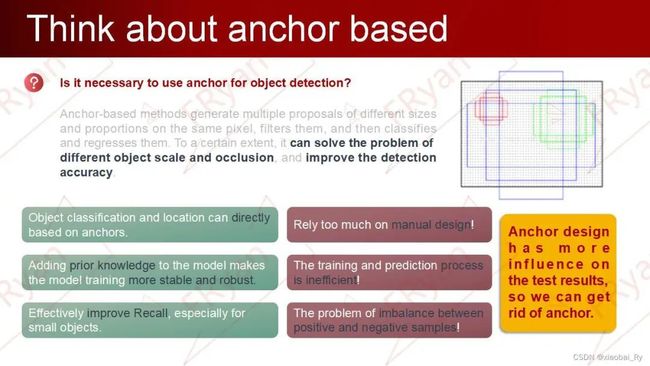
anchor能为检测算法带来什么样的好处?又会带来什么样的限制呢?
anchor的好处
简单直接 网络可直接在anchor上进行分类及回归任务。
更高的分辨率及更丰富的特征
引入先验知识,使模型训练更加稳定和鲁棒 如YOLOv3中采用K-means算法得到的anchor实际上就引入了样本分布的先验知识。因此,在预先设定的anchor(含先验知识)中,模型在prediction(尤其是regression)时,它的值域变化范围实际上是比较小的,这就使得anchor-based的网络更加容易训练也更加稳定。
可以提高召回率,尤其是对小目标检测
一定程度上解决了物体遮挡和尺度不一致的问题。
anchor的局限
依赖过多的手动设计!
训练和预测过程过于低效!
正负样本不均衡问题!
既然anchor的设计(初始化)对网络模型的影响这么大,我们是不是可以去除掉anchor来进行检测呢?基于上述的思考,anchor-free也开始迎来了自己的发展。那么anchor-free与anchor-based的区别是什么?
anchor-free 与anchor-based的区别

anchor-based的方法是通过anchor和对应的编码信息来表示物体的,需要在图像的特征图中每个位置预先设置一定数量的anchor,然后对每个anchor进行分类和回归。
anchor-free的方法主要是通过多个关键点(角点)或者通过中心点与对应得边界信息来表示物体的,不需要预先设定anchor,直接对图像进行目标检测。
两者之间的区别在于是否使用anchor来生成候选框proposal,也可以说,两者之间的区别在于解空间的不同。
3.4.2 Anchor-free概述
实际上我们前面讲的YOLO算法anchor free中比较早期的模型,所以anchor free并不是一个比较新的概念。早期的anchor-free模型可以追溯到15年CVPR的DenseBox,算是Anchor Free的起源吧。但它比同期的Faster-RCNN系列和YOLO提前数月(YOLO是16年5月)。所以,anchor free的发展历史也可以说是相对久的。
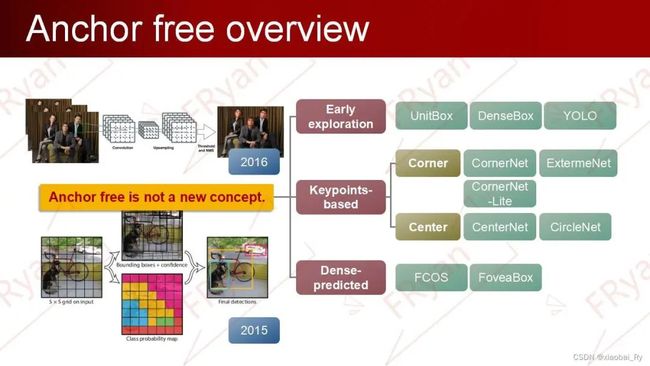
截止目前,anchor-free模型的发展主要可以分为早期探索、基于点和基于密集预测的。(这里只罗列出一部分比较有代表性的模型)

由于时间和内容的限制,这里我只介绍时间轴上的这些模型。其中,因为DenseBox对后期密集预测的anchor free模型有较大的影响,所以早期探索的模型只介绍DenseBox模型。
3.4.3 早期探索型
DenseBox
背景(人脸检测任务)在图像上进行卷积等同于使用滑窗分类,为何不能使用全卷积(FCN)对整个图像进行目标检测呢?如何将FCN应用到目标检测?
检测流程
首先经过图像金字塔生成多个尺度的图片。
图片经过FCN得到最终的输出featuremap。
将输出featuremap进行回归与分类,并用NMS后处理。

这里比较有意思的一点是DenseBox对ground truth的定义。它类似于语义分割的ground turth,如右上图,它并不采用全图进行训练,而是直接先crop出以人脸为中心并带有足够背景的patches,并resize到240*240。而且正负样本的定义也如上图所示,主要是将patch中心(0.8至1.25)区域的目标记为正样本,其他的标记为负样本。更多具体信息可以去看以下论文,这篇论文感觉还是有比较多的先进思想(与同时期文章相比)值得学习的,比如:
DenseBox使用全卷积网络,任务类似于语义分割,实现了端到端的训练与识别。其中,在R-CNN系列中,端到端的训练方式直至Faster R-CNN的提出才开始实现,而与语义分割的结合则是从Mask R-CNN才开始。
DenseBox利用了多尺度融合的特征。如上图,conv3_4、conv4_4,在网络中引入了上采样操作,将低层和高层的特征融合以得到更大尺度的feature map输出,而R-CNN系列直到FPN才开始使用,YOLO系列直至SSD才开始。
DenseBox使用了OHEM做负样本的难例挖掘。在DenseBox论文中,作者通过以下两种方法做了样本均衡Balance Sampling:(1)忽略正负样本过度区域,称为gray zone,是以正样本区域边缘的两个像素范围内的区间来定义的。(2)Hard Negative Mining,首先将负样本像素中的loss按loss大小排序,选取前面的1%为hard-negative,然后保证每张图片中正负样本的数量是1:1,负样本的50%来源于hard-negative,另外的50%从non-hard negative中随机选取。
利用了圆形描述,这在当时深度学习检测也算是早的。
采用了多任务学习的方法,如下图所示:

DenseBox中增加landmark定位分支(关键点检测分支),并基于此联合landmark热度图和人脸得分热度图(boudning box)构成了新的检测损失来进一步提升目标检测的精度。如上图所示,左图为新增加的landmark定位分支,与上面真实框(人脸中心区域)的定位分支相似。二者的区别在于:人脸区域检测分支的feature map是4通道(该点到四边的距离),landmark分支的gt feature map是N通道,N对应要输出的landmark点的数目,比如人脸是72个关键点,而车辆是作者自己标注的8个关键点。
DenseBox优点在FCN的基础上提出DenseBox直接检测目标,不依赖候选框。证明了单FCN(全卷积网络)可以实现检测遮挡和不同尺度的目标;在FCN结构中添加少量层引入landmark localization,将landmark heatmap和score map融合能够进一步提高检测性能。
DenseBox缺点使用embeddings进行角点匹配效果不好,导致某个物体左上角匹配到另一个物体右下角。
3.4.4 基于关键点系列(源于姿态估计)
CornerNet
CornerNet背景

对于姿态估计和分割的任务,它们的ground truth就是给点打标签。既然姿态估计是骨骼点代表物体,那目标检测的框实际上也可以用点来代替,比如左上角和右上角的点;既然姿态估计骨骼点也需要对同一物体,同一关节进行组合判断,那目标检测也可以通过角点之间的组合来判别是否为同一目标。受此启发,CornerNet摒弃了原本anchor-based的思想,采用keypoint-based的思路来进行检测。
CornerNet总体流程与架构

CornerNet采用Hourglass(沙漏网络)作为主干网络来提取特征,然后分成两个支路分别预测左上角和右下角坐标。每个支路文章称之为Prediction Module。在每个Prediction Module之前都会先过一个Corner Pooling(这也是CornerNet文章的一个亮点), 再分成三个子支路Heatmaps、Embeddings、Offsets。其中,heatmaps预测某位置是角点的概率、offsets预测实际角点相对于该位置的偏移、embeddings嵌入向量用来进行角点配对。首先,heatmaps是如何找到corner的?在CornerNet中,heatmaps主要通过扩大学习区域并进行corner pooling来确定哪些点是我们所要寻找的corner。

Reduce penalty:在训练时,如果我们只是单纯地将两个角点对应的像素标注为正样本,其余为负样本,那么在训练时负样本的点都将被舍弃掉,这个惩罚力度太大,不利于模型的训练。所以,作者希望通过以利用高斯分布来填充所扩大角点像素值的覆盖范围,以此获取更多的正样本,从而降低负样本对模型的惩罚力度。要知道,微小扰动所形成的bbox从直观感受并不会带来过多的干扰,更何况不同的人标注之间也存在这种现象。这样子做,可以使网络更加的鲁棒。
Corner pooling:以往的max pooling更多的是将物体的信息集中到物体的中心区域,但CornerNet期望的是物体的信息可以集中在角点,因此,作者就设计了Corner Pooling来融合某点在水平和垂直两个轴线方向上的信息。如上图,以左上角为例子的话,corner pooling是分别将目标点垂直轴线以下的位置提取最大值,然后对水平轴线以右的位置提取最大值,将两个最大值相加即为该点池化后的结果,实际应用时可以从右向左、从下向上进行更新计算,减小复杂度,提高计算效率。
其次,embeddings是如何匹配corner的? 在人体姿态估计中,相对应的角点也会互相匹配,因此,CornerNet也借鉴了这种思想,认为属于同一目标的corner embedding应该具有较高的相似度,而不同物体之间的corner embedding应该具有较远的距离。总而言之,就是寻找一个特征空间来区分不同object之间的corner。

最后,为什么需要offset? 模型设计存在下采样过程,这就不可避免的是一些点的坐标在下采样时会产生一些模糊/偏移。而且,这种模糊性的位置偏移误差会随着下采样层数的叠加而累计。那么在小目标的检测上,这种误差累计就会被放大,对于小目标来讲是不可接受的。所以需要引入offset偏移量来对位置的模糊偏移进行修正。
CornerNet评价

检测精度可以与anchor-based的方法相媲美。但物体的特征一般集中在物体内部,左上、右下两个点的特征并不明显,不容易确定位置。而且,如上图,同类别不同目标的角点容易被错误地匹配从而形成误检框。检测速度还有较大的优化空间。
CornerNet-Lite
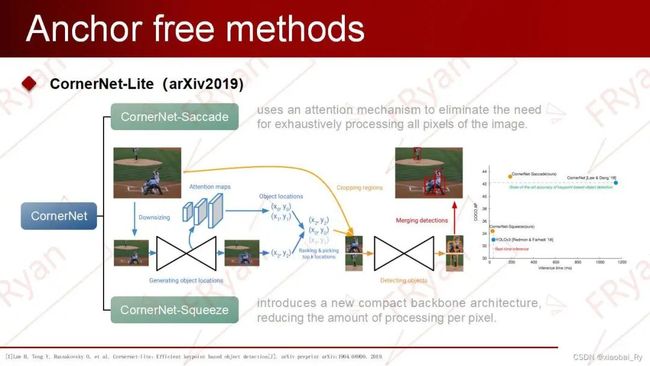
CornerNet-Lite是两个CornerNet变种的组合:
CornerNet-Saccade:通过添加注意机制分支,来关注有意义的像素点从而来减少模型所要处理的像素量,并将Cornernet单阶段检测器变为两阶段检测器实现了粗细的结合,从而提高检测精度。
CornerNet-Squeeze:引入一个新的、紧凑的基础网络架构,从而减少每个像素点的处理流程。
因此,CornerNet-Saccade可以看成是CornerNet引入two-stage的思想,来提高模型的精度,因而比较适合离线处理;而CornerNet-Squeeze可以看成是YOLOv3思想即one-stage模型优化思想的注入,用来提高模型的检测速度,因而CornerNet-Squeeze比较适合实时处理。总而言之,CornerNet-Lite结合了上述两个模型的改进达成了检测精度与效率提高的双赢。
ExtremeNet
ExtremeNet背景前面我们也说了,左上与右下角点的特征不足以代表目标物体的特征,而且大多的角点都不在目标物体上。因此,单纯地依赖角点进行目标检测,模型可能不能很好地理解目标物体的特征。

所以,ExtremeNet把左上与右下角点替换成目标的中心点以及其在四个正方向上的极值点(extreme points)来实现检测。ExtremeNet的极点在对象上,是视觉可分的,有一致的局部外观特征(如人的最上面的是头)。
ExtremeNet流程
首先,分别预测每个对象类别的4个heatmaps和center heatmaps,得到4个极值点和中心点predict_center。
其次,通过枚举所有可能极值点的组合(四个满足几何对齐的极值点为一个组合)来获得每个可能组合中的中心点extreme_center,然后通过计算extreme_center在predict_center heatmap中的响应来判断该组合中的四个极值点是否与predict_center为同一物体对象,即四个极值点组成的边界框的中心在预测的中心点热图上有较大的响应时才认为该生成的边界框有效。

如下图所示,ExtremeNet使用HourglassNet检测每个类的5个关键点,offset预测与类别无关,与极值点有关,中心点没有offset预测,所以网络的输出是5C个热图和8个偏移图。

与CornerNet的区别
CornerNet通过预测角点来检测目标的,而ExtremeNet通过预测极值点和中心点来检测目标的。其中,CornerNet中的角点通常位于目标外,ExtremeNet中的极值点位于目标上,其能够反映物体的表观特征。
CornerNet通过角点embedding之间的距离来判断是否为同一组关键点,是基于几何关系的分组匹配原则,而ExtremeNet通过暴力枚举极值点、经过中心点判断4个极值点是否为一组,是基于目标外观的分组匹配原则。
ExtremeNet评价
ExtremeNet的优点延续CornerNet的检测新思路,将角点检测改为极值点检测,更加稳定,在muti-scale的测试下效果好。
ExtremeNet的缺点:
对并行出现,互相遮挡的目标物体检测效果差;
从效果上看,并没有比CorNerNet有明显的提升;
检测速度慢,主干网络计算量太大。
CenterNet
背景与ExtremeNet类似,CenterNet也是基于中心点来实现目标的检测。CornerNet和ExtremeNet都需要对点进行配对分组,但这个过程会带来比较大的计算量。所以,CenterNet只考虑使用中心点来定义目标,并通过中心点直接回归预测目标的特性,比如宽高信息,类别,3维位置和朝向等。
与CornerNet/ExtrmeNet的对比

都采用相似的关键点检测思路,均使用heatmap思想和focal loss进行训练
都采用相似的offset分支来弥补下采样点的位置误差
CenterNet不需要对关键进行分组匹配操作
与acnhor-based的对比

CenterNet分配的锚点仅仅是放在位置上,没有尺寸框。而单阶段YOLOv3中每个cell的中心点包含anchor shape信息。
每个目标仅仅有一个正的锚点,因此CenterNet是nms-free的。而之前提到的许多anchor-based方法是需要产生大量的anchor来进行回归预测的。因此,它们通常都需要NMS算法来进行抑制。
以Faster RCNN为列的anchor based方法需通过overlap及阈值来定义正负样本,而CenterNet正负样本的定义仅依赖位置而不依赖overlap。因此,CenterNet也可以看成是iou-free.

CenterNet优点:
模型结构设计简单
对于其他视觉任务有较好的拓展性
去除NMS后处理利于加速模型预测
CenterNet缺点:
训练时间长
回归监督信息仅通过中心点位置产生,会发生中心点重合的冲突
CircleNet
背景
CircleNet是基于肾小球背景下提出来,而肾小球是细胞。通常这种细胞都比较偏向圆形。因此,使用基于圆形的定义比矩形的定义要好,也更加贴合细胞的形态,而且具有旋转不变性!

流程
通过特征提取网络提取图像的特征,而后分别采用三个输出模块进行预测:(1)heatmap,用来表示circle的中心点;(2)local offset,用来修正circle的中心点位置;(3)circle radius,用来表示circle的半径。

与CenterNet的相同点CenterNet和CircleNet中的冲突都是目标框的中心点重合。其中,CenterNet主要是基于COCO数据集实验的,而CircleNet是肾小球数据,这两个数据库目标重合的概率非常小。所以在训练时,中心点重合所导致的优化冲突微乎甚微。因此这两篇文章没有针对这个这个矛盾点进行改进。
3.4.4 基于密集型系列(源于语义分割)
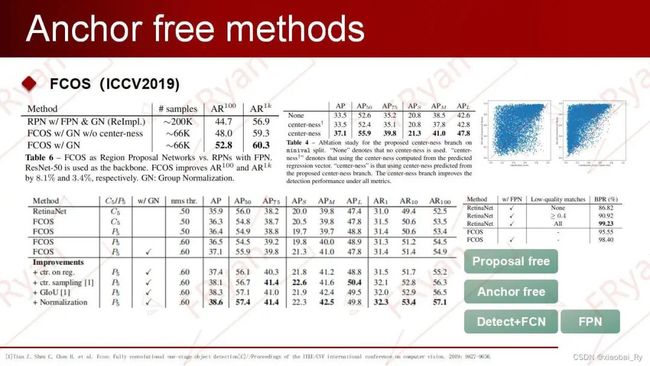
FCOS
FCOS背景与思路前面讲到的CornerNet、CenterNet等都是基于关键点来检测的,而接下来讲的FCOS则是基于分割的思想来进行检测的。而FCN算是语义分割的鼻祖算法,即通过一系列的卷积与反卷积实现了对像素级的分类。之前的目标检测受制于anchor的使用,所以就没有在FCN上进行进一步的探索。而基于关键点检测的anchor-free存在中心重叠检测的问题(CenterNet/CircleNet),因此,FCOS就使用FCN网络直接对图中的每一个像素点的位置到真实物体四边的距离进行一个回归。所以,FCOS与语义分割一样,处理对象都是像素点。从总体的思路来看,FCOS可以理解为是 DenseBox基于FCN的改进版。

不管是CenterNet的中心重叠问题,还是语义分割的问题,都存在一个像素点只有一个label的问题。但如左边这个图(人与羽毛球拍),如果时目标检测任务的话,那么人与球拍重叠区域的像素点应该同时具备两个label。所以,在目标检测中,如果发生物体区域重叠的现象,那么一个像素点就不仅只有一个类别label,可能是两个甚至更多个。而且FCOS主要是在行人检测,车辆检测的背景下提出来的。那么物体相互重叠/遮挡的问题就更加明显了(23.16%)。因此,FCOS在重叠部分的点是具有多个监督信息的。但模型训练时监督信息肯定只能有一个,因此FCOS通过引入特征金字塔FPN网络来缓解目标重叠问题,即通过不同尺度的特征图分支头来实现不同物体的检测。(这点更YOLOv3中引入多个分支不同分支采用不同的anchor的思想相类似)
==由于多尺度结构的存在,因而需要确定这个bbox分配给哪个层级来预测。== 传统的FPN做法是会根据这个box的面积进行分配,而FCOS会给每一个层级分配阈值范围,然后根据Box中点到四边的最大距离落在哪个层级的阈值范围内,那这个Box就分配给哪个层级来预测。
FCOS网络结构FCOS的网络架构如下图所示。其中C3, C4, C5表示骨干网络的特征图,P3到P7是用于最终预测的特征级别。这五层的特征图后分别会跟上一个head。每个head又包括了三个分支,分别用于分类(Focal loss)、中心点置信度(BCE loss)和回归的预测(GIOU loss)。因此,FCOS网络最后的输出层包含(4+C)个通道,分别对应预测C个类别得分及4维bbox参数(像素点到真实框四边的距离)。

在FCOS网络中,你会发现它增加了一个中心点置信度的预测,那么为什么要添加这个分支呢?FCOS内,我们会把目标框内所有的点定义为正样本。这样子,远离真实物体中心,靠近物体边缘的像素点回归所得到的四边距离效果不佳,质量较差。因此,需要通过引入center-ness分支,来抑制这些低质量的目标框。center-ness作用于网络中,和分类分支是并行的,是用来预测每个点的中心度。训练的时候,使用BCE loss,而测试的时候,会把中心度的得分和分类分支的得分做一个相乘,作为该点的最终得分。这样,真正远离中心点的点的置信度得分就会被削弱。因此,便可以结合NMS来将这些点加以过滤。
如下图所示,我们可以看到较大物体的AP显著提高,这就是由于较大物体的中心偏离比较严重。
FCOS的优点
1.将检测和FCN进行结合,思想新颖。
2.proposal free和anchor free,减少了超参的设计。
3.不使用trick,达到了单阶段检测的最佳性能。
4.模块化,对其他视觉任务具有较大的可扩展性。
FCOS的缺点中心点的定义模糊,依赖标注信息,box的预测分配不是很合理。
FoveaBox
FoveaBox概述作为与FCOS和FSAF同期的Anchor-free论文,FoveaBox在整体结构上也是基于DenseBox加FPN的策略,主要差别在于FoveaBox只使用目标中心区域进行预测且回归预测的是归一化后的偏移值,还有根据目标尺寸选择FPN的多层进行训练。FoveaBox正负样本定义在FoveaBox中,正样本区域(fovea)的选择并不是真实框所包围的全部像素,而是原区域的一个衰减区域(可以看作是目标的中心区域,缩放因子是人为设定的),这个与DenseBox的设置一样,这样设置的原因是为了防止语义区域的相互交叠!

FoveaBox预测选择同其他目标检测算法相同,由于目标尺寸的多样性,所以直接预测目标的边界是不稳定的。因此,FoveaBox同FCOS一样通过不同层级来预测不同的目标。不同的是,FoveaBox将目标尺寸归为多个区间,各层负责特定尺寸范围的预测。其中,用于控制特征金字塔每层回归尺寸范围的缩放因子也是人为设定的。FoveaBox坐标映射与DenseBox和UnitBox不同,FoveaBox并不是直接学习目标中心到四个边的距离,而是去学习一个预测坐标与真实坐标的映射关系。
FoveaBox网络架构

FoveaBox主干网络采用特征金字塔的形式,每层接一个预测Head,包含分类分支和回归分支。同时,FoveaBox提出了特征对齐的trick,主要是对预测Head进行改造。从实验结果上来看,特征的对齐对模型的精度也有一定的提升。
评价
目标区域是明确定义的
对任意形状的包围盒更加鲁棒(从左下图)
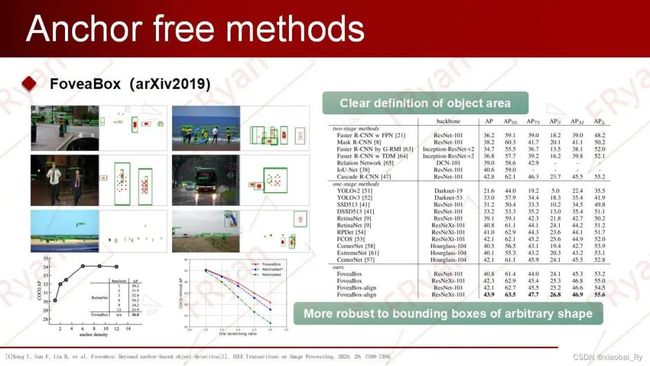
在 FoveaBox 中,每个预测位置都不与特定的achor相关联,允许任意的纵横比,而且它直接预测目标的 ground-truth ,能够更好地捕捉那些非常高或非常宽的对象.
FoveaBox整体设计思路为anchor-free,不需要人为的去定义anchor的参数,但仍然需要手工的去设置参数,比如每层的匹配的尺寸预测范围以及正样本区域fovea的缩放因子。
3.4.5 总结与思考
anchor free与anchor based的比较就好比one stage与two stage的比较,前者优势都在于检测速度,而后者的优势都在于检测精度。同比于one stage与two stage的发展趋势,anchor-free在精度层面也在不断的提升。而anchor free在精度上之所以能够媲美 anchor-based,最大的功劳应该归于FPN,其次归于Focal Loss。
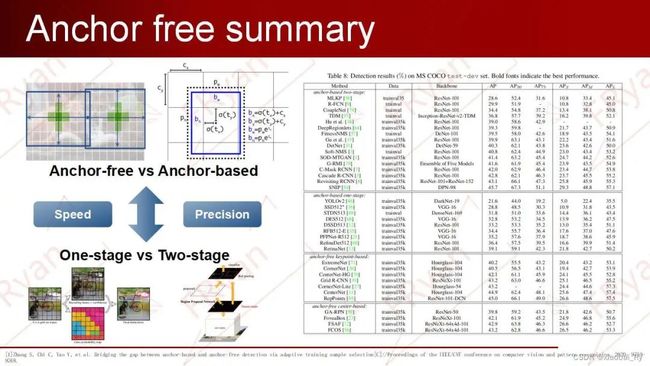
各种anchor-free方法的关键在于它们的ground truth是如何定义的。合适的ground truth更加贴合物体真实形态的分布,因此,从先验上来看,模型的检测精度也会对应的提高。走在前端(时间轴)的anchor-free方法灵感大多来源于人体姿态估计和语义分割的处理思想。由此对应地衍生出了我们前面所讲的Keypoint-based和Dense-predicted的anchor-free模型,这两种方法的本质将anchor转换成了point或者说是region来实现物体的检测。

Keypoints-based(CornerNet、CenterNet和ExtremeNet)的目标检测方法的异同点
相同点:
都采用Hourglass网络作为主干网络用于特征提取
都采用haetamaps(高斯模型)来泛化keypoint的区域
都采用Fcocal loss来平衡正负样本
都使用offset分支来修正下采样带来的坐标偏差
都使用L1 loss或者IOU loss来作为box的回归指标
不同点:
关键点的定义不同:CornerNet将bbox的两个角点作为关键点。ExtremeNet检测所有目标的四个极值点(最顶部、最左侧、最底部、最右侧)和一个中心点;均需经一关键点grouping阶段,降低算法速度。CenterNet仅提取目标中心点,无需对关键点进行grouping或后处理。
匹配分组的原则不同:CornerNet为embedding距离,ExtremNet为中心点heatmaps的响应,CenterNet无需匹配。==Dense-predicted(FSAF、FCOS和Foveabox)的目标检测方法的异同点==
相同点:
都采用FPN来进行多尺度目标检测。
都将分类和回归解耦成2个子网络来处理。
都采用Fcocal loss来平衡正负样本。
都是通过密集预测(像素级)进行分类和回归的
都使用L1 loss或者IOU loss来作为box的回归指标
不同点:
FSAF和FCOS的回归预测的是到4个边界的距离,而FoveaBox的回归预测的是一个坐标转换。
FSAF通过在线特征选择的方式,选择更加合适的特征来提升性能,FCOS通过center-ness分支剔除掉低质量bbox来提升性能,FoveaBox通过只预测目标中心区域来提升性能。
FoveaBox是直接选取分类score高于某阈值的像素点;FCOS除了预测分类score外还对centerness进行了预测,选取的是centerness较高的像素点;CenterNet则是把分类score的heatmap中的peak点。但在某像素点的分类score最高,未必代表该像素点就最适合去回归。
FoveaBox和FCOS都是预测中心点到box的四条边的距离,但前者采用了L1 loss,后者采用了unitbox的IoU loss。在具体计算的时候,都会除以感受野来排除尺寸的影响。

CornerNet、CenterNet等基于关键点的anchor-free模型通过高斯模型泛化关键点区域来定义正样本数据点(heatmap定义),减少模型负样本的惩罚力度;FCOS定义bbox内的像素点均为正样本,而FoveaBox通过衰减因子将bbox缩放,并将缩放后区域FoveaBox内的像素点定义为正样本。
3.5 Transformer-based的目标检测

3.5.1 引言
Transformer是近年来比较火的一个专题,最开始是应用在NLP领域。从研究的数据来看,近几年来在CV、语音视频、多模态等领域的研究发表非常地迅猛。其中,在CV领域上的Transformer一般统称为Vision Transformer, 简称Vit。

3.5.2 概述
同样的,Transformer在目标检测的研究也发表了很多paper. 左边是今年五月更新的一篇综述整理的有关Transformer的目标检测模型(中科院、东南大学等),右边是各模型在COCO数据集上的SOTA表。虽然这篇综述是在今年五月更新的(今年五月是第三版,第一版是在去年8月,如果没有记错的话),但它实际也没有把最新的一些相对比较火的模型涵盖进去(比如Swin Transformerv2, VitDet等)。

3.5.3 发展轴预览

3.5.4 CNN-backbone系列
3.5.4.1 DETR
与CNN-based的区别既然是讲Transformer在目标检测的模型,那必定要先介绍Transformer检测的开篇之作DETR。与前面的Anchor-based相比,虽然DETR是首个用Transformer来做目标检测的,但是它与前面提到的CNN-based的方法都是采用cnn作为主干网络用来提取图像特征,不同的是Anchor-based是对预定义的密集anchors进行分类和回归,可以看成是image-to-boxes,对于anchor-free就是image-to-points或者说是pixels-to-boxes/image-to-regions,而DETR是把目标检测任务看作一种图像到集合(image-to-set)的任务,其中set的作用跟anchor-based中的anchor作用相类似。这个集合实际上就是一个可学习的位置编码,也就是后面我们会讲到的解码器中输入的object queries。与先前密集的anchor设计相比,object queries是一种稀疏化的设计。
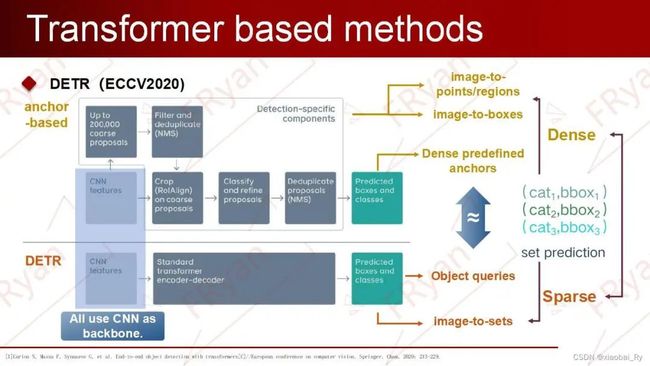
DETR的网络结构(1)DETR 首先使用CNN backbone来提取图像特征,并将其展平(flatten)后加入空间位置编码(spatial positional encoding)得到序列特征,作为Transformer encoder的输入。其中,原文利用ResNet提取特征图,但特征图转成特征序列后,图像就会失去了像素的2D空间分布信息,所以Transformer引入空间的位置编码。虽然如此,但DETR在消融实验也指出:即使不给encoder添加任何位置编码,最终的AP也不会下降很多。
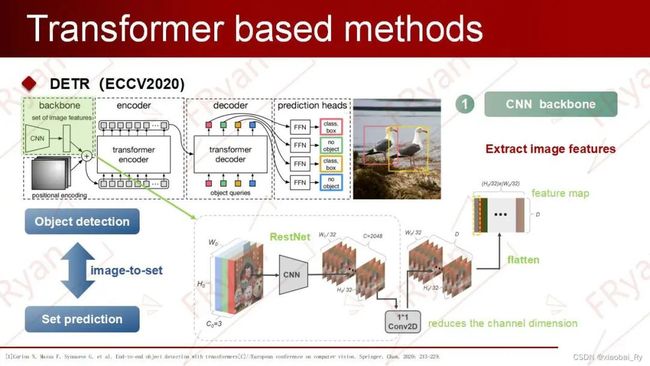
(2)其次,encoder接收序列特征并做self-attention机制的处理,得到特征图上每个instance的global attention,即编码后的特征图global features。由于Transformer 中的attention机制具有全局感受野,可以建立图像序列的上下文关系,所以DETR能进行特征图的全局分析,从全局上将检测出所有目标所构成的整体作为目标。

(3)然后,decoder部分则接收来自encoder的输出结果和一组可学习的object queries,最终输出所预测的BBox集合。
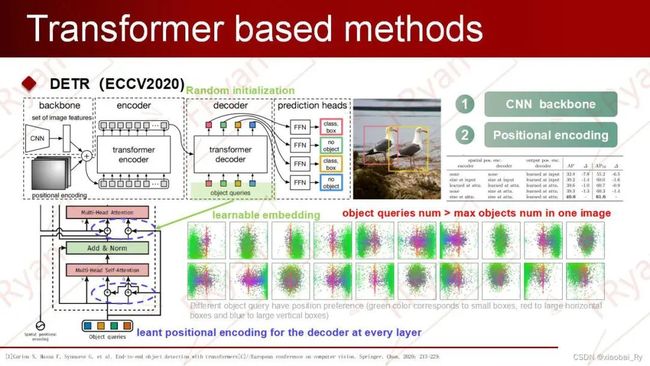
图说明:绿色表示小物体,红色表示水平的大物体,蓝色表示竖直的大物体。
有关object query的理解:
object queries是可学习的embedding,是随机初始化的,不由当前图像内容计算得到,并随着网络的训练而更新,使得object queries拟合物体分布,因此object queries隐式建模了整个训练集上的统计信息。- object query也可以看成是adaptive anchor,是对anchor的编码。每个query对应图像中的一个物体实例( 包含背景实例)。因此,object query的数量一般设置要远大于数据库中一张图像内包含的最多物体数。
object query通过cross-attention(decoder)从编码器输出的序列中对特定物体实例的特征做聚合,如右下图,即让该可学习object queries中的每个元素可以捕获原图像中不同位置与大小特征等的物体信息。又通过self-attention(encoder)建模该物体实例域其他物体实例之间的关系。
(4)最后,FFN基于特征聚合后的object queries预测边界框的标准化中心坐标,高度和宽度,而线性层使用softmax函数预测类别标签。由于object queries并不像anchors那样密集铺开的,所以DETR使用匈牙利算法(二分图匹配算法)对predictions和ground truth boxes进行最佳匹配,从而实现label assignment。
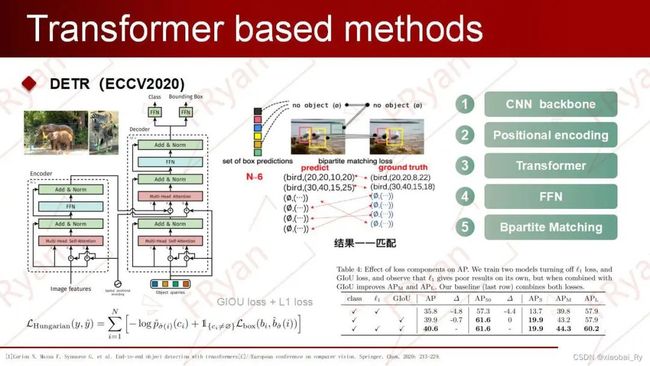
匈牙利算法的理解:如中间匹配的图,匈牙利算法就是一种用增广路径求二分图最大匹配的算法,核心是寻找增广路径。通俗易懂的讲就是两两分组,达到最佳效率的匹配。算法的时间复杂度为O(NM),其中N为二分图左边的顶点数,M为二分图中边的数目。

DETR优点:
端到端,简结的训练方式
无需任何后处理,实现简单
DETR缺点:
收敛速度慢,训练时间长。
小物体检测性能差。对于 DETR 来说,高分辨率的特征图将带来不可接受的计算复杂度和内存复杂度。
object query的设计不是很合理。
3.5.4.2 Deformable DETR
Deformable DETR对DETR的问题分析与改进思路
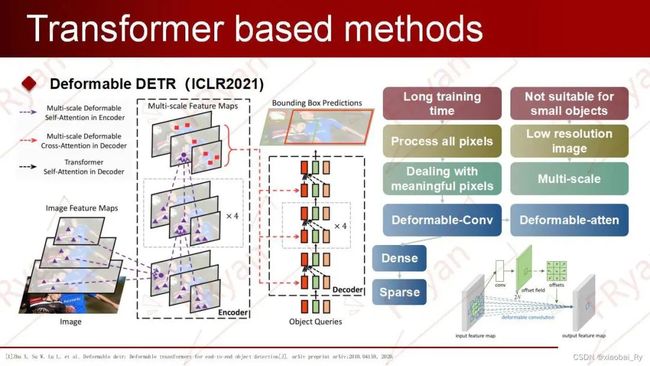
DETR注意力机制带来的局限性在DETR中,attention机制会关注到feature map中所有pixel位置,而且encoder输出的global features与decoder embeddings之间的相互作用是稠密的(DETR在decoder中的每一层都加了编码),这极大的增加了模型的复杂度及计算量。
问题分析1:收敛速度慢。在初始化时,transformer中每个query对所有的key给予几乎相同的权重,这使得网络需要经过长时间的训练从能将attention收敛到特定的区域,即有稀疏有意义的区域。
问题分析2:对小物体的检测性能不佳,由于transformer中attention机制随着图像中像素数目的增加呈平方增长,使用大的特征图输入encoder的代价极其高昂。因此,DETR只采用32倍下采样的特征图作为输入,导致其对小物体的检测性能不佳。
上面两个问题都来源于Transformer需要多的、冗余的像素进行处理。那既然是这样子的话,我们是否可以让Transformer在下采样的同时学习到更多更有效的区域呢?
Deformable DETR对DETR的改进思路基于上述思考,由于Deformable conv是处理稀疏位置的一种有效机制,所以Deformable DETR提出了一种可变性注意模块(deformable attention),使Transformer去关注有意义的区域。由于模型只需要关注稀疏的采样点,其收敛速度显著提升。同时,由于每个query只需要对稀疏的key做聚合,模型的运算量和显存消耗显著下降,这使得Deformable Attention能够在可控的计算消耗下利用图像的多尺度特征,也就同时解决了上述的两个问题。
Deformable DETR的注意力机制与DETR中的attention机制相比,公式上的区别在于图像特征是否有约束,也就,这里指每个 query 对应的一个二维 reference point(二维的索引),是相对于的位置偏移。更加详细地,DETR为每个query安排指定数量(远小于pixel数)的key,也就是说,deformable attention是在原有的attention机制中对于输入加入了可学习的扰动偏移项,使得该attention只需要关注feature maps中的部分关键内容。由此,encoder初始化的权重不再是统一分布,即对每一个query,原本的key是所有的位置而现在的key是参考点(reference point)邻域内的位置。因此,与DETR相比,Deformable DETR只将更有意义的、网络认为更包含局部信息的位置作为key(数量固定)。
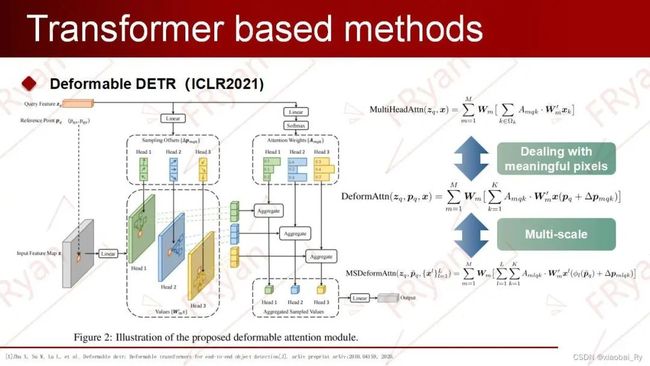
Deformable DETR中Transformer的结构将Transformer中encoder的attention module替换为multi-scale deformable attention module。其中,Encoder中的multi-scale feature maps来自于ResNet的C3到C5 stage,最后C5经过stride为2的3*3卷积得到C6。使用了multi-scale deformable attention module后就不需要FPN来融合不同尺度信息了。而在decoder中,只将cross-attention module替换为multi-scale deformable attention module,而self-attention module保持不变。
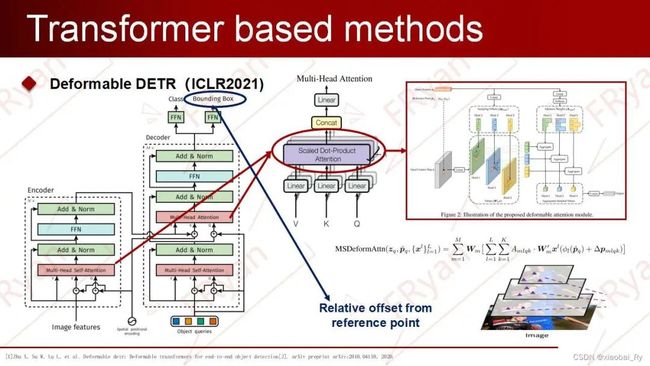
Deformable DETR评价
快速收敛性与计算内存高效性
检测精度提升
不需要FPN的复杂设计

“ DC5”表示消除ResNet的C5阶段的步幅,而改为增加2。“ DETR-DC5 +”表示对DETR-DC5进行了一些修改,包括使用Focal Loss进行边界框分类以及将目标查询数增加到300。
3.5.4.3 UP-DETR
背景DETR通常需要大量的训练时间,大规模的标注数据集。这一点其实和ViT很像,==但由于Transformer的全局注意力机制,所以原始的Transformer-based方法缺乏归纳偏置inductive biases==。这使得原始的Transformer-based方法需要依赖大规模数据集训练从能达到相对不错的效果。在DETR中,作为检测器的Transformer模块是没有经过预训练的,而在ViT中Transformer通常需要经过预训练。在一般情况下,预训练有利于模型更快的收敛,提高模型的学习能力。但在实际应用中,我们不一定拥有大规模的标注数据来进行训练及预训练,所以==我们能否利用无监督的预训练来提升DETR中Transformer的收敛速度呢==?要知道无监督预训练的关键在于代理任务pretext的设计。其中,pretext可以理解为是一种为达到特定训练任务而设计的间接任务。
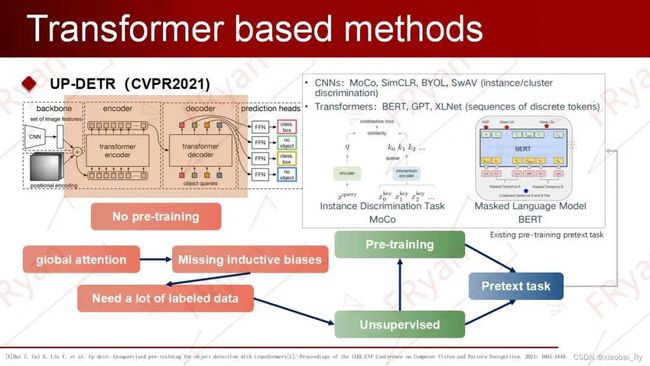
如上图的右子图可知,基于CNN的pretext主要偏向于视觉分类任务,也就是classification,而基于Transformer的方法更加偏向NLP的序列任务。但目标检测是CV任务,处理的对象(像素)是具有连续语义的;而NLP处理的一般是离散的字符。显然与先前像BETR这样的Transformer模型相比,基于CNN的pretext设计更加合适目标检测任务。然而,从下图右子图可以看出,偏向定位任务的模型主要关注空间定位学习,具有边缘/形状的归纳偏好,而偏向分类任务的模型主要关注的物体的内部特征,具有内部/纹理的归纳偏好。

因此,现有基于CNN与Transformer方法所提出的pretext并不适用于目标检测任务。
那么我们应该如何定义pretext?
pretext的定义为实现无监督预训练DETR,UP-DETR提出了一种random multi-query localization的pretext task来预训练DETR中的object query,以此来预训练Transformer的定位能力。具体而言,就是将添加位置编码后的图像特征输入到encoder,并从给定图像中随机crop patches,得到该补丁对应框的坐标,长宽,再将这个补丁作为query,进行一些简单的数据增强变换,输入到 DETR的decoder中。由此模型的目标变成了给定patch找他们在原图中的位置。通过这种方式构成一个无监督预训练的形式。最后,对于一个无监督预训练好的DETR,只需输入patch,便能实现无监督定位patch的功能,而且不需要额外的nms后处理。
multi-learning前面提到pretext任务主要是基于定位展开的,但目标检测任务是定义与分类的耦合。这两个任务有不同的归纳偏好,比如定位更关注于物体的边角轮廓,而分类可能更关注于纹理、材质等等。因此,pretext任务的设计缺少对分类判别性的考虑。为避免query patch检测的预训练破坏分类性能,UP-DETR将目标检测任务解耦从而进行多任务的学习,即冻结预训练的CNN backbone,并利用patch特征重构损失来保持Transformer的特征识别能力(保留上下文构建的特征语义性)。在实验中,我们发现,固定已经预训练好的CNN权重对于后面transformer的预训练和UP-DETR在下游目标检测中的表现有着至关重要的作用。同时,考虑到输出头通常是分类和定位两个分支,UP-DETR增加feature reconstruction分支,通过梯度回传来使经过CNN后得到的特征和经过transformer得到特征具有一致的判别性。但从消融实验来看,对于下游目标检测任务,feature reconstruction分支并没有带来额外的判别性信息,固定预训练的CNN权重才是涨点的关键。

在DETR的论文中,不同的object query关注不同的位置区域和框大小。因此,如何进行query patches 和object query之间的分配,以适应不同框的定位?
query patches 和object queryUP-DETR提出了一种multi-query location的方法,利用object query shuffle和attention mask方法来解决。其中, deocder使用attention mask来控制不同object query之间的交互,以此确保query patch的独立性;而object query shuffle则是用来确保embedding和query patch的随机性,以去除object query之间的显示分配,达到模拟真实数据场景的效果。
UP-DETR流程首先,利用冻结参数的CNN backbone提取视觉特征 。然后,将位置编码添加到特征映射中,并传递到DETR中的Transformer编码器。对于随机裁剪的查询patch,用具有全局平均池化(GAP)的CNN主干网络提取patch特征,然后将其与目标查询相加之后输入到Transformer的解码器中。在预训练过程中,解码器预测与查询patch的位置相对应的边界框。其中,CNN 参数在整个模型中是共享的,而Transformer是无监督预训练的。
UP-DETR评价
优点
首次将无监督方法用于DETR,有利于小数据发展DETR UP-DETR通过random query patch detection的预训练任务,将DETR中transformer模块进行无监督的预训练。
提供了更加合理的query设计思路
缺点
非端到端
小物体检测性能差,复杂度高 UP-DETR由于attention复杂度限制,只能做基于single-scale的特征图,没有办法直接拓展到multi-scale。这使得UP-DETR在大物体上非常的好,但在小物体上也还是存在瓶颈。
3.5.5 Transformer-backone系列
3.5.5.1 YOLOS
背景
第一点,以CNN作为backbone的transformer检测系列:在前面讲的DTER系列都使用随机初始化的Transformer对CNN特征进行编码和解码,这并未揭示预训练Transformer在目标检测中的可迁移性,比如transformer在ImageNet上与训练是否可以迁移到其他领域?
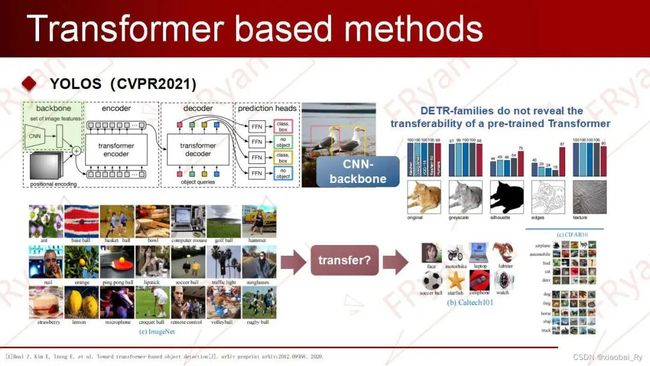
在20年的一篇CNN/transformer的对比论文中,发现:与CNN(CNN的归纳更加偏向纹理,虽然CNN也可以很好的归纳形状【The Origins and Prevalence of Texture Bias in Convolutional Neural Networks论文中,但是依赖于一些数据增强】)相比,MLP-Mixers和Vision Transformer更倾向于形状,而且许多Vision Transformer模型的表现类似于MLP-Mixers。

ViT可以将transformer直接作为backbone以纯序列到序列的角度来进行图像分类。要知道的是,ViT与CNN不同,它是对远程依赖关系和全局上下文信息进行建模,而不是对局部和区域级别的关系进行建模。此外,ViT缺乏像CNN那样的分层结构(multi-scale)来处理视觉实体规模的变化。==那么ViT能做目标检测backbone吗?==(==ViT能不能够将预训练好的通用视觉表征从图像级识别转移到复杂得多的2D目标检测任务中?==)
第二点,先前以ViT作为backbone的transformer检测系列:ViT-FRCNN是第一个使用预训练的ViT作为R-CNN目标检测器的主干。然而,这种设计无法摆脱对卷积神经网络(CNN)和强2D归纳偏差的依赖,因为ViT-FRCNN将ViT的输出序列重新解释为2D空间特征图,并依赖于区域池化操作(即RoIPool或RoIAlign)以及基于区域的CNN架构来解码ViT特征以实现目标级感知。
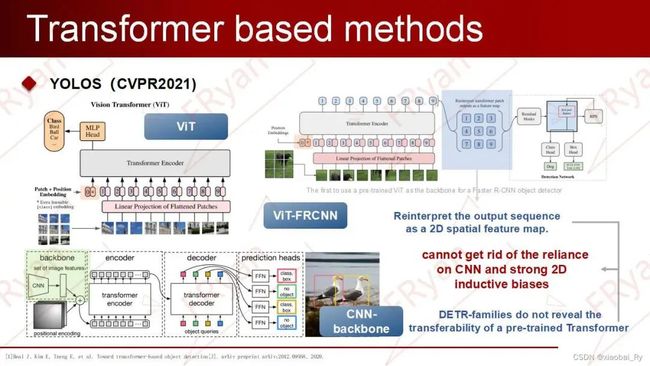
因此,Transformer能否以最少的2D空间结构从纯粹的序列到序列的角度进行2D目标识别?
YOLOS的架构(在VIT上的改进)YOLOS 结合了 DETR 的编码器-解码器颈部和 ViT 的仅编码器主干,来重新设计仅编码器的检测器。
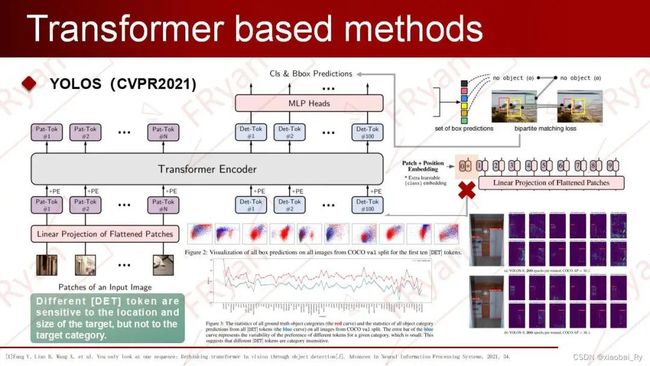
左上图说明:显示前十个[DET] token在COCO 验证集所有图像上的所有框预测。(蓝、绿、红分别代表小、中、大的目标)。
(1)YOLOS 删除了用于图像分类的 [CLS] 标记,并将一百个随机初始化的检测 [DET] 标记添加到用于对象检测的输入补丁嵌入序列中。(2)ViT 中使用的图像分类损失被替换为二分匹配损失,以执行类似于 DETR 的对象检测。这可以避免将ViT的输出序列重新解释为2D特征图,并防止在标签分配期间手动注入启发式和对象2D空间结构的先验知识。
所以,不同的[DET] token对目标位置和大小敏感,而对目标类别不敏感。即YOLOS在不知道确切的空间结构和几何形状的情况下执行任何维度的物体检测是可行的。
YOLOS的分析一些说明:不同模型的缩放策略:width scaling (w), uniform compound scaling (dwr) and fast scaling (dwr).

YOLOS的优点:
与CNN-backbone对比:在Tiny模型方面,YOLOS-Ti取得更佳的性能。
与DETR对比:(1)YOLOS探索了在ImageNet-1k数据集上预训练的标准ViT到COCO目标检测任务上的可迁移性。证明了预训练的仅编码器的ViT的可迁移性 。(2)DETR在图像特征和对象查询之间使用解码器-编码器注意(交叉注意),并在每个解码器层对辅助解码损失进行深度监督,而YOLOS始终只查看每个层的输入序列,在操作方面不区分patch token和[DET] token 。
YOLOS的缺点:
YOLOS需要用更长的序列来进行目标检测以及其他密集预测任务。
YOLOS的self-attention复杂度与序列长度成二次关系,不适用于更大的模型。
3.5.5.2 VitDet
背景前面讲的one-stage模型和anchor-free模型精度的替身都需要依赖多尺度的特征提取来提高检测的精度。所以FPN在检测任务中算是标配。FPN通过自上而下(top-down)和横向连接来将早期高分辨率的特征和后期更强的特征结合起来。

但如果主干网络不是分层网络,则所有的特征图将具有相同的分辨率,因而FPN就会失去它的作用。然而原始的ViT便不是分层网路,因此,ViT无法像CNN那样得到不同分辨率的特征图。所以,受CNN思想的启发,Swin Transformer和ViT Mask-RCNN等通过引入了分层的结构设计即逐级下采样来获取不同分辨率的特征图。虽然的确提高了ViT-backbone的目标检测算法的精度,但是FPN真的那么重要吗?是否能有其他的途径加以解决呢?可不可以消除对主干网络的分层约束,并使用普通主干网络进行目标检测呢?

思路与YOLOF相似,ViTDet论文抛弃常见FPN的设计,利用原始的ViT架构从单尺度特征图构建简单的特征金字塔,即直接利用ViT最后一层特征进行简单地上采用及下采样便可重建出一个简单的FPN,而没有必要像CNN那样从不同stage抽取特征。也不需要像标准的FPN那样做top-down,bottom-up的特征融合。真的就简单粗暴的把最后一层的特征图(因为它应该具有最强大的特征)通过一组卷积或反卷积来得到不同尺度的特征图,达到跟FPN一样的性能。具体来说,他们使用的是尺度为 1/16(stride = 16 )的默认 ViT 特征图。
YOLOF论文:FPN 模块的主要增益来自于其分治优化手段,而不是多尺度特征融合,FPN 模块中存在高分辨率特征融合过程,导致消耗内存比较多,训练和推理速度也比较慢,对部署不太优化,如果想在抛弃 FPN 模块的前提下精度不丢失,那么主要问题是提供分治优化替代手段,所以YOLOF中就借鉴ASPP,RFBNet的思想,引入空洞卷积,来协助进行多级特征的捕获代替设计了Dilated Encoder 串联多个不同空洞率的模块以覆盖不同大小物体,最后通过作者提出了新的均匀匹配策略,(核心思想就是不同大小物体都尽量有相同数目的正样本)Uniform Matching的作用完成了整体SiMo的结构设计,从实验结果来看Uniform Matching 作用非常大,进一步说明该模块其实发挥了 FPN 的分治作用。Dilated Encoder 配合 Uniform Matching 可以提供额外的变感受野功能,有助于多尺度物体预测,其实简单来说是通过系化对于FPN的研究,根据FPN的思想提出了Dilated Encoder和Uniform Matching,实际上不是舍弃了FPN,是传承了FPN。

在分层主干网络中,上采样通常用横向连接进行辅助,但ViT通过实验发现,在普通 ViT 主干网络中横向连接并不是必需的,简单的反卷积就足够了。研究者猜想这是因为 ViT 可以依赖位置嵌入来编码位置,并且高维 ViT patch 嵌入不一定会丢弃信息。分析由于ViT中的patch之间是没有重叠的(在每个patch,每个窗口内做attention无法得到全局的信息),所以需要通过一些手段让不同的patch之间进行信息交互。ViTDet并没有像Swin那样采用shift操作(跨层移动窗口),而是采用全局注意力( global propagation~=outer transformer)和卷积形式(window attention~=inner transformer )来做信息交互。(outer transformer和inner transformer是transformer in transformer论文),实际上就是四个block在做完window atteion(每个block又会分成cell)之后再在最后一个阶段进行一个global propagation,这样简单的交互就可以把全局信息和局部信息的纳入学习之中,并且大量的减少了模型训练所需的内存和计算量。
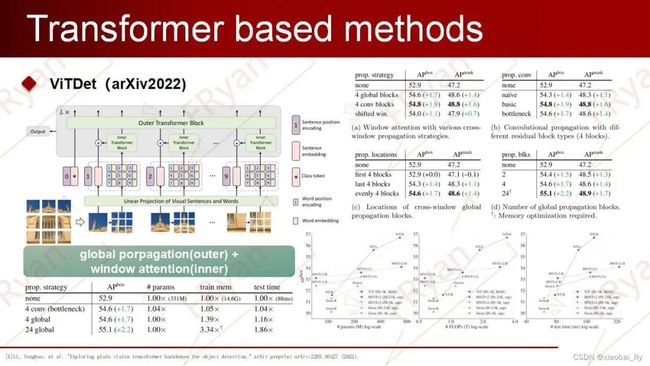
具体操作:在ViTDet中使用了极少数(默认为 4 个)可跨窗口的块。研究者将预训练的主干网络平均分成 4 个块的子集(例如对于 24 块的 ViT-L,每个子集中包含 6 个),并在每个子集的最后一个块中应用传播策略。
3.6 总结与思考
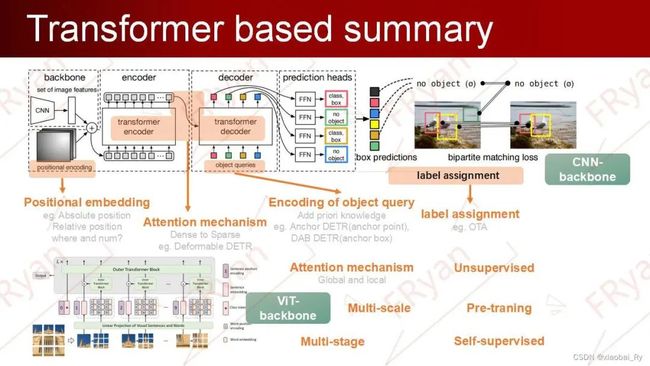
目前基于Transformer的目标检测算法主要以DETR和ViT等系列为主展开,其中以DETR扩展的Transformer检测模型主要是在object query(加入先验知识)、attention机制(稀疏化,关注有意义的区域)及==label assignment==(OTA等)机制,以及特征匹配与分配机制等的改进与扩展。
DETR系列
Object query的思考==对于object query,怎么样编码更精确及合适数量的query才能使更快速的get 到想要的feature?==
object query的数量?越少的query会导致各个query的搜索范围变大,并且难以检测同一位置的多个目标;过多的query又会导致难以抑制多个query收敛到同一物体的情况。
object query的编码?方法:加入先验知识,无监督训练策略... 例子:Anchor DETR直接将anchor point的位置编码为object query,DAB DETR将anchor box(包括位置长宽4个维度)编码为object query。
object query与image feature的对齐?由于object query和image feature间(位置上的和语义上的)不对齐,导致Transformer decoder中的Cross-attention layer难以精确地匹配到待检测物体所对应的特征区域,object query也因此采集到了很多除目标物体以外的无关特征,最终导致DETR收敛缓慢。所以,需要通过不同的方法限制了object query的采样区域,使得网络能够更快的地聚焦于物体区域,从而加速了训练。
Positional embedding的思考由于需要精准定位物体,DETR必须能够很好地编码特征的绝对/相对位置关系。因此,目前也有许多研究是从Positional embedding展开的。比如有添加相对位置编码的embedding,主要是从NLP衍生到2D图像。
ViT系列
而将Transformer作为backbone的目标检测方法很容易被引入到其他如R-CNN等模型中去完成更多密集型的预测任务。在Trannsformer-backbone中更多考虑的是attention机制及multi-scale,multi-stage的设计。如多层级的PVT可以从高到低处理不同分辨率下的图像特征,而如SWIN-Transformer通过滑窗的attention机制可以在避免计算量平方型增长的情况下同样实现短程和长程依赖关系的描述。其中,基于ViT的Transformer模型更多的需要预训练。
P4:总结与思考

4.1 总结

从前面对目标检测算法的回顾来看,我们可以看出目标检测算法实际上从繁到简(如anchor,nms,iou等是一个有设置到adaptive再到free的一个过程,又如multi-stage到one-stage),从粗到细(如iou和nms考虑更多的细节,比如密集程度,更多的定位信息)而发展的。
从部件和训练技巧上来看
模型在候选区域的选择由anchor-based到anchor-free,实现了由bounding box学习到bounding box调整,再到把bbox转化为基于point/pixel的学习。
模型在后处理的方式由传统nms发展到nms-free的时代。
评价标准的iou也是在一步一步的涵盖更多有关两框之间的相对位置的学习,从一个数据计算过的过程转化网络自适应学习的过程,再到现在iou-free的时代。
从训练阶段来看
模型由最初传统的复杂流程到以为r-cnn为首的two-stage时代再到one-stage时代,是一个从简的过程,由非端到端再到端到端实现了模型的自主学习,模型速度由慢到快的进化。
从模型与特征来看
模型的发展可以概括为传统算法到cnn-based再到transformer-based,特征也是由原来的设计到抽象再到有关注的特征上。
4.2 思考
虽然目标检测算法现在发展已经相对比较成熟,但是没有最好只有更好(哈哈).
对于CV任务,虽然CNN还是比较重要有效的,但是transformer-based的方法现在非常的火,也是一个比较好发paper的方向。
有关transformer在医学图像的可能性?
由于我自己之前毕设是做医学图像检测的,而且上一组同学也讲了一些transformer在医学图像上分割的方法,那么transformer在医学图像这种小数据集上有没有一些好的发展挖掘?前面同学都讲到transformer很依赖预训练,尤其是ViT这种改进的检测模型(这点我自己在跑实验的时候也有发现涨点很高,收敛也会大大加快),而且ImgaeNet预训练的模型也可以对医学图像的预训练有所提升。(虽然我自己也感觉两者之间的分布差异是比较大的)。
在上上周,同学也提到了cross-attention这个机制,目前这个研究方向的确也挺火的,但corss-attention应该怎么加,怎么设计,怎么更有效?是否更加合适小数据集?(前面看的论文对corss-attention也有一定相关的讨论),这里因为有关这方面看的论文还不是那么多,所以就先不发表观点了吧。但基于cross-attention的改进也可以考虑一下。
前段时间,一些基于小数据处理的transformer,尤其是ViT的研究也开始处于一个比较火的状态。而前面我们讲到了以ViT作为backbone的预训练模型它是很容易迁移到其他基本的模型上去的。那前面这些基于small dataset的ViT方法也可以进行一定的魔改并加以应用到我们自己的模型上。通过阅读可以发现基本上基于small dataset的ViT方法大多是通过自监督、多示例的训练方式来使ViT适应与小数据集。所以,个人人为transformer在医学图像上还是由比较多的发展可能性!感兴趣的同学可以看看上面的文章,这里我就不再一一展开介绍了。
4.3 作业
下面是本次专题汇报的class project

欢迎大家一起交流与讨论。

END
欢迎加入「目标检测」交流群备注:OD
