python数据分析
matplotlib介绍
快速上手demo
matplotlib.pyplot包含了一系列matlab的图像函数
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure() #创建画布
plt.plot([1,0,9],[4,5,6]) #绘制图像
plt.show() #显示图像
运行结果:

matlibpot的三层结构
容器层
辅助显示层
图像层
设置画图属性与保存图像
- plt.figure(figsize=(),dpi=)
figsize图像长宽
dpi图像清晰度
plt.figure(figsize=(10,10),dpi=80)
- plt.savefig(路径)
plt.savefig('111.png')
修改x、y轴刻度
- plt.xticks(x[::5]) 修改x轴刻度
x要显示的刻度值
[::5]表示步长是5 - plt.yticks(y[::5]) 修改y轴刻度
y要显示的刻度值
[::5]表示步长是5
x轴步长5,y轴步长2
import matplotlib.pyplot as plt
import random
plt.figure(figsize=(10,10),dpi=80)
x=range(60)
y_shanghai=[random.uniform(15,18) for i in x]
plt.xticks(x[::5])
plt.yticks(y_shanghai[::2])
plt.plot(x,y_shanghai)
plt.show()
运行结果:

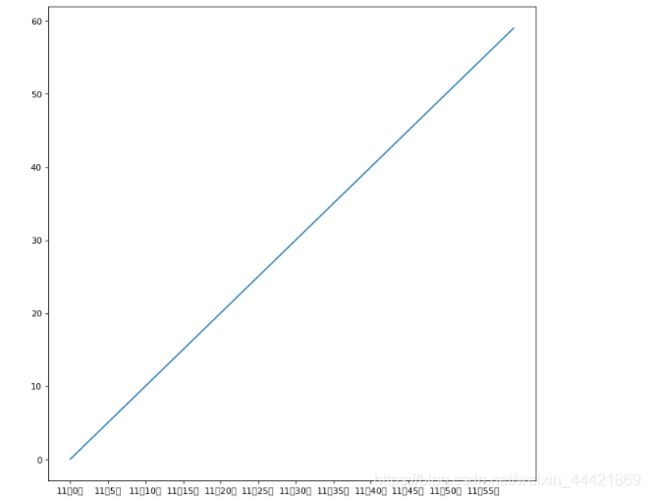
中文坐标系
import matplotlib.pyplot as plt
import random
plt.figure(figsize=(10,10),dpi=80)
x=range(60)
x_lable=["11点{}分".format(i) for i in x]
plt.xticks(x[::5],x_lable[::5])
plt.plot(x_lable,x)
plt.show()
运行结果:
添加网格显示
- pld.grid(True,linestyle="–",alpha=0.5)
属性:
True指是否添加网格
linestyle指线条风格
alpha指线条透明度
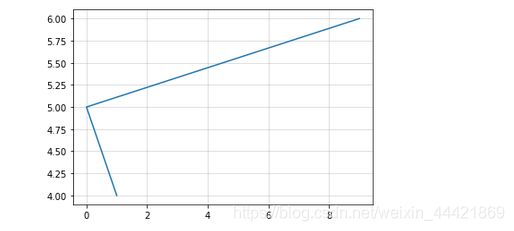
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.plot([1,0,9],[4,5,6])
plt.grid(True,linestyle="--",alpha=0.5)
plt.show()
运行结果:
 添加描述信息
添加描述信息
- plt.xlabel(“时间”)
- plt.ylabel(“温度”)
- plt.title(“温度显示图”)
demo:
import matplotlib.pyplot as plt
%matplotlib inline
plt.xlabel("时间")
plt.ylabel("温度")
plt.title("温度显示图")
plt.figure()
plt.plot([1,0,9],[4,5,6])
plt.grid(True,linestyle="-",alpha=0.5)
plt.show()
运行结果:
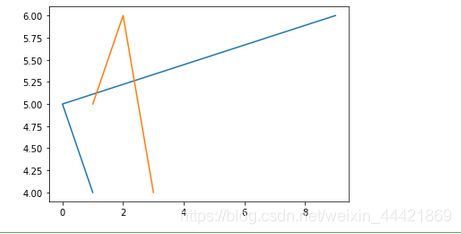
2个及以上线条
绘制两个图形即可
demo:
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.plot([1,0,9],[4,5,6])
plt.plot([1,2,3],[5,6,4])
plt.show()
运行结果:
线条属性设置
color线条颜色
linestyle线条类型
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.plot([1,0,9],[4,5,6],color="b",linestyle="--")
plt.plot([1,2,3],[5,6,4],color="g",linestyle="--")
plt.show()
运行结果:

图例
- plt.legend(loc=1)
属性:
loc指图例位置,0-6分别指不同位置
demo:
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.plot([1,0,9],[4,5,6],color="b",linestyle="--",label="上海")
plt.plot([1,2,3],[5,6,4],color="g",label="北京")
#显示图例
plt.legend(loc=1)
plt.show()
运行结果:

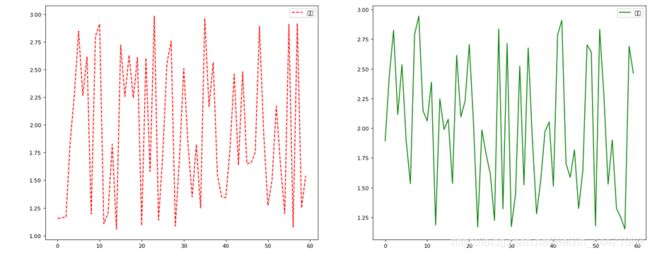
在一个画布上创建多个绘图区
figure,axes=plt.subplots(nrows=1,ncols=2,figsize=(20,8),dpi=80)
demo:
import matplotlib.pyplot as plt
import random
# 1.准备数据
x=range(60)
y_shanghai=[random.uniform(1,3) for i in x]
y_beijing=[random.uniform(1,3) for i in x]
#2.创建画布
# plt.figure()
figure,axes=plt.subplots(nrows=1,ncols=2,figsize=(20,8),dpi=80)
#3.开始画图
axes[0].plot(x,y_shanghai,color="r",linestyle="--",label="上海")
axes[1].plot(x,y_beijing,color="g",label="北京")
#4.显示图例
axes[0].legend()
axes[1].legend()
# 5.显示图
plt.show()
运行结果:
Numpy介绍
创建一个数组
import numpy as np
#方式一:
t1=np.array([1,2,3])
print(t1)
#[1 2 3]
#方式二:
t2=np.array(range(10))
print(t2)
#[0 1 2 3 4 5 6 7 8 9]
#方式三:
t3=np.arange(10)
print(t3)
#[0 1 2 3 4 5 6 7 8 9]
#创建一个起始是2,步长为2的数组,10取不到
t4=np.arange(2,10,2)
print(t4)
#[2 4 6 8]
pandas介绍
python处理excel之openpyxl(工具使用)
excel的新建、读取和保存
创建工作簿
import openpyxl
wb=openpyxl.Workbook() #新建工作簿
wb.save('我的工作簿.xlsx') #保存工作簿
读取工作簿和保存工作簿
import openpyxl
wb=openpyxl.load_workbook('我的工作簿.xlsx') #读取工作簿
wb.save('我的工作簿-1.xlsx')
细节:
- 工作簿打开的情况下,保存会出错
- 每次操作操作完,都要保存工作簿
批量创建工作簿
import openpyxl
for m in range(1,13):
wb=openpyxl.Workbook() #新建工作簿
wb.save('%d月.xlsx'%m) #保存工作簿
工作表对象的获取方法
各年业绩表.xlsx 工作簿:
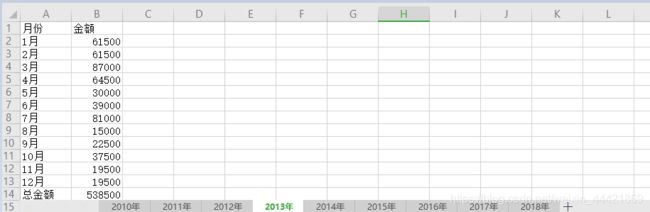
以索引值方式获取工作表
以工作表名获取工作表
import openpyxl
wb=openpyxl.load_workbook(r'各年业绩表.xlsx')
ws2=wb.worksheets[2] #以索引值方式获取工作表
ws3=wb['2012年'] #以工作表名获取工作表
print(ws2)
print(ws3)
运行结果:

循环工作表
import openpyxl
wb=openpyxl.load_workbook('各年业绩表.xlsx') #读取工作簿
for sh in wb.worksheets: #遍历所有工作表
print(sh)
运行结果:

获取所有工作表
import openpyxl
wb=openpyxl.load_workbook('各年业绩表.xlsx')
print(wb.sheetnames) #获取所有工作表
运行结果:
![]()
批量修改工作表名称
import openpyxl
wb=openpyxl.load_workbook('各年业绩表.xlsx')
for sh in wb.worksheets: #遍历所有工作表
sh.title=sh.title+'-芝华公司' #修改工作表名称
wb.save('各年业绩表(修改后11).xlsx')
运行结果:
![]()
工作表的新建复制和删除
在指定位置创建工作表
import openpyxl
wb=openpyxl.load_workbook('demo2.xlsx')
wb.create_sheet('工资表',2) #在指定位置创建工作表,默认则是在最后创建
wb.save('demo2.xlsx')
运行结果:
![]()
复制工作表
将工作簿demo3.xlsx下的工资表,复制到工作簿demo3-1.xlsx下,并命名为工资表1月
import openpyxl
wb=openpyxl.load_workbook('demo3.xlsx')
wb.copy_worksheet(wb['工资表']).title='工资表1月'
wb.save('demo3-1.xlsx')
删除指定工作表
import openpyxl
wb=openpyxl.load_workbook('demo3-1.xlsx')
wb.remove(wb['工资表'])
wb.save('demo3-1.xlsx')
批量创建工作表
import openpyxl
wb=openpyxl.Workbook() #创建工作簿
for m in range(1,13):
wb.create_sheet('%d月'%m) #批量创建工作表
wb.remove(wb['Sheet']) #删除第一个工作表
wb.save('2019年计划表.xlsx')
运行结果:

单元格信息获取

方法一:工作表[‘b1’]
import openpyxl
wb=openpyxl.load_workbook('demo.xlsx')
ws=wb.worksheets[0]
print(ws['a1'].value)
运行结果:

方法二:工作表.cell[行号,列号]
import openpyxl
wb=openpyxl.load_workbook('demo.xlsx')
ws=wb.worksheets[0]
print(ws.cell(1,1).value)
运行结果:
![]()
实例应用(汇总各表各单元格数据)
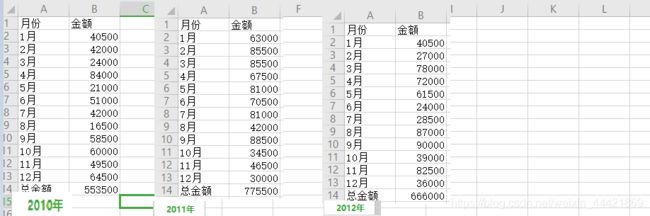
import openpyxl
wb=openpyxl.load_workbook('各年业绩表.xlsx')
for sh in wb.worksheets:
#print(sh['b14'].value)
print(sh.cell(14,2).value)
区域单元格信息获取
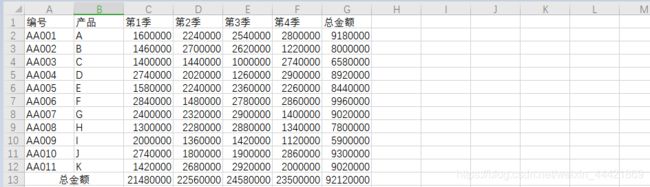
方法一:工作表[‘起始单元格’:‘终止单元格’] 如:wb[‘a1’:‘b3’] 此方法是按行读取
import openpyxl
wb=openpyxl.load_workbook('demo.xlsx',data_only=True) #data_only表示只读取数据,公式等不读取
ws=wb.active
for sh in ws['a1':'g2']:
for row in sh:
print(row.value)
运行结果:

方法二:工作表[‘起始行号’:‘结束行号’] 如:wb[‘1’:‘3’] 此方法按照行来读取
import openpyxl
wb=openpyxl.load_workbook('demo.xlsx',data_only=True) #data_only表示只读取数据,公式等不读取
ws=wb.active
for sh in ws['1':'2']:
for row in sh:
print(row.value)
运行结果:

方法三:工作表[‘起始列号’:‘结束列号’] 如:wb[‘a’:‘b’] 此方法按照列来读取
import openpyxl
wb=openpyxl.load_workbook('demo.xlsx',data_only=True) #data_only表示只读取数据,公式等不读取
ws=wb.active
for sh in ws['a':'b']:
for col in sh:
print(col.value)
运行结果:

单元格的写入
方法一:工作表[‘a1’]=值
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.worksheets[1]
ws['a1']=123
wb.save('test.xlsx')
方法二:工作表.cell(行号,列号,值)
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.worksheets[1]
ws.cell(2,3,'我是中国人')
wb.save('test.xlsx')
批量写入数据
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.worksheets[0]
ws.append({'a':'张三','b':56,'c':'fdgsfg'}) #a,b,c表示列
wb.save('test.xlsx')
运行结果:

循环方式批量写入数据
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.worksheets[0]
for row in ws['a1:g9']: #遍历每行
for c in row: #遍历每行中的单元格
c.value=100 #给每个单元格赋值
wb.save('test.xlsx')
运行结果:

实例应用(给>=90分的单元格添加优秀)
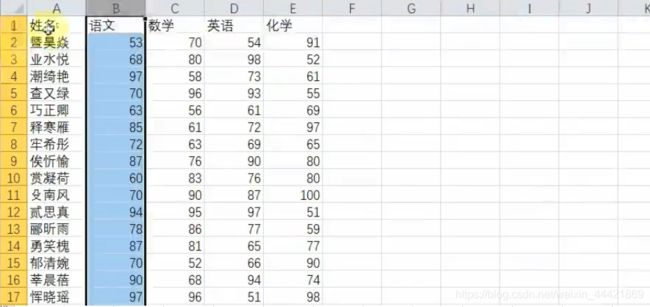
import openpyxl
wb=openpyxl.load_workbook('demo.xlsx')
ws=wb.active
rngs=ws.iter_rows(min_row=2,min_col=2) #获取起始单元格,第2行第2列
for row in rngs: #从起始单元格开始,遍历每行
for c in row: #遍历每行中的每个单元格
if c.value>=90: #获取单元格值,大于等于90
c.value=str(c.value)+'(优秀)'
wb.save('demo1.xlsx')
运行结果:
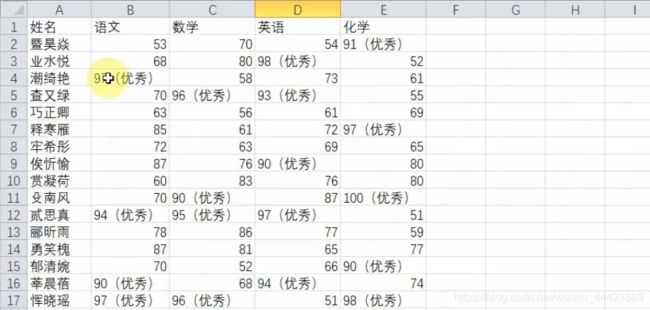
实例分析(4科成绩总分>=300分的,在最后添加优秀)
import openpyxl
wb=openpyxl.load_workbook('demo.xlsx')
ws=wb.active #读取工作表
rngs=ws.iter_rows(min_row=2,min_col=2) #获取起始单元格
#[c.value for c in row]使用推导式,从起始单元格开始,遍历每一行值
#[0:4]表示切片,获取列表中第1个到第4个值
for row in rngs: #从起始单元格开始进行遍历
sm=sum([c.value for c in row][0:4])
if sm>=300:
#row[-1]表示遍历是否优秀单元格
row[-1].value='优秀'
wb.save('demo2.xlsx')
运行结果:

工作表行列的插入与删除
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.worksheets[0]
ws.insert_cols(3,2) #在第3列插入2列
ws.insert_rows(6,4) #在第6行插入4行
ws.delete_cols(5,2) #在第5列删除2列
ws.delete_rows(5,2) #在第5行删除2行
wb.save('test.xlsx')
实例应用(删除总分>=300的行)
import openpyxl
wb=openpyxl.load_workbook('成绩表.xlsx')
ws=wb.active
for r in range(ws.max_row,1,-1): #ws.max_row表示最大行,到最小行,步长为1
s=sum([c.value for c in ws[r]][1:])
if s>=300:
ws.delete_rows(r) #r表示行号
wb.save('成绩表筛选结果.xlsx')
实例应用(求和结果写入新的单元格)
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.worksheets[0]
rngs=ws[2:ws.max_row] #从第二行开始,获取所有单元格
nws=wb.create_sheet('结果') #创建新的工作表
nws.append(['姓名','总分']) #往工作表中添加内容
for row in rngs:
nws.append([row[0].value,sum([c.value for c in row][1:])])
wb.save('test1.xlsx')
运行结果:

实例应用(筛选成绩总分>=300分的记录)
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.active
nws=wb.create_sheet('新的工作表')
nws.append(['成绩'])
for row in list(ws.rows)[1:]:
sm=sum([ch.value for ch in row][1:])
if sm>=300:
nws.append([sm])
wb.save('test.xlsx')
运行结果:

获取行号
import openpyxl
wb=openpyxl.load_workbook('工资表.xlsx',data_only=True)
ws=wb.active
for r in range(ws.max_row,2,-1): #从最大行~第三行,步长是1
print(r)
运行结果:

行列信息获取
按行获取工作表使用区域数据
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
for sh in ws.rows: #按行获取工作表使用区域信息
print([row.value for row in sh]) #使用推导式,获取每行信息
运行结果:

按列获取工作表使用区域的信息
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
for sh in ws.columns: #按列获取工作表使用区域信息
print([col.value for col in sh]) #使用推导式,获取每列信息
运行结果:

获取工作表中最小行号/列号最大行号/列号
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
print(ws.min_row,ws.min_column,ws.max_row,ws.max_column)
运行结果:
![]()
获取工作表中指定单元格的行号和列号
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
print(ws.cell(2,1).row) #获取指定单元格的行号
print(ws.cell(2,1).column) #获取指定单元格的列号
iter方法获取指定区域
通过min_row,min_col,max_row,max_col进行单元格区域的控制
iter_rows方法,指按行
iter_cols方法,指按列

指定最小行号和最小列号,最大默认到最后
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
for ch in ws.iter_rows(min_row=2,min_col=2):
print([r.value for r in ch ])
运行结果:

指定最大行号和最小列号
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
for ch in ws.iter_rows(max_row=8,min_col=2):
print([r.value for r in ch ])
运行结果:


实例应用(按行求和)
方法一:list(ws.rows)[1:]
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
for row in list(ws.rows)[1:]:
#ws.rows获取工作表所有行
#list(ws.rows)装换为list
#[1:]进行切片,第一个到最后
print(row[0].value,sum([ch.value for ch in row][1:]))
运行结果:

方法二:for row in ws.iter_rows(min_row=2,min_col=1):
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb['成绩表'] #按照名称读取工作表
for row in ws.iter_rows(min_row=2,min_col=1):
print(row[0].value,sum([ch.value for ch in row][1:]))
运行结果: