每日学术速递1.29
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
更多Ai资讯:

Subjects: cs.CV
1. Compact Transformer Tracker with Correlative Masked Modeling

标题:带有相关掩码建模的紧凑型变压器跟踪器
作者: Zikai Song, Run Luo, Junqing Yu, Yi-Ping Phoebe Chen, Wei Yang
文章链接:https://arxiv.org/abs/2301.10938v1
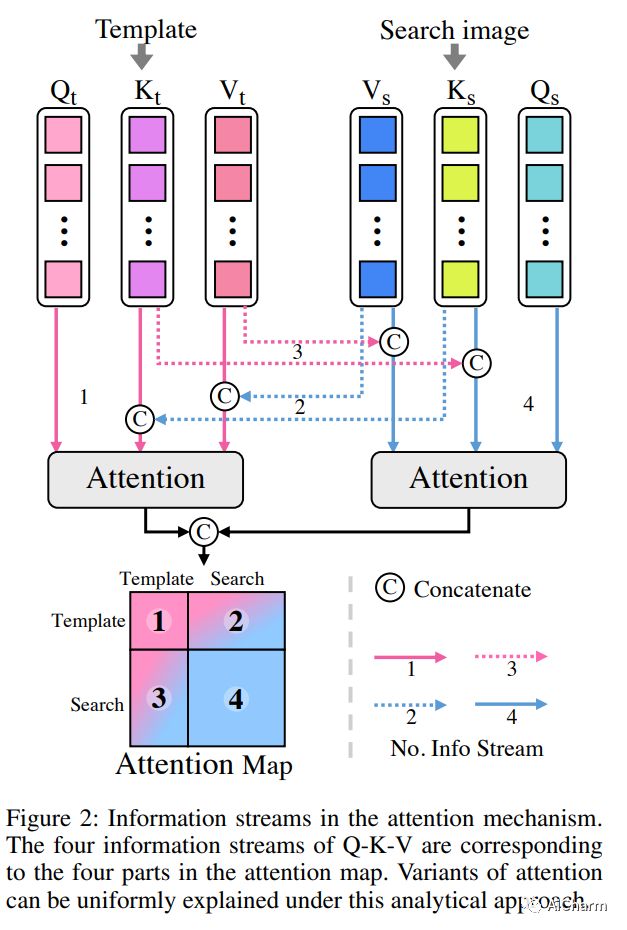
摘要:
变换器框架在视觉物体追踪中表现出了卓越的性能,因为它在模板和搜索图像的信息聚合方面具有众所周知的注意力机制。最近的进展主要集中在探索注意力机制的变种,以实现更好的信息聚合。我们发现这些方案等同于甚至只是基本的自我注意机制的一个子集。在本文中,我们证明了虚无缥缈的自我注意结构对于信息聚合来说是足够的,而结构调整是不必要的。关键不在于注意力结构,而在于如何提取用于跟踪的鉴别性特征,加强目标和搜索图像之间的交流。基于这一发现,我们采用基本的视觉变换器(ViT)架构作为我们的主要跟踪器,并将模板和搜索图像串联起来进行特征嵌入。为了引导编码器捕获不变的特征进行跟踪,我们附加了一个轻量级的相关掩码解码器,它从相应的掩码标记中重建原始模板和搜索图像。相关遮蔽解码器作为紧凑型变换跟踪器的插件,在推理中被跳过。我们的紧凑型跟踪器使用最简单的结构,只包括一个ViT主干和一个盒式头,并能以40 fps的速度运行。大量的实验表明,所提出的紧凑型变换跟踪器优于现有的方法,包括先进的注意力变体,并证明了自我注意力在跟踪任务中的充分性。我们的方法在五个具有挑战性的数据集上取得了最先进的性能,以及VOT2020、UAV123、LaSOT、TrackingNet和GOT-10k等基准。
我们的项目可在https://github.com/HUSTDML/CTTrack。
Transformer framework has been showing superior performances in visual object tracking for its great strength in information aggregation across the template and search image with the well-known attention mechanism. Most recent advances focus on exploring attention mechanism variants for better information aggregation. We find these schemes are equivalent to or even just a subset of the basic self-attention mechanism. In this paper, we prove that the vanilla self-attention structure is sufficient for information aggregation, and structural adaption is unnecessary. The key is not the attention structure, but how to extract the discriminative feature for tracking and enhance the communication between the target and search image. Based on this finding, we adopt the basic vision transformer (ViT) architecture as our main tracker and concatenate the template and search image for feature embedding. To guide the encoder to capture the invariant feature for tracking, we attach a lightweight correlative masked decoder which reconstructs the original template and search image from the corresponding masked tokens. The correlative masked decoder serves as a plugin for the compact transform tracker and is skipped in inference. Our compact tracker uses the most simple structure which only consists of a ViT backbone and a box head, and can run at 40 fps. Extensive experiments show the proposed compact transform tracker outperforms existing approaches, including advanced attention variants, and demonstrates the sufficiency of self-attention in tracking tasks. Our method achieves state-of-the-art performance on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks. Our project is available at https://github.com/HUSTDML/CTTrack.
2.Enhancing Medical Image Segmentation with TransCeption: A Multi-Scale Feature Fusion Approach

标题:用TransCeption加强医学图像分割。一种多尺度特征融合方法
作者: Reza Azad, Yiwei Jia, Ehsan Khodapanah Aghdam, Julien Cohen-Adad, Dorit Merhof
文章链接:https://arxiv.org/abs/2301.10877v1
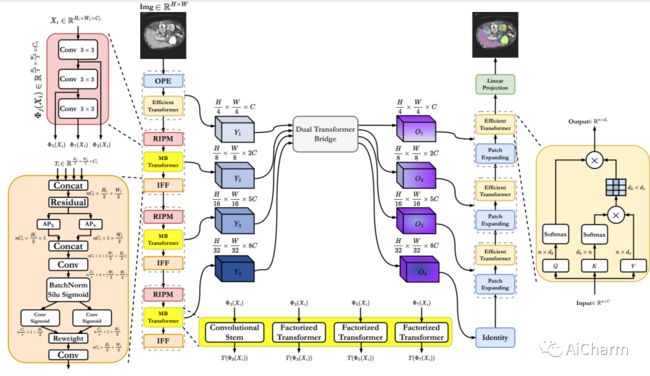
摘要:
虽然基于CNN的方法由于其良好的性能和稳健性而成为医学图像分割的基石,但它们在捕捉长距离的依赖性方面受到限制。基于变换器的方法目前很流行,因为它们扩大了接收领域,以模拟全局性的关联。为了进一步提取丰富的表征,U-Net的一些扩展采用了多尺度特征提取和融合模块,并获得更好的性能。受此启发,我们提出了用于医学图像分割的TransCeption,这是一个纯粹的基于变换器的U型网络,其特点是将inception-like模块纳入编码器,并采用上下文桥来实现更好的特征融合。这项工作中提出的设计是基于三个核心原则。(1) 编码器中的补丁合并模块被重新设计为ResInception Patch Merging(RIPM)。多分支变换器(MB transformer)采用与RIPM的输出相同的分支数量。结合这两个模块,使模型能够在一个阶段内捕获多尺度的表现。(2) 我们在MB变换器之后构建了一个阶段内特征融合(IFF)模块,以加强来自所有分支的特征图的聚合,并特别关注所有尺度的不同通道之间的互动。(3) 与只包含token-wise self-attention的桥相比,我们提出了一个双变换器桥,它也包含channel-wise self-attention,从双重角度利用不同阶段的尺度之间的相关性。在多器官和皮肤病变分割任务上进行的大量实验表明,与以前的工作相比,TransCeption的性能更优越。
该代码可在https://github.com/mindflow-institue/TransCeption上公开获取。
While CNN-based methods have been the cornerstone of medical image segmentation due to their promising performance and robustness, they suffer from limitations in capturing long-range dependencies. Transformer-based approaches are currently prevailing since they enlarge the reception field to model global contextual correlation. To further extract rich representations, some extensions of the U-Net employ multi-scale feature extraction and fusion modules and obtain improved performance. Inspired by this idea, we propose TransCeption for medical image segmentation, a pure transformer-based U-shape network featured by incorporating the inception-like module into the encoder and adopting a contextual bridge for better feature fusion. The design proposed in this work is based on three core principles: (1) The patch merging module in the encoder is redesigned with ResInception Patch Merging (RIPM). Multi-branch transformer (MB transformer) adopts the same number of branches as the outputs of RIPM. Combining the two modules enables the model to capture a multi-scale representation within a single stage. (2) We construct an Intra-stage Feature Fusion (IFF) module following the MB transformer to enhance the aggregation of feature maps from all the branches and particularly focus on the interaction between the different channels of all the scales. (3) In contrast to a bridge that only contains token-wise self-attention, we propose a Dual Transformer Bridge that also includes channel-wise self-attention to exploit correlations between scales at different stages from a dual perspective. Extensive experiments on multi-organ and skin lesion segmentation tasks present the superior performance of TransCeption compared to previous work.
Subjects: cs.LG
1.Train Hard, Fight Easy: Robust Meta Reinforcement Learning

标题:艰苦训练,轻松战斗:强大的元强化学习
作者:Reza Azad, Yiwei Jia, Ehsan Khodapanah Aghdam, Julien Cohen-Adad, Dorit Merhof
文章链接:https://arxiv.org/abs/2301.11259v1
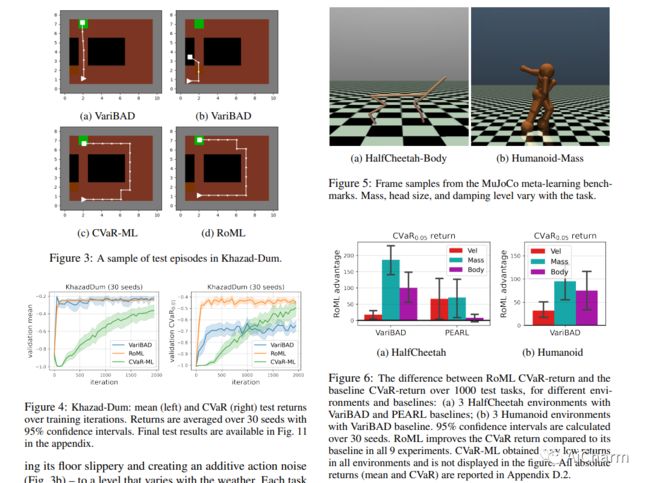
摘要:
强化学习(RL)在现实世界应用中的一个主要挑战是环境、任务或客户之间的变化。元强化学习(MRL)通过学习适应新任务的元策略来解决这个问题。标准的MRL方法优化了任务的平均回报率,但在高风险或高难度的任务中往往会出现不良结果。只要事先不知道测试任务,这就限制了系统的可靠性。在这项工作中,我们提出了一个具有可控稳健性水平的稳健MRL目标。RL中类似的鲁棒性目标的优化往往会导致有偏差的梯度和数据的低效率。我们证明前者在MRL中消失了,并通过新颖的鲁棒元RL算法(RoML)解决了后者的问题。RoML是一种元算法,通过在整个训练过程中识别和过度取样较难的任务,生成任何给定的MRL算法的稳健版本。我们证明,RoML可以学习不同的元政策,并在几个导航和连续控制的基准上实现稳健的回报。
A major challenge of reinforcement learning (RL) in real-world applications is the variation between environments, tasks or clients. Meta-RL (MRL) addresses this issue by learning a meta-policy that adapts to new tasks. Standard MRL methods optimize the average return over tasks, but often suffer from poor results in tasks of high risk or difficulty. This limits system reliability whenever test tasks are not known in advance. In this work, we propose a robust MRL objective with a controlled robustness level. Optimization of analogous robust objectives in RL often leads to both biased gradients and data inefficiency. We prove that the former disappears in MRL, and address the latter via the novel Robust Meta RL algorithm (RoML). RoML is a meta-algorithm that generates a robust version of any given MRL algorithm, by identifying and over-sampling harder tasks throughout training. We demonstrate that RoML learns substantially different meta-policies and achieves robust returns on several navigation and continuous control benchmarks.