《动手深度学习》4.10. 实战Kaggle比赛:预测房价
4.10. 实战Kaggle比赛:预测房价
-
- 本节内容预览
- 数据
-
- 下载和缓存数据集
- 访问和读取数据集
-
- 使用pandas读入并处理数据
- 数据预处理
-
- 处理缺失值&对数值类数据标准化
- 处理离散值—one-hot编码
- 最后,转换为张量表示
- 训练
-
-
- 先用简单线性模型进行数据验证
-
- K折交叉验证
- 模型选择
- 提交Kaggle
- python语法
-
- Pandas使用
-
- 计算MSZoning列的重复值
- torch.clamp(input, min, max)
本节内容预览
- 真实数据通常混合了不同的数据类型,需要进行预处理。
- 常用的预处理方法:将实值数据重新缩放为零均值和单位方法;用均值替换缺失值。
- 将类别特征转化为指标特征,可以使我们把这个特征当作一个one-hot向量来对待。
- 我们可以使用K折交叉验证来选择模型并调整超参数。
- 对数对于相对误差很有用。
数据
下载和缓存数据集
书中为此特意设置了几个函数,方便数据集的下载:download函数用来下载数据集缓存在本地
访问和读取数据集
数据每条记录都包括房屋的属性值和属性,如街道类型、施工年份、屋顶类型、地下室状况等。 这些特征由各种数据类型组成,以及一些缺失值“NA”。
使用pandas读入并处理数据
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
- 使用上面定义的脚本下载并缓存Kaggle房屋数据集。
DATA_HUB['kaggle_house_train'] = ( #@save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = ( #@save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
- 使用pandas分别加载包含训练数据和测试数据的两个CSV文件:
- 训练数据集包括1460个样本,每个样本80个特征和1个标签, 而测试数据集包含1459个样本,每个样本80个特征。
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
#如果已经下载好了可以直接读取
#train_data = pd.read_csv('C:/Users/data/kaggle_house_pred_train.csv')
#test_data = pd.read_csv('C:/Users/data/kaggle_house_pred_test.csv')
print(train_data.shape)
print(test_data.shape)

- 索引一部分特征及相应标签并输出看看——输出了前5行数据(0:5),这里特征(列)只选择了前4个(0,1,2,3)和最后2个(-3,-2),以及对应的标签(SalePrice房价)(-1)。
- ⭐⭐关于pandas是如何索引的
print(train_data.iloc[0:5, [0, 1, 2, 3, -3, -2, -1]])

- 在每个样本中,第一个特征是ID, 这有助于模型识别每个训练样本。 虽然这很方便,但它不携带任何用于预测的信息。 因此,在将数据提供给模型之前,我们将其从数据集中删除。
#拼接训练数据和测试数据(不包括标签列),同时删除Id列
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
数据预处理
处理缺失值&对数值类数据标准化
- 首先,我们将所有缺失的值替换为相应特征的平均值。
- 然后,标准化数据:将特征重新缩放到零均值和单位方差。
- 我们标准化数据有两个原因:
- ①它方便优化;
- ②因为我们不知道哪些特征是相关的, 所以我们不想让惩罚分配给一个特征的系数比分配给其他任何特征的系数更大。
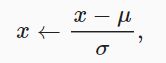
# 若无法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index #获得类型不是'object'的特征的index(列名),即获取所有的数据列
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std())) # 对获得到的所有数据列进行规范化
# 在标准化数据之后,所有均值都是0,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
处理离散值—one-hot编码
- 以“MSZoning”列为例,用独热编码替换它们。
- 例如,“MSZoning”包含值“RL”和“Rm”。
我们将创建两个新的指示器特征“MSZoning_RL”和“MSZoning_RM”,其值为0或1。 - 根据独热编码,如果“MSZoning”的原始值为“RL”, 则:“MSZoning_RL”为1,“MSZoning_RM”为0。
pandas软件包会自动为我们实现这一点。将原本all_features.shape由(2919,79)增加到了(2919,331)
# 接下来用独热编码替换处理离散值,也就是类型是'object'的列,如'MSZoning'
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features[['MSZoning_RL']],all_features[['MSZoning_RM']],all_features[['MSZoning_FV']]



最后,转换为张量表示
通过values属性,我们可以从pandas格式中提取NumPy格式,并将其转换为张量表示用于训练。
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
训练
先用简单线性模型进行数据验证
- 显然线性模型很难让我们在竞赛中获胜,但线性模型提供了一种健全性检查, 以查看数据中是否存在有意义的信息。
- 如果我们在这里不能做得比随机猜测更好,那么我们很可能存在数据处理错误。
- 如果一切顺利,线性模型将作为基线(baseline)模型, 让我们直观地知道最好的模型有超出简单的模型多少。
- 使用均方损失函数MSELoss
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return net
- 改进为对数均方根误差
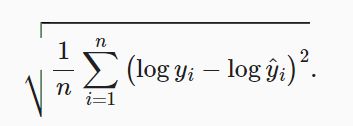
理由:房价就像股票价格一样,我们关心的是相对误差,而不是绝对误差。比如房价原本12.5万,误差10万;和房价原本420万,误差10万;显然是不一样的。即:
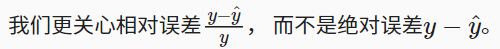
解决这个问题的一种方法是用预测价格的对数来衡量差异。这也是比赛中官方用来评价提交质量的误差指标。
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf')) #torch.clamp(input, min, max)将input控制在[1,inf]内
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
- 训练函数:使用Adam优化器
与前面的部分不同,我们的训练函数将借助Adam优化器,Adam优化器的主要优势在于它对初始学习率不那么敏感。
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
K折交叉验证
- 首先需要定义一个函数,在K折交叉验证过程中返回第i折的数据。
- 具体地说,它选择第i个切片作为验证数据,其余部分作为训练数据。
- 注意,这并不是处理数据的最有效方法,如果我们的数据集大得多,会有其他解决办法。
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
- 当我们在K折交叉验证中训练次后,返回训练和验证误差的平均值。
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
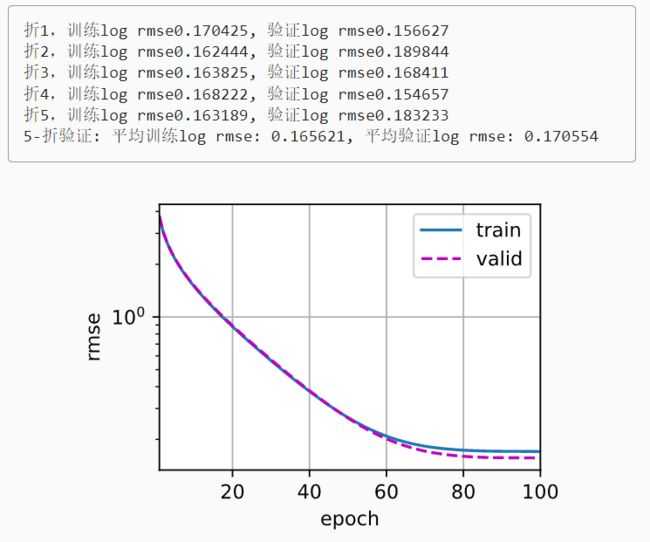
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
模型选择
有了足够大的数据集和合理设置的超参数,折交叉验证往往对多次测试具有相当的稳定性。 然而,如果我们尝试了不合理的超参数,我们可能会发现验证效果不再代表真正的误差。
通过K折交叉验证确定合适的超参数:
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')
请注意:
- 有时一组超参数的训练误差可能非常低,但折交叉验证的误差要高得多, 这表明模型过拟合了。
- 在整个训练过程中,你将希望监控训练误差和验证误差这两个数字。 较少的过拟合可能表明现有数据可以支撑一个更强大的模型,
较大的过拟合可能意味着我们可以通过正则化技术来获益。
提交Kaggle
- 确定好模型参数后,使用所有数据对其进行训练 (而不是仅使用交叉验证中使用的1-1/k的数据)。
- 然后,我们通过这种方式获得的模型可以应用于测试集。 将预测保存在CSV文件中可以简化将结果上传到Kaggle的过程。
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
如果测试集上的预测与倍交叉验证过程中的预测相似, 那就是时候把它们上传到Kaggle了。 下面的代码将生成一个名为submission.csv的文件。
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
提交预测到Kaggle上,即可查看在测试集上的预测与实际房价(标签)的比较情况。
python语法
Pandas使用
计算MSZoning列的重复值
-
使用drop_duplicates:
all_features.drop_duplicates(subset=['MSZoning'])- 筛选后打印出所有列

- 筛选后只打印出所筛选列

- 代码如下:
- 筛选后打印出所有列
# 打印所有列
all_features.drop_duplicates(subset=['MSZoning'])
# 只打印所筛选列,即在上一个基础上再索引所需列
all_features.drop_duplicates(subset=['MSZoning'])[['MSZoning']]
-
使用duplicated()
all_features[['MSZoning']].duplicated() == True/False-
识别各数据是否重复,输出bool值, False表示第一次出现,未重复

-
打印出所有未重复项(筛选后输出所有列)

-
打印出所有未重复项(筛选后输出所需列)
-
-
计算重复次数value_counts():
all_features[['MSZoning']].value_counts()注意!NAN这种缺失值是不被计入的,所以显示只有5行。

torch.clamp(input, min, max)
torch.clamp(input, min, max)将input控制在[1,inf]内