爬取图片简易爬虫
爬虫是一种解放个人劳动的高效方法,本文将为大家教授最简单的图片爬虫教程。由于我几乎都是自学的,所以名词可能不太专业,望见谅。
此篇文章我找了一个爬取图片的例子,如这位漂亮小姐姐

那么,方法如下
先上函数
def get(url):
header = {
'Referer': 'https://www.meitu131.com/',
'sec-ch-ua': '"Google Chrome";v="89", "Chromium";v="89", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (XHTML, like Gecko) '
'Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68 '
}
response = requests.get(url=url, headers=header)
response.encoding='utf-8'
return response对于几乎所有的爬虫来说,我们都需要这样一个get函数,这个函数可以将自己的电脑与网站之间建立通道,这个函数需要requests模块。
Python的爬虫分为get请求,清洗html文件,然后下载三个步骤,接下来是最重要的清洗步骤,在这个步骤,诸位可以写函数,也可以不写,意义不大,毕竟此时并没有使用多线程。
我们观察网页url,是https://www.meitu131.net/meinv/5535/index.html,此时我们点击第二页会发现它的url变成了https://www.meitu131.net/meinv/5535/index_2.html,此时我们应该将index后的数字换回1,以此来测试index_1到底存在与否,但此时很明显不存在。
好了,前期的准备都完成了,我们此时来进行最重要的一步,清洗数据,这个时候我建议使用xpath来进行(我个人觉得这是最简单的方法)。
用鼠标右键对准图片点击,找到检查元素,然后点击,我们会看到这样一个界面
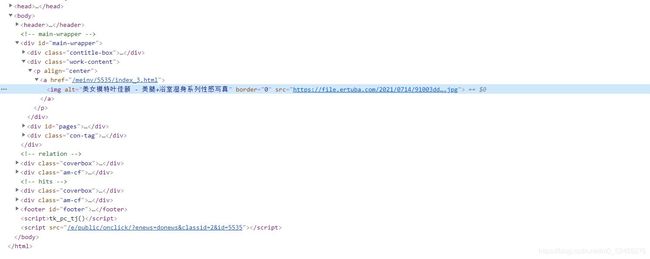
通过缩进,我们可以看到,我们想要的图片链接在src中,src在img标签,以此类推,我们找到一个div这个div有一个class属性是work-content,然后我们就可以写xpath了。
xpath以//开头,然后用/分级,用@来获取属性,由此我们得到了xpath——//div[@class="work-content"]/p/a/img/@src
def main():
a_url='https://www.meitu131.net/meinv/5535/index.html'
start = get(a_url).text
tree=etree.HTML(start)
page_max=tree.xpath('//div[@id="pages"]/a[1]/text()')
file = tree.xpath('//div[@id="main-wrapper"]/div/h1/text()')
filename_dir = file[0].split(']')[-1].split('V')[0]
page_max=int(page_max[-1].split('/')[-1])
for x in range(1, page_max + 1):
if not os.path.exists('小姐姐'):
os.mkdir('小姐姐')
else:
pass
try:
if x == 1:
url = a_url
else:
url = a_url.split('.html')[0] + '_' + str(x) + '.html'
a = get(url)
tree_a = etree.HTML(a.text)
odiv_a = tree_a.xpath('//div[@class="work-content"]/p/a/img/@src')
filename_img = odiv_a[-1].split('/')[-1]
try:
with open('小姐姐/'+ filename_img, 'wb') as f:
f.write(get(odiv_a[0]).content)
except Exception as e:
print('保存失败\n', e)
else:
print("保存成功\n")
except Exception as e:
print(e)xpath在代码中的书写过程是固定的,os.mkdir是用来创建文件夹的方式,在我们将url全部清洗出来之后,重新用get函数对图片进行请求,然后用with open写入到文件夹中去,try等语句是防止出错导致程序崩溃的,可要可不要。
最后,我们将main()函数执行就可以下载到pl小姐姐的照片了。
if __name__=="__main__":
main()第一次写博客,如果有什么问题或其他的,望原谅,本博客只教授爬虫的通用方法,图片等来自网络资源,如有侵权,请联系本人删除。