SiamRPN:利用区域建议孪生网络进行视频跟踪
目录
- 论文下载地址
- 代码下载地址
- 论文作者
- 模型讲解
-
- [模型结构]
- [模型创新]
- [损失函数]
- [训练过程]
- [结果分析]
- 传送门
论文下载地址
SiamRPN论文地址
SiamRPN论文百度网盘下载地址 ❗提取码:26sn❗
SiamRPN论文翻译(水印)百度网盘下载地址 ❗提取码:uylp❗
SiamRPN论文翻译(无水印PDF+Word)下载地址
代码下载地址
[GitHub]
[百度网盘] ❗提取码:5meh❗
[预训练权重百度网盘下载地址] ❗提取码:jnur❗
论文作者
模型讲解
[模型结构]
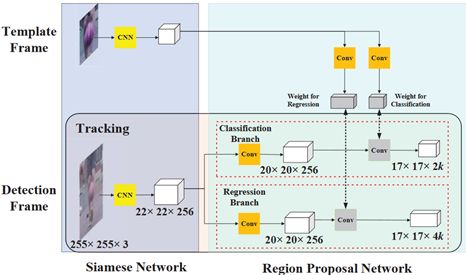
与SiamFC相似,SiamRPN同样具有孪生结构,两个分支的权重共享,两个分支分别输入一张图片,提取每张图片的特征。如下图所示,上面的Template Frame相当于模板图像,下面的Detection Frame相当于搜索图像。将两个图像输入CNN网络进行特征提取,然后输入互相关层。
这里作者引入了RPN网络,首先先对RPN网络的相关知识进行介绍:
[grid]
grid中文译为格,如下图是YOLO论文中的一张图,grid就是指的对一张图像或者是featuremap进行平均地分割,但是并不一定是一个像素对应一个grid,也可能是多个像素对应一个grid。所有grid组成一个Proposal。
[anchors]
anchors可以翻译成锚点,指的是在boundingbox生成之前会先在每个grid上生成一些候选框,然后将这些anchors候选框进行后续操作,生成boundingbox。
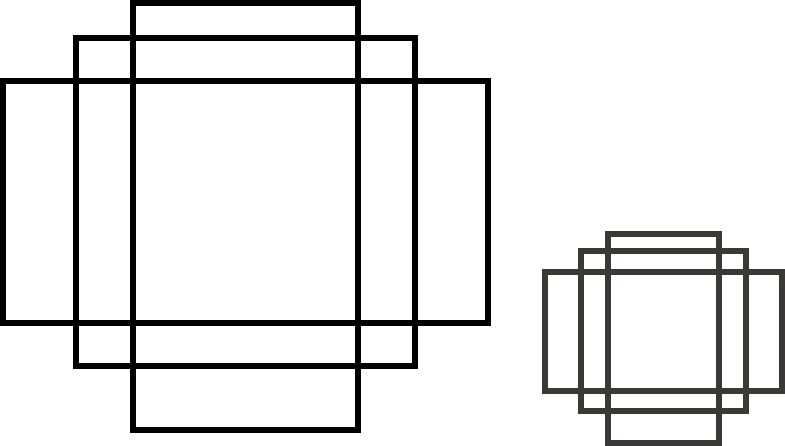
一般候选框会有一些固定的参数,首先是长宽比,例如上图左边的三个anchors对应一个grid生成的三种不同长宽比的anchors,一般长宽比的数目都是固定的而且长宽比互为倒数,比如{0.5,1,2};其次,是尺度大小,也就是anchors的面积,一般同一个featuremap下的grid都是看作生成相同尺度的anchors,经过不同层的featuremap对应不同的尺度,也就生成不同尺度的anchors,例如左边和右边尺度不同的anchors。
[分类分支]
例如,在s×s的grid区域内,每一个grid都会生成k种不同长宽比的anchors。那经过分类分支会生成一个s×s×k的分类的标签,也就是说一个anchor会生成一个标签,如果是目标的anchors则为1,anchor是背景的则为0。
[回归分支]
anchors具有固定的长宽比,不能直接拿来做boundingbox,要对其进行一个回归操作。早期的回归分支是通过平移、缩放等操作进行回归,网络需要学习的就是变换过程的参数。如今,回归的操作还有经过卷积等操作,直接输出boundingbox的位置和大小。
[NMS]
NMS全称是Non-Maximum Suppression,译为非极大值抑制。NMS可以理解为不是极大值就抑制它。如下图所示,有两个anchors都分类为狗,这时会计算两个框之间的IoU,如果大于某个阈值,则认为两个框检测的是同一个物体,将得分高的框保留,得分低的框去除。图中红色框得分0.9,绿色得分0.7,两个框的IoU大于某个阈值,则只保留红色来检测狗的位置。
[RPN]
RPN的全称是RegionProposal Network,译为区域建议网络。RPN可以理解为,从一张图像或者featuremap选择一个区域,生成anchors。RPN具有两个分支,一个是分类分支,一个是回归分支。
再回到SiamRPN的网络结构:

网络输入模板图像为127×127,搜索图像为255×255,两个图像经过CNN分别生成6×6×256和22×22×256的featuremap。之后分别将两个featuremap复制到分类分支和回归分支中,注意这里的卷积的权重是不共享的。
在分类分支中,模板featuremap和搜索featuremap经过卷积层分别输出4×4×(2k×256)和20×20×256的featuremap,这里k为每个grid生成k个anchors,anchors的长宽比为[0.33,0.5,1,2,3],图中‘⭐’是卷积的操作,两个featuremap相互卷积,这里先256个通道相互卷积,加权求和生成一个通道,所以生成17×17×2k的featuremap,这里相当于将搜索图像划分为17×17 个grid,每个grid生成k个anchors,每两个通道是一组,一共k组对应k个anchors。第一个通道中,目标的anchors是1,背景是0;第二个通道中,背景是1,目标是0。
在回归分支中,两个featuremap经过卷积层分别生成4×4×(4k×256)和20×20×256,这里k为每个grid生成k个anchors,‘⭐’是卷积的操作,与分类分支的操作相同,生成17×17×4k的featuremap,每四个是一组,一共k组对应k个anchors。四组分别对应boundingbox的四个值dx、dy、dw、dh,是anchor与真值的距离。
[模型创新]
[区域选择]
为了使单目标检测框架适合于跟踪任务,作者提出了两种选择方案的策略。
第一个区域选择策略是丢弃anchors产生的边界框,该边界框离中心太远。例如,我们只将中心g×g子区域保留在 A w × h × 2 k c l s A^{cls}_{w×h×2k} Aw×h×2kcls分类特征图上,以获取g×g×k个anchors,而不是m×n×k(这里是17×17×k)个anchors。由于相邻帧总是没有大的运动,因此丢弃策略可以有效地去除异常值。下图是在分类特征图中选择距离中心不超过7的目标anchors的图示。

第二种方案选择策略是使用余弦窗并通过尺度转换惩罚对提案的得分进行重新排序,以获得最佳分数。丢弃异常值后,添加汉明窗以抑制大位移:
hanning = np.hanning(score_size)
window = np.outer(hanning, hanning)
window = np.tile(window.flatten(), self.anchor_num)
然后添加惩罚以抑制尺寸和比率的大变化: penalty = e k ∗ max ( r r ′ , r ′ r ) ∗ max ( s s ′ , s ′ s ) \text { penalty }=e^{k{*} \max \left(\frac{r}{r^{\prime}}, \frac{r^{\prime}}{r}\right){*} \max \left(\frac{s}{s^{\prime}}, \frac{s^{\prime}}{s}\right)} penalty =ek∗max(r′r,rr′)∗max(s′s,ss′)其中 r r r和 r ′ r' r′代表第一帧和最后一帧的长宽比, s s s和 s ′ s' s′代表第一帧和最后一帧的总体规模,公式中的 k k k是一个超参数。,可以从作者的代码中找到:
penalty = np.exp(-(r_c * s_c - 1) * cfg.TRACK.PENALTY_K)
pscore = penalty * score
pscore = pscore * (1 - cfg.TRACK.WINDOW_INFLUENCE) + window * cfg.TRACK.WINDOW_INFLUENCE
其中r_c,s_c为长宽比和面积的最大变化值,cfg.TRACK.PENALTY_K作者默认为0.04。pscore 由惩罚(越大越好)与分类得分相乘,cfg.TRACK.WINDOW_INFLUENCE作者默认为0.44,结合了尺度变化、面积变化、位移变化和分类得分。重新对anchors进行排名。之后执行非最大抑制(NMS)以获得最终跟踪边界框。选择最终边界框后,通过线性插值更新目标大小,以保持形状的平滑变化。
[anchors的选择]
由于目标在两个相邻框架内的比例变化不大,所以在固定锚的比例时,作者只考虑锚的不同比例。尝试三种比率,[0.5,1,2]、[0.33,0.5,1,2,3]、[0.25,0.33,0.5,1,2,3,4] (分别表示为 A 3 A_3 A3, A 5 A_5 A5, A 7 A_7 A7)。
如下表所示。 A 5 A_5 A5跟踪器的性能优于 A 3 A_3 A3跟踪器,因为通过更多的锚来预测高宽比大的目标形状更容易。然而, A 7 A_7 A7跟踪器无法持续改善性能,作者认为这可能是由于过度使用长宽比造成的。当添加更多Youtube-BB的培训数据时, A 7 A_7 A7和 A 5 A_5 A5之间的EAO差距从0.013减小到0.007。

[损失函数]
作者使用了Faster R-CNN中使用的损失函数。分类损失为交叉熵损失,采用归一化坐标的smooth L1 损失进行回归。 A x A_{x} Ax, A y A_{y} Ay, A w A_{w} Aw, A h A_{h} Ah表示anchors的中心点和形状, T x T_{x} Tx, T y T_{y} Ty, T w T_{w} Tw, T h T_{h} Th表示groundtruth的中心点和形状,标准化距离为: δ [ 0 ] = T x − A x A w , δ [ 1 ] = T y − A y A j δ [ 2 ] = ln ( T w A w ) , δ [ 3 ] = ln ( T h A h ) \begin{array}{l}{\delta[0]=\frac{T_{x}-A_{x}}{A_{w}}, \delta[1]=\frac{T_{y}-A_{y}}{A_{j}}} \\ {\delta[2]=\ln \left(\frac{T_{w}}{A_{w}}\right), \delta[3]=\ln \left(\frac{T_{h}}{A_{h}}\right)}\end{array} δ[0]=AwTx−Ax,δ[1]=AjTy−Ayδ[2]=ln(AwTw),δ[3]=ln(AhTh)然后经过smooth L1损失: smooth L1 ( x , σ ) = { 0.5 σ 2 x 2 ∣ x ∣ < 1 σ 2 ∣ x ∣ − 1 2 σ 2 ∣ x ∣ ≥ 1 σ 2 \text {{smooth} L1}(x, \sigma)=\left\{\begin{array}{ll}{0.5 \sigma^{2} x^{2}} & {|x|<\frac{1}{\sigma^{2}}} \\ {|x|-\frac{1}{2 \sigma^{2}}} & {|x| \geq \frac{1}{\sigma^{2}}}\end{array}\right. smooth L1(x,σ)={0.5σ2x2∣x∣−2σ21∣x∣<σ21∣x∣≥σ21 L r e g = ∑ i = 0 3 s m o o t h L . 1 ( δ [ i ] , σ ) L_{r e g}=\sum_{i=0}^{3} s m o o t h_{L .1}(\delta[i], \sigma) Lreg=i=0∑3smoothL.1(δ[i],σ) loss = L c l s + λ L r e g \operatorname{loss} =L_{cls}+\lambda L_{r e g} loss=Lcls+λLreg
[训练过程]
| 训练属性 | 参数取值 |
|---|---|
| 梯度下降 | SGD |
| 迭代次数 | 50 |
| 每次迭代样本数 | 280 |
| 学习率 | 1 0 − 2 − 1 0 − 6 10^{-2}-{10^{-6}} 10−2−10−6 |
| 框架 | Pytorch |
| 配置 | Inteli7、12G RAM、Nvidia GTX 1060 |
[结果分析]
[OTB]
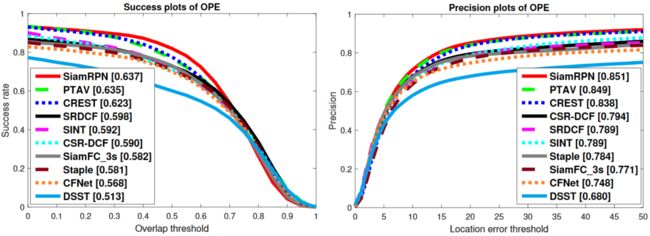
作者将此方法与PTAV、CREST、SRDCF、SINT、CSR-DCF、SiamFC、STAP、CFNET和DSST等几种代表性跟踪器进行了比较。如下图所示,所建议的SiamRPN能够在成功图和精确图中显示。
[VOT]
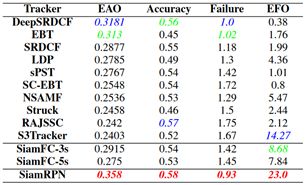
在VOT2015数据集上,根据最新的VOT规则,我们将跟踪器与前10名跟踪器进行了比较。将SiamFC作为我们的基准。下图显示SiamRPN在VOT2015中的表现优于其他跟踪器。下表列出了有关跟踪程序的详细信息。如表所示SiamRPN能对EAO、准确性、失败率和EFO进行检测。在VOT2015报告中的所有跟踪器中,只有少数跟踪器能够实时跟踪,但它们的预期重叠度相对较低。SiamFC是VOT2015上的顶级追踪器之一,它可以以超过实时的帧速率运行,并达到最先进的性能。SiamRPN能够以160 fps的速度运行,这几乎是SiamFC(86 fps)的两倍,而EAO的相对增长率为23%。

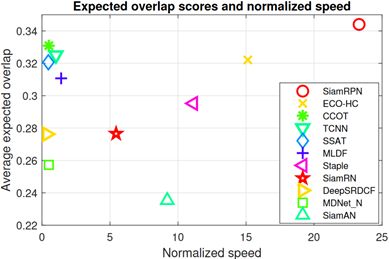
在VOT2016数据集上,我们将跟踪器与VOT2016中的前25个跟踪器进行了比较。SiamRPN可以超过所有的挑战条目。图6显示了EAO的排名,表2显示了一些最先进的跟踪器的详细信息。如下图所示,我们的跟踪器可以在160 fps的速度下根据EAO排名第一,这比CCOT快500倍。如下表所示,SiamRPN在EAO、Accuracy和EFO上排名第一,以及第3的失败率。下图显示了最先进的跟踪器的性能和速度。它表明我们的跟踪器可以在高速运行时获得卓越的性能。


在VOT2017数据集上,跟踪器需要处理至少25fps的实时视频流。这意味着如果跟踪器在40毫秒内无法处理结果,评估器将使用最后一帧的边界框作为当前帧的结果。几乎所有最先进的追踪器都面临着巨大的挑战。在无速度限制条件下,原始EAO排名前10位的跟踪器在实时实验中的EAO值较低。下图显示了SiamRPN以及VOT2017报告中列出的几个实时跟踪器。相比之下,SiamRPN可根据EAO的要求排名第一。具体来说,它可以超过在第二位的CSRDCF++14%,超过在第三位的SiamFC33%。

[Youtube-BB]
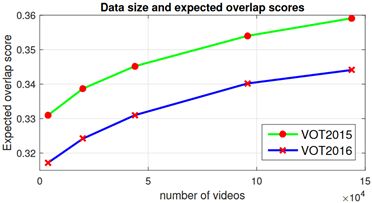
Youtube-BB包含超过100000个每30帧注释一次的视频。我们通过逐渐增加Youtube-BB的更多数据来训练具有不同数据集大小的SiamRPN。下图说明了训练数据大小变化时SiamRPN的跟踪结果。当有更多的训练视频时,VOT2015和VOT2016的EAO都会不断增加。具体来说,Youtube-BB的推出将VOT2016的EAO从0.317提升到0.344。值得注意的是,性能并不收敛,这意味着随着训练数据的增加,跟踪器的性能可能会变得更好。
传送门
视频跟踪
视频跟踪数据集指标分析
SiamFC:利用全卷积孪生网络进行视频跟踪
SiamRPN:利用区域建议孪生网络进行视频跟踪
DaSiamRPN:用于视觉跟踪的干扰意识的孪生网络
SiamRPN++: 基于深度网络的孪生视觉跟踪的进化
SiamMask: 快速在线目标跟踪与分割的统一方法