虚拟机配置Hadoop
目录
前言
一、配置网络信息
1.修改配置信息
2.重启网络服务(所有结果显示ok即成功)
3.配置映射(修改主机名:vi /etc/sysconfig/network)
二、SSH配置免密登录
1.创建密钥对
三、安装和配置jdk(xshell操作)
1.传输通道:sftp ip(本地直接拖拽安装包即可上传虚拟机)
2.修改全局配置文件
四、Hadoop安装和部署(单节点伪分布)
上传CDH压缩文件到CentOS
解压CDH压缩文件
修改配置文件
五、zookeeper(分布式协调服务)的安装与运行
上传压缩文件到CentOS
解压文件
创建zoo.cfg,在.../Zookeeper/conf下有zoo_sample.cfg文件,复制并重命名为zoo.cfg
六、YARN搭建
1.编辑mapred-site.xml
2.伪分布yarn的配置 yarn-site.xml
3.验证是否安装成功
七、配置Hive
安装mysql
安装hive
八、配置hbse
1.解压
2.编辑全局配置(vi /etc/profile)
3.使全局配置生效 source /etc/profile
4.修改hbase-env.sh
5.修改regionservers文件,
6.修改hbase-site.xml
7.拷贝zookeeper conf/zoo.cfg到hbase的conf/下
8.赋予脚本执行权力
9.启动Hbase 在bin目录下执行 :./start-hbase.sh
九、配置flume
十、配置sqoop
总结
前言
记录hadoop配置全过程以备不时之需
提示:以下是本篇文章正文内容,下面案例可供参考
一、配置网络信息
1.修改配置信息
vi /etc/sysconfig/network-scripts/ifcfg-eth0 //编辑文件内容如下,最后一行和倒数第三行的网段可以随便写,符合标准即可 DEVICE=eth0 TYPE=Ethernet ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static IPADDR=192.168.1.205 NATMASK=255.255.255.0 GATEWAY=192.168.1.562.重启网络服务(所有结果显示ok即成功)
service network restart3.配置映射(修改主机名:vi /etc/sysconfig/network)
目的:将IP地址和机器名相映射,这样主机和其他用户相互通信时,可以直接使用主机名,也可以使用ip地址
vi /etc/hosts //网络ip 主机名 192.168.1.56 master
二、SSH配置免密登录
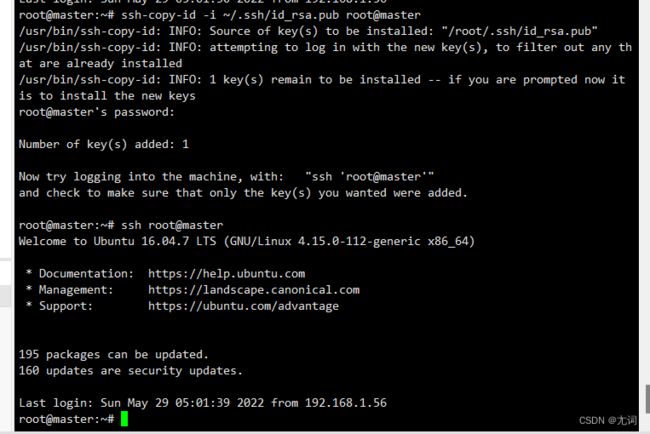
1.创建密钥对
ssh-keygen -t rsa -P ''
2.传递公钥
ssh-copy-id -i ~/.ssh/id_rsa.pub 用户名@主机名
ssh 主机名 这个命令用来检验是否配置成功(不需要输入密码则为成功)

三、安装和配置jdk(xshell操作)
1.传输通道:sftp ip(本地直接拖拽安装包即可上传虚拟机)
- 查看当前系统jdk
rpm -qa | grep jdk
- 删除系统jdk(root用户)
rpm -e --nodeps java...(jdk名称)
- 安装jdk
- 上传jdk到CenOS
sftp 192.168.56.2 cd进入到目标目录下拖进去
2.解压 tar -zxvf 压缩包目录
tar -zxvf 压缩包路径 -C 解压文件全路径
2.修改全局配置文件
在末尾添加jdk安装全路径和环境变量
使全局配置生效并验证是否成功


四、Hadoop安装和部署(单节点伪分布)
安装CDH
上传CDH压缩文件到CentOS
解压CDH压缩文件
修改配置文件
cd hadoop安装目录 cd etc/hadoop(注意etc前面不要加/会去到根目录下)
①修改hadoop-env.sh
hadoop: vi hadoop-env.sh
在文件末尾添加
export JAVA_HOME=jdk安装目录
export HADOOP_HOME=cdh安装目录
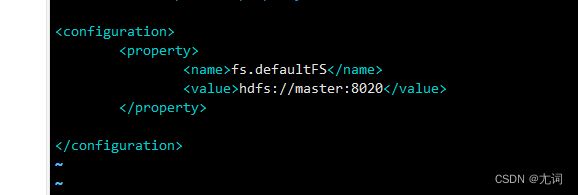
②修改core-site.xml
vi core-site.xml
添加:
fs.defaultFS
hdfs://master:8020
③修改hdfs-site.xml
vi hdfs-site.xml
dfs.replication
3
dfs.name.dir
/root/hdfs/name
dfs.data.dir
/root/hdfs/data
④修改slaves文件 vi slaves
添加: master
⑤追加HADOOP_HOME到/etc/profile中
vi /etc/profile
添加:
export HADOOP_HOME=路径
export PATH=$HADOOP_HOME/bin:$PATH
⑥使配置文件生效
source /etc/profile
hadoop 命令可以检测Hadoop环境
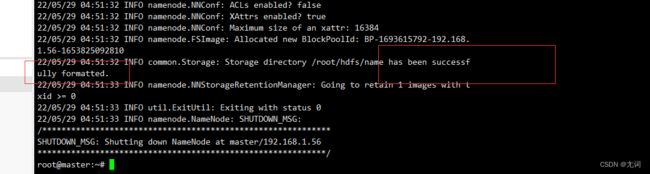
(4)格式化hdfs
执行
hadoop namenode -format (仅第一次执行,不要重复执行)
有如上图字眼即为成功
启动Hadoop并验证安装
进入sbin目录 执行 ./start-dfs.sh
(5)检验是否启动成功
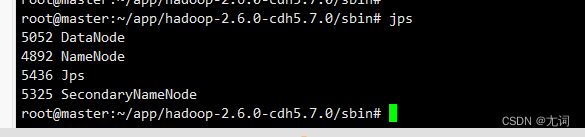
①通过进程查看 jps
出现:I. 8817 DataNode
II. 9013 SecondaryNameNodes
III.9119 jps
IV. 8714 NameNode
②通过浏览器查看
http://IP地址:50070
http://master:50070
(6)停止hadoop
进入sbin目录 ./stop-dfs.sh




五、zookeeper(分布式协调服务)的安装与运行
上传压缩文件到CentOS
解压文件
创建zoo.cfg,在.../Zookeeper/conf下有zoo_sample.cfg文件,复制并重命名为zoo.cfg
修改dataDir路径 vi zoo.cfg
dataDir 默认是 /tmp/zookeeper,由于 /tmp 是 Ubuntu 的 临时目录,这个路径下的数据不能长久保存,因此需要指定到别的已存在的目录。
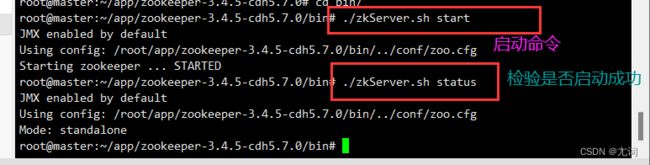
./zkServer.sh stop:停止服务


六、YARN搭建
yarn的配置文件在hadoop目录下的etc/hadoop下
1.编辑mapred-site.xml
cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml
mapreduce.framework.name yarn
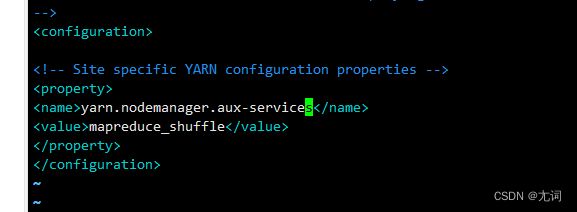
2.伪分布yarn的配置 yarn-site.xml
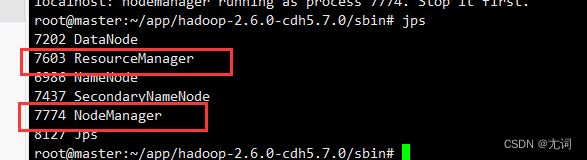
yarn.nodemanager.aux-services mapreduce_shuffle 3.验证是否安装成功
两个都启动共有六个进程则成功




七、配置Hive
本地模式需要MySQL作为hive的存储数据库,所以安装hive之前需要先安装MySQL
安装mysql
将附件上传
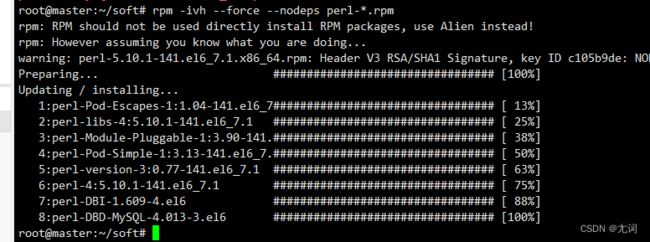
- rpm -ivh --force --nodeps perl-*.rpm 强制安装忽略依赖,以perl开头的(上传到哪就在哪个路径下执行。如果报rpm: command not found,先安装rpm apt install linuxbrew-wrapper)
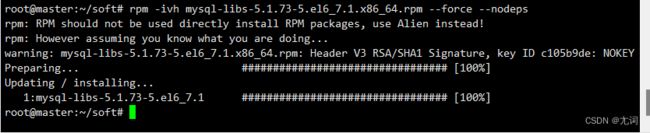
- rpm -ivh mysql-libs-5.1.73-5.el6_7.1.x86_64.rpm 升级mysql库(如果报错,则在末尾加上--force --nodeps)
- rpm -ivh --force --nodeps mysql-5.1.73-5.el6_7.1.x86_64.rpm mysql-server-5.1.73-5.el6_7.1.x86_64.rpm
1. 启动mysql服务: service mysqld start
2. 登录到mysql : 默认mysql是没有密码的 mysql -u root
3. 完成mysql的基本设置:
use mysql - 使用mysql子库
select user,password,host from user; - 查询mysql的权限信息表
delete from user where host!=’127.0.0.1’; - 删除不需要的用户信息
update user set password=password(‘123456’) where user=’root‘’; - 修改mysql的密码
update user set host=’%’ where user=’root’; - 开启远端访问mysql的权限
flush privileges; - 刷新mysql的权限
安装hive
- 在mysql下创建hive数据库
create database hive;
- 设置hive登录权限
grant all on hive.* to root@master identified by ‘你的密码’;
- 刷新权限
flush privileges;
- exit; 退出
(ctrl+c退出)
- 上传hive的压缩包,并解压
tar -zxvf 压缩包路径 -C ~/app
- 上传hive-site.xml 到hive目录下的conf目录下
- 修改hive-env.sh配置文件
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
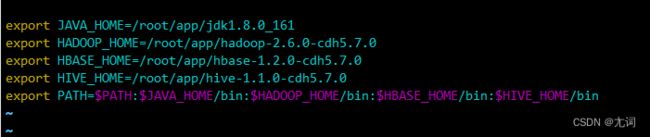
export JAVA_HOME=jdk的安装目录
export HADOOP_HOME=hadoop的安装目录
- 上传mysql的驱动jar包 至 hive的安装目录下的lib目录下
- 修改配置文件 (全局变量)vi /etc/profile
export HIVE_HOME=hive的安装目录
export PATH=$HIVE_HOME/bin:$PATH
- 刷新配置 生效
source /etc/profile
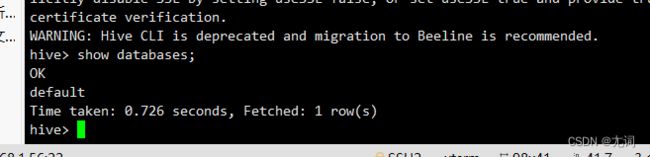
- 在hadoop mysql启动的情况下,进入hive
hive
(关闭安全模式hadoop dfsadmin -safemode leave)


八、配置hbse
1.解压
2.编辑全局配置(vi /etc/profile)
3.使全局配置生效 source /etc/profile
4.修改hbase-env.sh
在配置中找到如下代码,记得将‘#’删掉
5.修改regionservers文件,
添加master
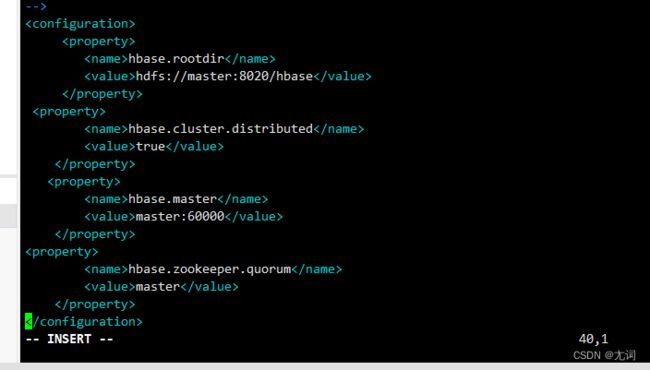
6.修改hbase-site.xml
hbase.rootdir hdfs://master:8020/hbase hbase.cluster.distributed true hbase.master master:60000 hbase.zookeeper.quorum master
7.拷贝zookeeper conf/zoo.cfg到hbase的conf/下
8.赋予脚本执行权力
chmod +x ~/app/hbase-1.2.0-cdh5.7.0/bin/start-hbase.sh
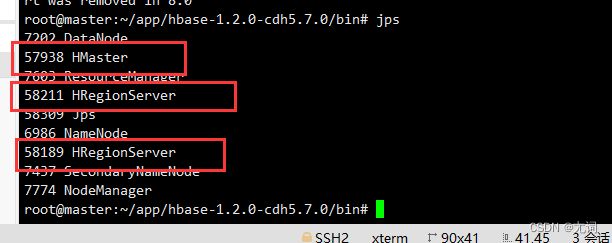
9.启动Hbase 在bin目录下执行 :./start-hbase.sh
使用hbase shell 命令进入hbase



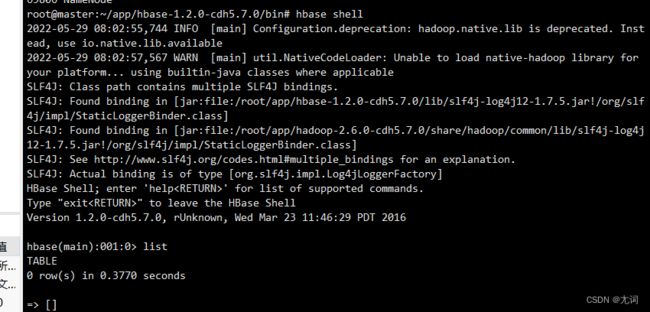
九、配置flume
1.修改配置文件 vi flume-env.sh
2.验证flume的安装
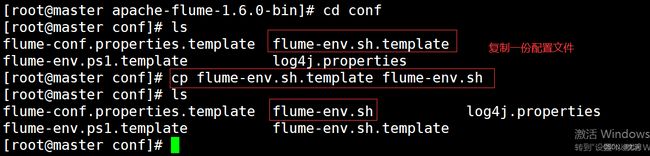
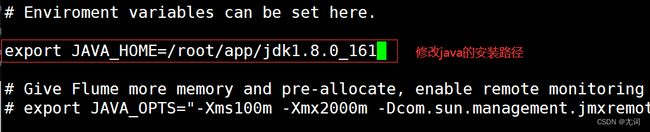
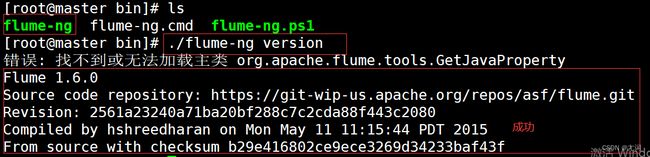
十、配置sqoop
1.解压sqoop压缩包到指定路径
2.复制conf下的sqoop-env-template.sh改名为sqoop-env.sh并做如下修改

在全局变量中添加sqoop(vi /etc/profile)并生效(source /etc/profile)
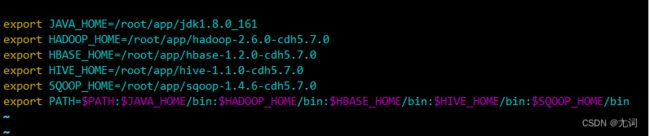
将mysql驱动包拷贝到sqoop的lib包下
sqoop version验证sqoop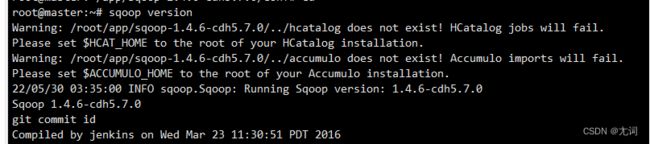
附件
到这里就配置结束啦!附上相关资料:链接: https://pan.baidu.com/s/1z2-1qmdCE0JyyrK-2_pj_Q?pwd=sve7 提取码: sve7 复制这段内容后打开百度网盘手机App,操作更方便哦