基于EMR离线数据分析(阿里云)
场景体验目标
数据量爆发式增长的今天,数字化转型成为IT行业的热点,数据需要更深度的价值挖掘,应对未来不断变化的需求。海量离线数据分析可以应用于多种商业系统环境,例如电商海量日志分析、用户行为画像分析、科研行业的海量离线计算分析任务等场景。
本场景将通过开通登录EMR Hadoop集群,简单进行hive操作,使用hive对数据进行加载,计算等操作。展示了如何构建弹性低成本的离线大数据分析。
体验此场景后,可以掌握的知识有:
1.EMR集群的基本操作,对EMR产品有初步的了解
2.EMR集群的数据传输和hive的简单操作,对如何进行离线大数据分析有初步的掌握
背景知识
E-MapReduce(简称“EMR”)是云原生开源大数据平台,向客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、Clickhouse、Delta、Hudi等开源大数据计算和存储引擎。EMR计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK、专有云平台。产品文档地址:https://www.aliyun.com/product/emapreduce
产品优势
开源生态:提供高性能、稳定版本Hadoop、Spark、Hive、Flink、Kafka、HBase、Presto、Impala、Hudi等开源大数据组件,客户可根据场景灵活搭配使用
引擎优化:多引擎性能优化,如Spark SQL较开源版本提升6倍。采用JindoFS+OSS,保证数据可靠性基础上,性能大幅提升
便捷运维:在阿里云控制台和OpenAPI方便地对集群、节点和服务进行监控和运维操作。助您大幅提升运维工作效率,让数据工程师更专注于业务开发
节约成本:集群资源可自动按需匹配,您只需要按实际使用量付费,减少资源浪费成本。支持阿里云抢占式实例、预留实例券(RI),进一步降低成本
弹性资源:可以灵活调整集群资源,在数分钟内创建出基于云服务器 ECS、容器 ACK的集群,快速响应业务需求
安全可靠:通过 VPC 和安全组设置集群网络安全策略,支持Kerberos身份认证和数据加密,使用Ranger数据访问控制。支持数据加密,保证数据安全
登陆集群
(尚未拥有阿里云集群 可以至体验实验室免费体验)
上传数据到HDFS
1.创建HDFS目录。
hdfs dfs -mkdir -p /data/student
2.上传文件到hadoop文件系统。
a. 使用以下命令下载示例数据文件到服务器内:
wget https://labfileapp.oss-cn-hangzhou.aliyuncs.com/%E5%85%AC%E5%85%B1%E6%96%87%E4%BB%B6/u.txt
b. 上传文件到hadoop文件系统。
hdfs dfs -put u.txt /data/student
3.查看文件
hdfs dfs -ls /data/student

使用hive创建表
1.登入hive数据库。
[root@emr-header-1 ~]# hive
Logging initialized using configuration in file:/etc/ecm/hive-conf-2.3.7-1.1.7/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
2.创建user表。
CREATE TABLE emrusers (
userid INT,
movieid INT,
rating INT,
unixtime STRING )
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
;

3. 从hadoop文件系统加载数据到hive数据表。
LOAD DATA INPATH '/data/student/u.txt' INTO TABLE emrusers;
对表进行操作
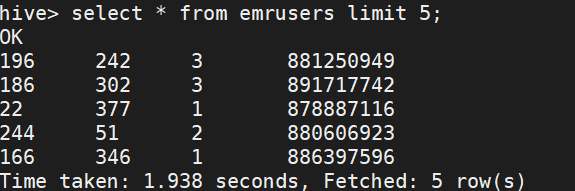
1.查看表数据。
select * from emrusers limit 5;
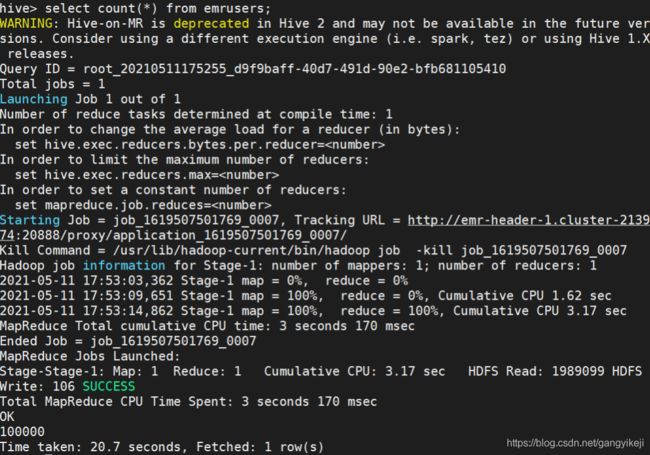
2.计算count。
select count(*) from emrusers;
3. 评级最高的三个电影。
select movieid,sum(rating) as rat from emrusers group by movieid order by rat desc limit 3;
