【Ensemble Learning】第 4 章:混合组合
在前面的章节中,我们讨论了如何混合训练数据,以及如何混合机器学习模型来创建更强大的模型——利用集成学习的力量。
让我们继续这个学习过程。在本章中,我们介绍并解释了两种强大的集成学习技术,它们利用机器学习模型的混合组合来构建更强大的模型。我们一次处理一个不同的组合。
以下是本章的目标。
介绍和解释boosting
检查如何使用 scikit-learn 实现提升
介绍和解释堆叠
检查如何使用 scikit-learn 实现提升
看看其他混合组合的例子
Boosting
让我们通过学习过程的类比来开始讨论提升。假设你希望一个班级的学生在所有科目上都表现出色,但有些学生在单元测试中表现不佳。我们可以识别这些学生,并更加强调他们得分较低的科目,以便他们与其他学生相提并论。为了提供更多的重点,我们通过增加课程和分配额外的时间来解决学生的薄弱环节来调整学习过程。这可确保学生在所有科目中的整体表现更好。
让我们对机器学习进行同样的类比。我们从一组学习者开始。每个 ML 学习器都接受训练对象的特定子集的训练。如果模型学习者的表现较差,我们可以更加重视该特定学习者。这被称为提升 。
首先,让我们讨论一种最简单但最重要的增强技术,AdaBoost。
AdaBoost
为了更好地理解AdaBoost,请查看图4-1。最初使用模型分类器训练数据。红框内的数据子集为误分类数据;而绿色框代表正确分类的数据。
为了提高模型的性能,我们不是对分类器模型中的所有数据赋予相同的权重,而是增加错误分类数据的权重并再次运行训练。由于我们增加了错误分类的数据点/观察的权重,在下一次迭代中,它们具有更高的正确分类概率,因为模型将更加重视这些数据点。我们重复这个过程直到n次迭代,当我们达到我们想要的模型性能时。这些弱分类学习器的组合使用投票(见图4-2)来获得最终模型。请注意,这通常优于非常复杂的技术。
总之,为了提高效率,我们可以更新错误分类的观察值的权重。略微增加错误分类的观察值的权重有助于提高下一次迭代中正确分类的观察值的数量。通过重复这些迭代,我们可以从一个非常弱的分类器中得到一个高质量的分类器。即使我们使用性能较弱的机器学习模型,我们也可以提高输出结果。
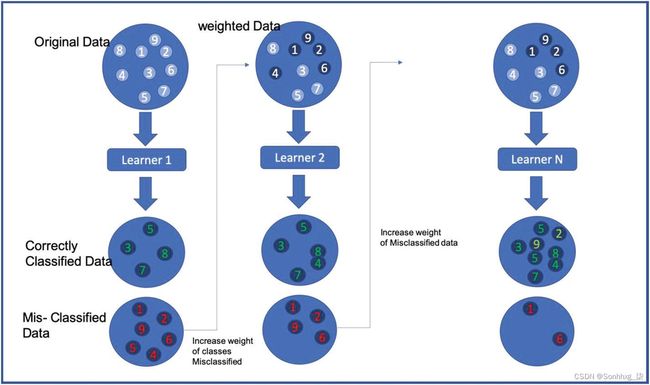
图 4-1 AdaBoost提升
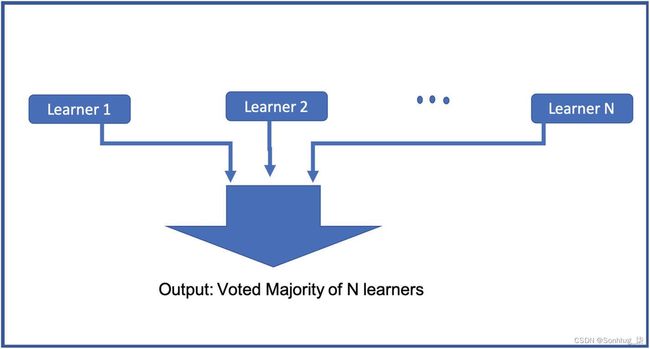
图 4-2 AdaBoost boosting中 n 个学习者的投票
清单4-1显示了如何将 AdaBoost 与 scikit-learn 库一起使用。
默认情况下,scikit-learn 使用基本学习器作为最大深度 = 1的决策树分类器。为了制作 AdaBoost分类器,我们传递了一个附加参数 n_estimators(在此示例中,n_estimators = 100)。AdaBoost 在基础学习器的每个额外提升权重副本上运行,直到存在完美的数据拟合或达到 n_estimators 限制。最多,它将创建 100 个我们的基本决策树学习器副本,每个副本都有提升的权重。
您可以在https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html阅读更多关于 scikit-learn 中 AdaBoost 分类器的不同参数的信息。
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
X, y = load_iris(return_X_y=True)
clf = AdaBoostClassifier(n_estimators=100)
scores = cross_val_score(clf, X, y, cv=5)
print(scores.mean())
# Output: 0.9466...清单 4-1 AdaBoost 使用scikit-learn
梯度提升
梯度提升类似于一般的提升方法。您需要迭代地增加或提升弱学习器。与 AdaBoost 不同,在 AdaBoost 中,您在增加分类不当的观察值的权重后添加一个新学习器,而在梯度提升中,您可以根据先前预测器产生的残差训练一个新模型。如果这没有意义,请不要担心。让我们看一个例子。
首先,尝试理解残差 的概念。图4-3是一个示例数据集。X0 到 X3 是特征/变量,Y 是基本事实或目标值。

图 4-3 残留误差
现在让我们假设在这个数据集上有一个训练有素的简单决策,深度很低(弱学习者)。训练完成后,我们的决策树上的预测/推断列在 Pred 列中。
每个观察的每个输出与机器学习模型的预测输出之间的差异称为残差 。在图4-3中,Error 列表示残差字段。
在基于梯度的增强方法中,您学习了一个新的分类器;您不是将特征 X0 到 X3,而是将先前分类器的残差作为训练新模型的新目标 (YNew)。
让我们总结一下到目前为止讨论的所有步骤。
1.在训练集上使用决策树回归器。
2.对第一个的残差使用第二个决策树回归器。
3.在第二个的残差上使用第三个决策树回归器。
您现在拥有一个包含三棵树的集成,您可以通过对所有树的预测求和来对新实例进行预测。
该算法的输出如图4-4所示。

图 4-4 残留误差(续)
清单4-2是在scikit-learn 库中使用梯度提升的示例代码。默认情况下,scikit-learn 使用基本学习器作为最大深度 = 1 的决策树分类器。
您可以在https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html阅读有关scikit-learn 中梯度提升分类器参数的更多信息。
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
X, y = make_hastie_10_2(random_state=0)
clf = GradientBoostingClassifier(
n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0
).fit(X, y)
scores = cross_val_score(clf, X, y, cv=5)
print(scores.mean())
# Output: 0.9225清单 4-2 使用scikit-learn 进行梯度提升
XGBoost
XGBoost 是一种最先进的算法和软件系统,专门研究残差梯度提升技术。它通过添加以下参数改进了香草梯度提升技术(我们不会详细介绍)。
它动态确定用作弱学习器的决策树的深度,并为深度较高的预防树添加惩罚参数。这可以防止过度拟合并提高性能。
它使用树上叶节点的比例收缩。
它使用牛顿树提升来优化树结构的学习。
它添加了随机化参数以实现最佳学习。
清单4-3是将 XGBoost 与 scikit-learn 和 XGBoost 库结合使用的示例代码。
XGBoost 库的文档位于https://xgboost.readthedocs.io/en/latest/。
XGBoost 的官方 GitHub 页面位于https://github.com/dmlc/xgboost/。您可以在其中找到分类和回归问题中的各种代码示例。
提示
要在 Anaconda Python 3.7 版中轻松安装 XGBoost 库,请使用以下命令:conda install -c conda-forge xgboost
import xgboost as xgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
# 读入数据
iris = load_breast_cancer()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将 DMatrix 用于 xgbosot
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 设置 xgboost 参数
param = {
'max_depth': 5, # 每棵树的最大深度
'eta': 0.3, # 每次迭代的训练步骤
'silent': 1, # 日志记录模式 - 安静
'objective': 'multi:softprob', # 多类训练的错误评估
'num_class': 3} # 该数据集中存在的类数
num_round = 200 # 训练迭代次数
bst = xgb.train(param, dtrain, num_round)
# 做出预测
preds = bst.predict(dtest)
preds_rounded = np.argmax(preds, axis=1)
print(accuracy_score(y_test, preds_rounded))
# Output: 0.9649122807017544清单 4-3 使用 scikit-learn 和 XGBoost 库的乳腺癌数据集 XGBoost 示例
Stacking
堆叠是一种与混合组合略有不同的方式。
在这种集成技术中,我们首先一起训练多个模型(基础学习 器)以获得预测。在堆叠中,各个预测的结果随后被视为下一个训练数据,并以称为元学习 器的另一层的形式添加(见图4-5)。
您可以将此技术视为将一层机器学习学习器堆叠在另一个机器学习学习器之上。
想象一下,您正在参加电视游戏节目,必须回答一个历史问题。您向您的两个朋友寻求帮助;一个是历史专业,另一个是计算机科学专业。你更相信谁能给出正确答案?您的知识使您能够更加信任您的历史朋友的回答(或者从技术上讲,为潜在的学习者之一提供更高的价值)。
堆叠基于相同的想法:我们不是使用简单的函数 (例如硬投票)来聚合集成中所有学习者的预测,而是训练一个模型来执行这种聚合。让我们看一个例子来更好地理解这一点。
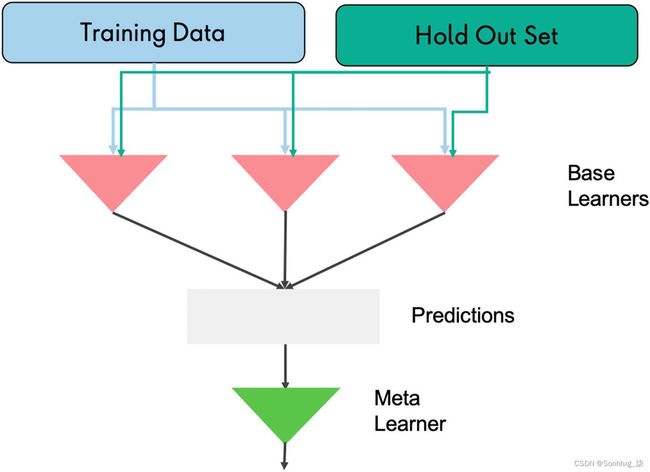
图 4-5 Stacking
清单4-4是在 scikit-learn 库中使用堆叠的示例代码。此外,如果您想将堆栈应用于任何回归问题,您可以借助清单4-5,我们在其中使用 scikit 学习库来处理回归问题。
您可以从https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.StackingClassifier.html的参考页面阅读更多关于scikit-learn中堆叠分类器的不同参数的信息。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import StackingClassifier
X, y = load_iris(return_X_y=True)
estimators = [
("rf", RandomForestClassifier(n_estimators=10, random_state=42)),
("svr", make_pipeline(StandardScaler(), LinearSVC(random_state=42))),
]
clf = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
clf.fit(X_train, y_train).score(X_test, y_test)
# Output: 0.9…清单 4-4 使用 scikit-learn 的堆叠分类器
from sklearn.datasets import load_diabetes
from sklearn.linear_model import RidgeCV
from sklearn.svm import LinearSVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import StackingRegressor
X, y = load_diabetes(return_X_y=True)
estimators = [("lr", RidgeCV()), ("svr", LinearSVR(random_state=42))]
reg = StackingRegressor(
estimators=estimators,
final_estimator=RandomForestRegressor(n_estimators=10, random_state=42),
)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
reg.fit(X_train, y_train).score(X_test, y_test)
# Output: 0.3...清单 4-5 用 scikit-learn 进行堆叠回归
概括
让我们快速回顾一下本章所涵盖的内容。
结合合奏
重要的组合技巧:boosting 和 stacking
各种提升技术,包括 AdaBoost、梯度提升和 XGBoost
Stacking 将一组集成学习器添加到其他学习器之上,形成元学习器
使用 scikit-learn 中的代码示例堆叠分类和回归问题