hadoop集群在vm虚拟机Linux系统下的搭建单、伪、全分布式搭建参考
首先在vm上安装一台Linux系统虚拟机,安装方法可以在网上查找
下面是安装好虚拟机之后的操作
可以下载一个finallshell工具,操作更方便
链接:https://pan.baidu.com/s/1dAdk7qvX4uEN2KLWZ5VHQw
提取码:9527
JDK1.8下载
链接:https://pan.baidu.com/s/1ElO1vHFRb6HR5ijRj2j_og
提取码:9527
先在虚拟机系统上如下操作:
查看自己的IP
登录虚拟机
修改静态IP
首先找到/etc/sysconfig/network-scripts/下的ifcfg-ens33配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
![]()
把 BOOTPROTO = “dhcp” 改成 BOOTPROTO = “static” 表示静态获取,然后把 UUID 注释掉,把 ONBOOT 改为 yes,表示开机自动静态获取,然后在最后追加比如下面的配置:
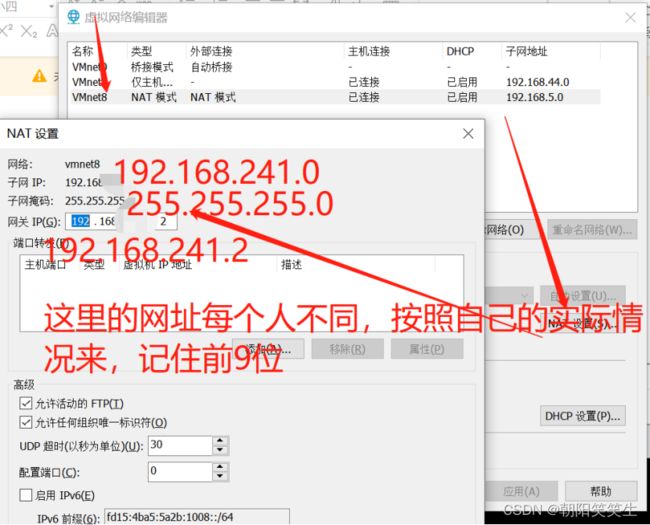
IPADDR=192.168.241.161 #自己的ip地址,前9位和自己前面查看的相同,后三位可以150左右的值,我写了161,至于为什么可以网上查找
NETMASK=255.255.255.0
GATEWAY=192.168.241.2
DNS1=114.114.114.114
DNS2=8.8.8.8

IPADDR就是静态IP,NETMASK是子网掩码,GATEWAY就是网关或者路由地址
重启网络服务
centos6的网卡重启方法:service network restart
centos7的网卡重启方法:systemctl restart network
然后用自己设置的IPADDR=192.168.241.161 #自己的ip地址
连接finallshell
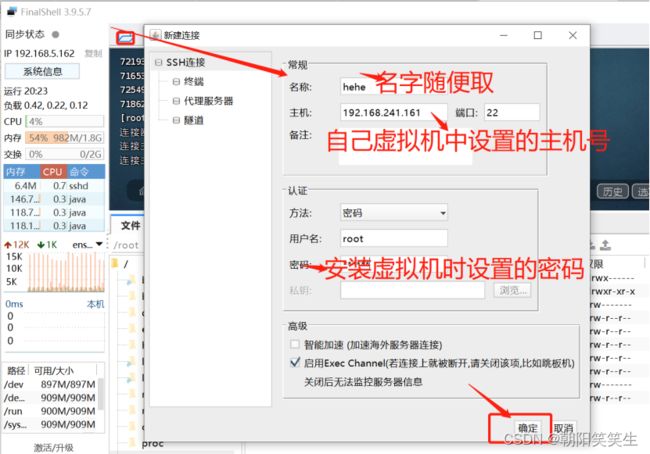
修改主机名 vi /etc/hostname


断开连接 shutdown -r

重新连接
检查是否有jdk
rpm -qa | grep jdk
rpm -qa | grep java
进入opt文件夹创建software和apps文件夹用来存储软件包和解压包
cd /opt/
mkdir software
mkdir apps
将安装包放入software文件夹中
然后进入software
cd software
执行解压命令解压到apps文件夹
tar -zxvf jdk-8u333-linux-x64.tar.gz -C /opt/apps/

解压完成进入apps文件夹
cd ..
cd apps/
改名为jdk
mv jdk1.8.0_333 jdk

配置环境变量
vi /etc/profile

按i 编辑
export JAVA_HOME=/opt/apps/jdk
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib
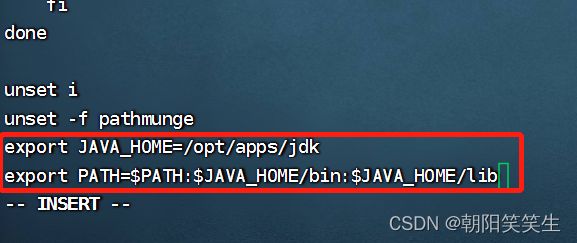
按esc键退出编辑模式
按:wq 按回车保存退出
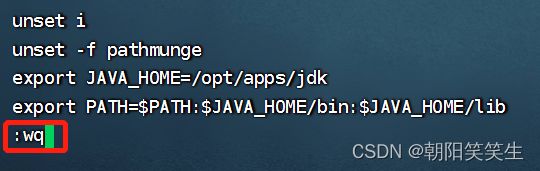
生效配置文件
source /etc/profile
检查配置文件
java -version
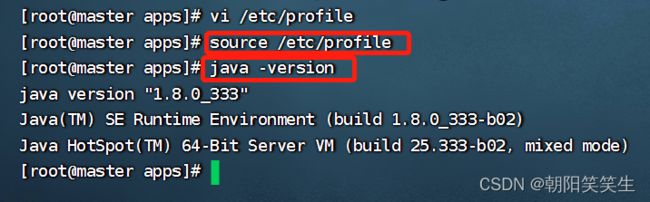
显示Java版本证明配置成功
也可以用执行java_home 方式验证
echo $JAVA_HOME
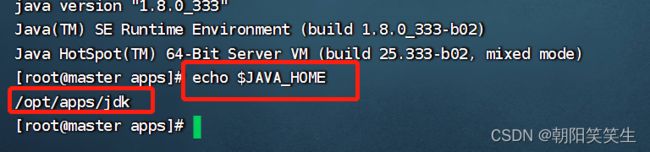
安装hadoop
安装包放到software文件夹中
进入software文件夹

将安装包安装到apps文件夹下面
tar -zxvf hadoop-2.7.6.tar.gz -C /opt/apps/

安装完成后,进入apps文件夹中,改名为hadoop
cd ..
cd apps/
mv hadoop-2.7.6 hadoop

配置环境变量
vi /etc/profile

export HADOOP_HOME=/opt/apps/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

保存退出
生效配置文件
source /etc/profile
检查配置情况
hadoop version
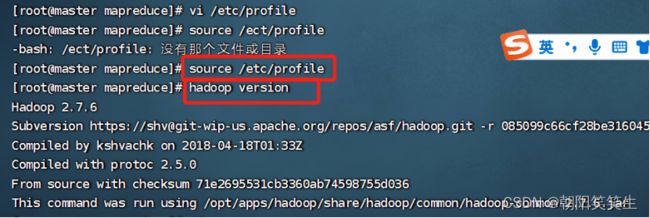
显示hadoop版本,单节点版配置成功
接下来
伪分布式搭建
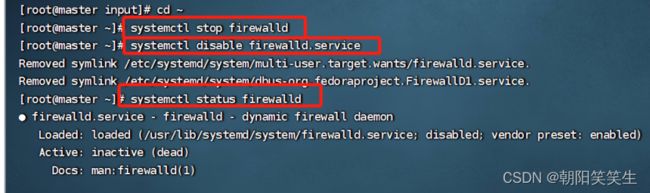
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld.service
systemctl status firewalld
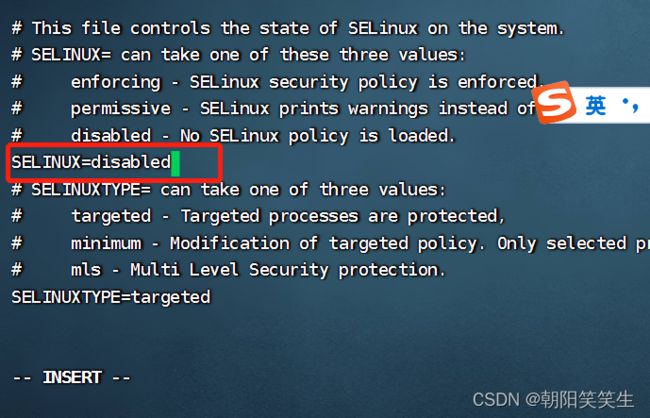
vi /etc/selinux/config

配置镜像文件

免密登录认证
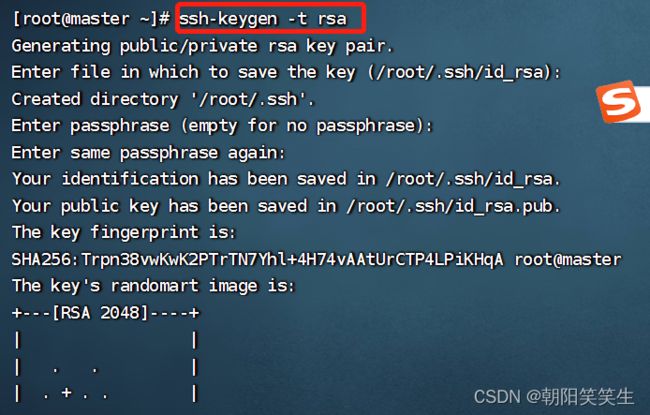
生成公钥私钥
ssh-keygen -t rsa
对localhost免密操作
第一次需要输入登录密码
ssh-copy-id root@localhost

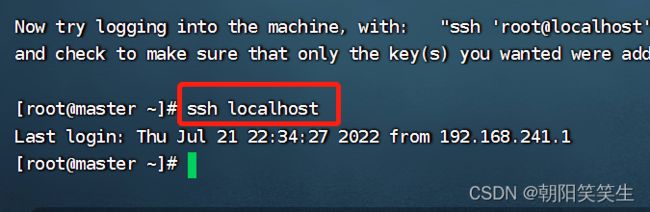
检查免密是否成功
ssh localhost
直接登录证明已成功
退出exit
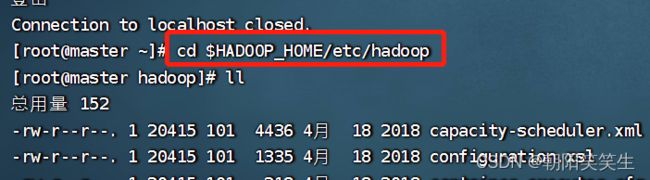
伪分布式文件配置
cd $HADOOP_HOME/etc/hadoop
首先
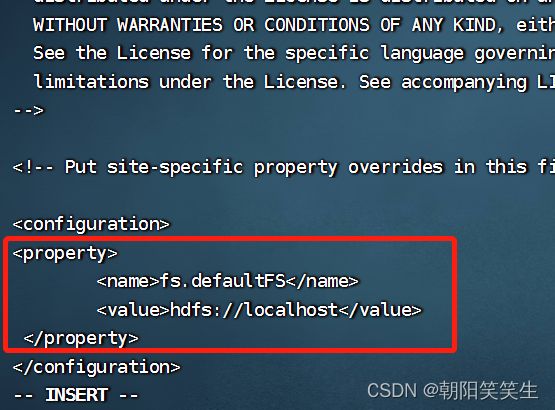
vi core-site.xml
写入配置信息
进入
vi hdfs-site.xml 进行配置

伪分布式配置副本数是1
接下来环境搭建
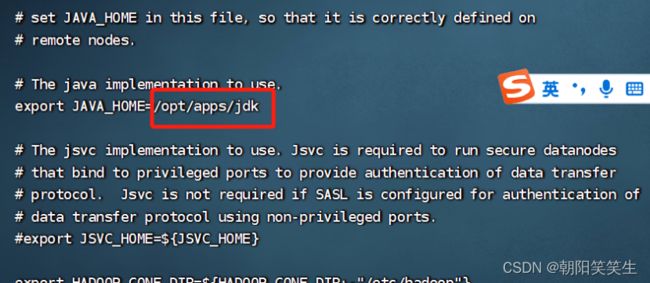
vi hadoop-env.sh
export JAVA_HOME=/opt/apps/jdk jdk的路径
集群格式化及启动
格式化 hadoop sbin 文件夹下
hdfs namenode -format

节点启动
start-dfs.sh

查看是否启动成功
jps
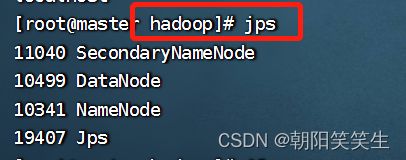
了解部分:
文件默认存储位置

more slaves 所有的奴隶
存放所有的datanode 的ip
伪分布式测试案例
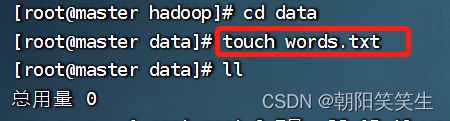
创建hadoop下data文件夹 words.txt文件 并写入内容
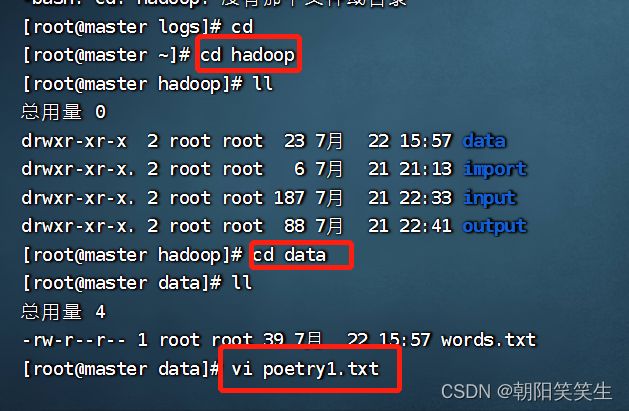
cd hadoop
![]()
mkdir data
cd data

touch words.txt
vi words.txt

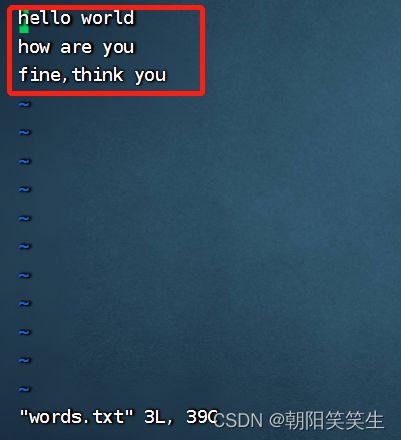
写入下面单词保存退出用于测试
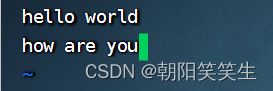
hello world
how are you
fine,think you
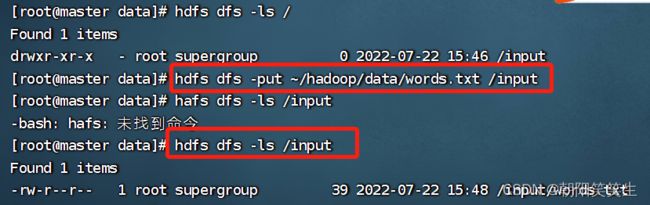
创建input文件夹
hdfs dfs -mkdir /input
![]()
查看input文件夹是否创建成功
hdfs dfs -ls /
将words.txt导入input文件夹
hdfs dfs -put ~/hadoop/data/words.txt /input
也可以用
hdfs dfs -put /root/hadoop/data/words.txt /input
~与/root作用相同 代表当前用户的家目录
检查是否导入成功
hdfs dfs -ls /input
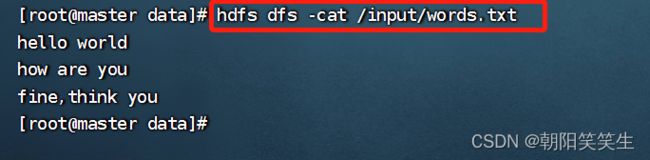
查看文件内容
hdfs dfs -cat /input/words.txt
Hadoop官网文档 可以查看相关命令操作介绍
Apache Hadoop 2.7.6 –
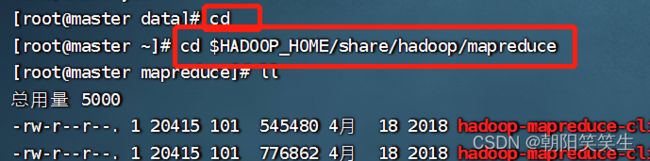
执行测试
cd $HADOOP_HOME/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /input/ /output1
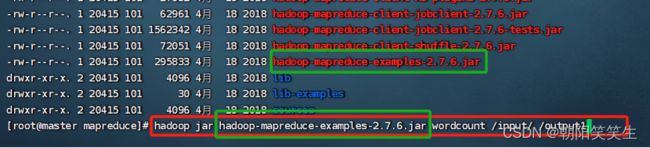
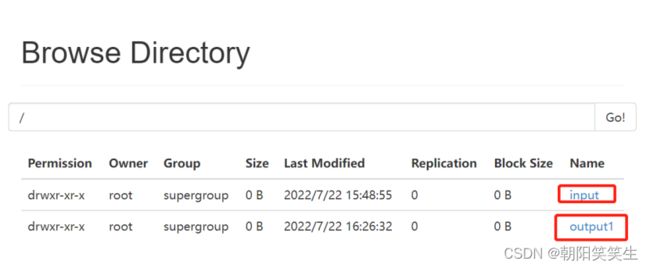
查看output1文件是否被创建
hdfs dfs -ls /
打开output1文件
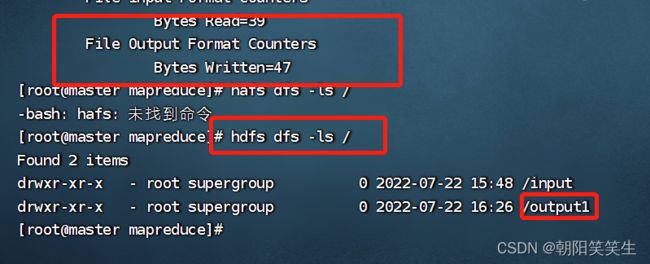
hdfs dfs -ls /output1

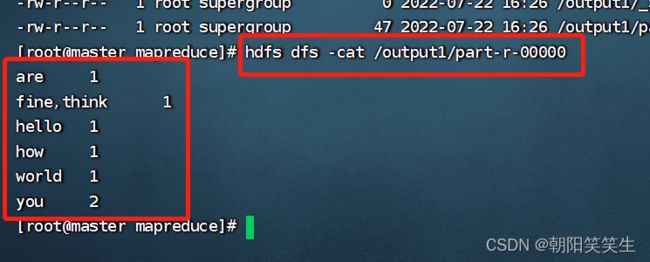
查看part-r-00000文件
hdfs dfs -cat /output1/part-r-00000
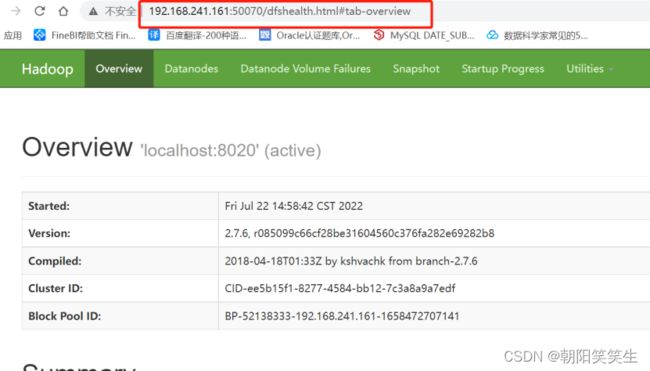
打开浏览器看后台存储
192.168.241.161:50070
ip地址 端口号
http://192.168.241.161:50070/dfshealth.html#tab-overview
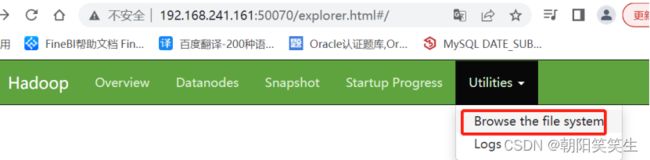


伪分布式搭建完成
接下来
在此基础上搭建全分布式
检查防火墙是否关闭
systemctl status firewalld
查看IP是否已设置


IPADDR=192.168.241.161
NETMASK=255.255.255.0
GATEWAY=192.168.241.2
DNS1=114.114.114.114
DNS2=8.8.8.8
配置映射
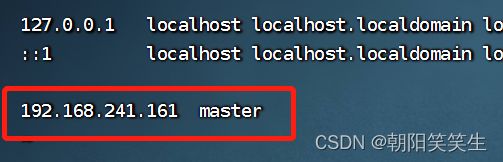
vi /etc/hosts

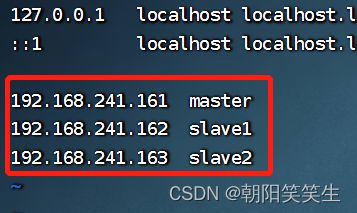
192.168.241.161 master
192.168.241.162 slave1
192.168.241.163 slave2
查看jdk是否安装配置
java -version

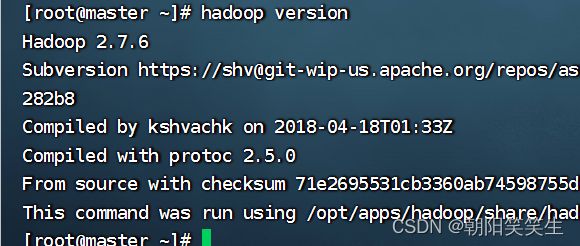
查看hadoop是否安装配置
hadoop version
配置core-site.xml文件
cd $HADOOP_HOME/
cd etc/hadoop

vi core-site.xml

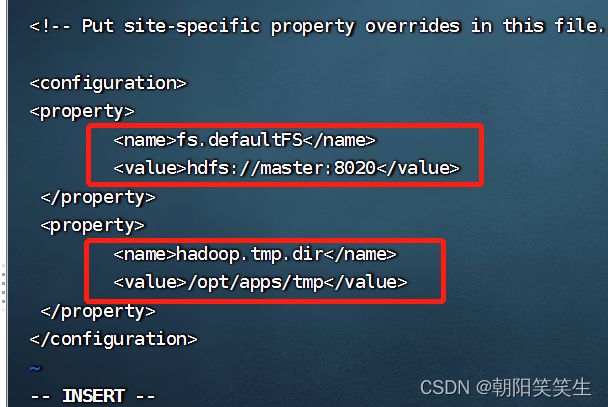
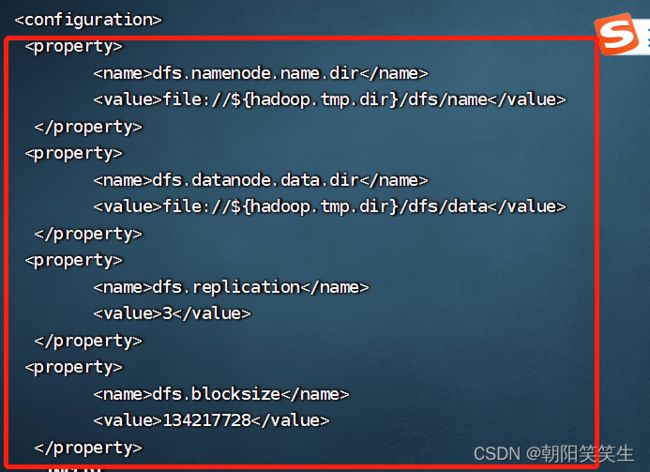
配置 hdfs-site.xml文件
vi hdfs-site.xml

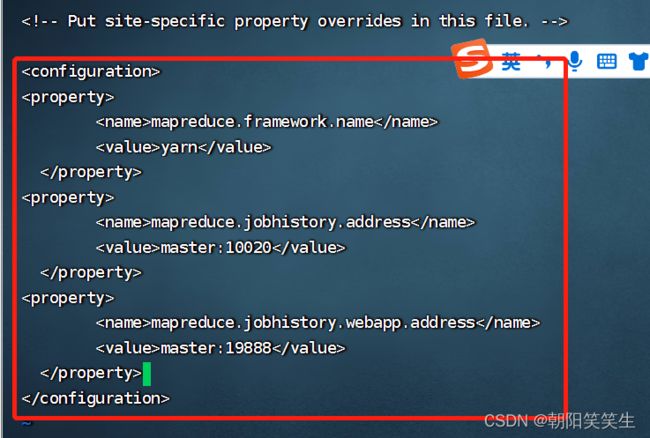
配置mapred-site.xml文件
复制新建mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml

vi mapred-site.xml

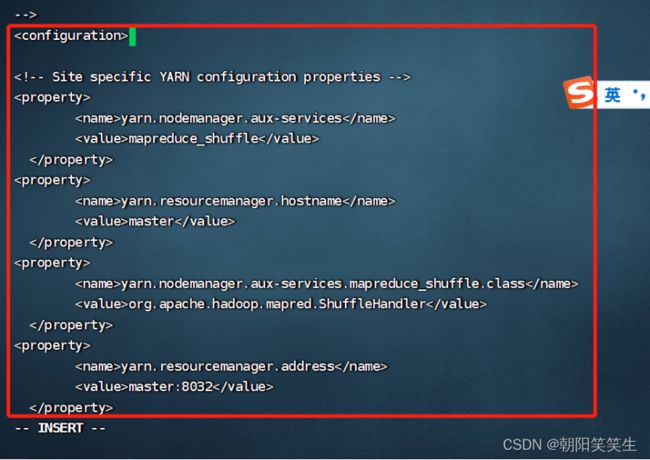
配置yarn-site.xml文件
vi yarn-site.xml
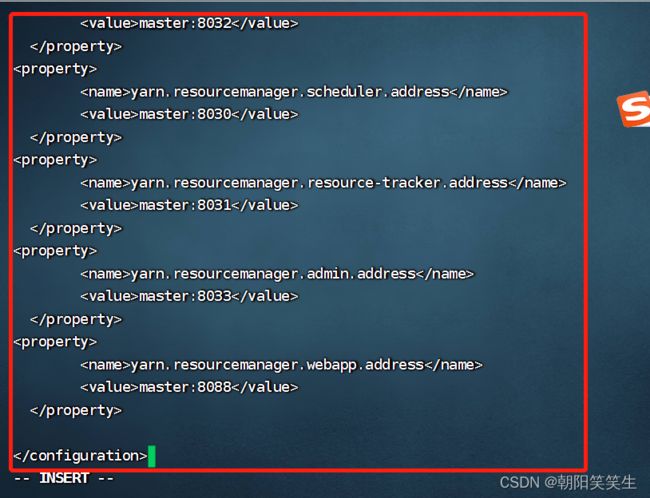
配置hadoop-env.sh文件
vi hadoop-env.sh

export JAVA_HOME=/opt/apps/jdk
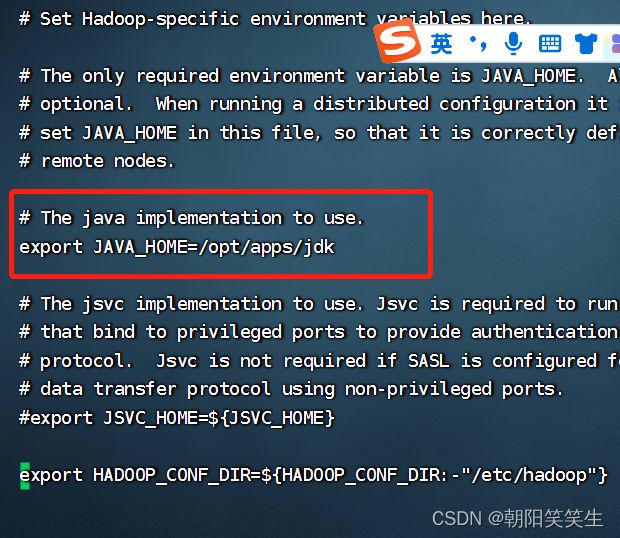
配置yarn-env.sh 环境文件
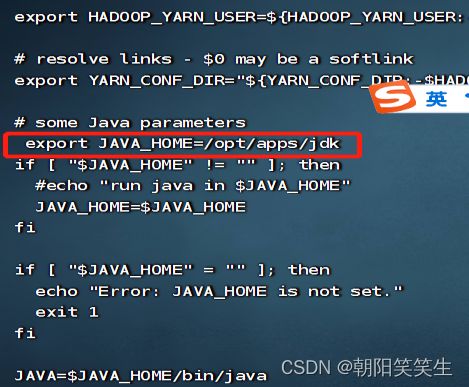
vi yarn-env.sh

export JAVA_HOME=/opt/apps/jdk
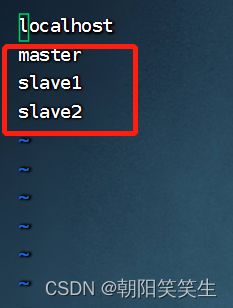
配置slaves文件
vi slaves

master
slave1
slave2
将localhost删掉。我忘记删了
重启机器
shutdown -r now

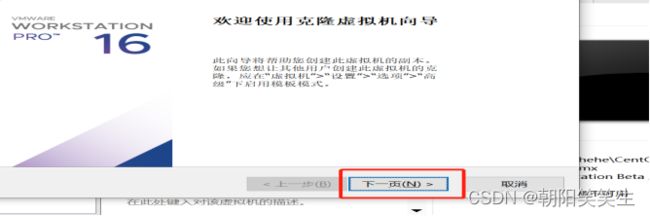
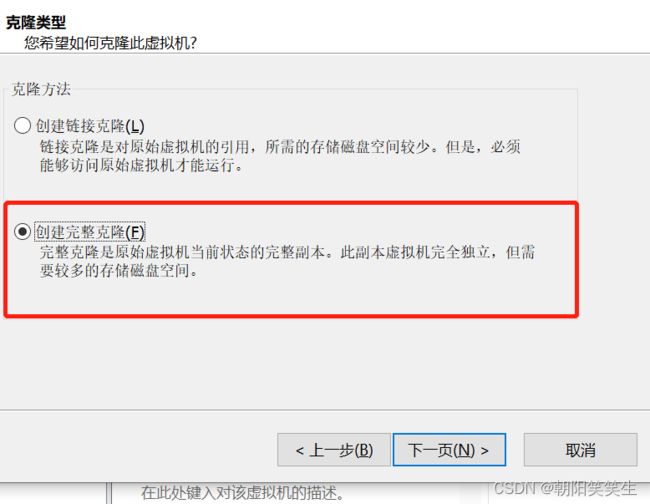
配置完成开始克隆
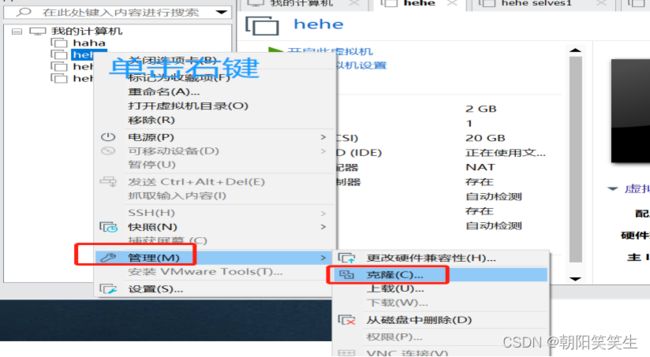
刚配置好的虚拟机名单击右键>管理>克隆
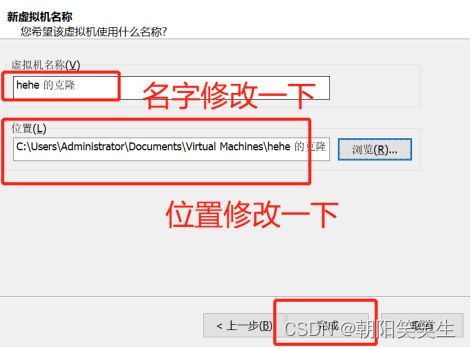
克隆成功后记得下面操作,每台克隆机都要操作,地址不要相同,我的三台是
161、162、163
修改静态IP
首先找到/etc/sysconfig/network-scripts/下的ifcfg-ens33配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33

每台克隆的虚拟机都更改好IPaddr后,可以连接到finalshell上方便操作
修改主机名 vi /etc/hostname
![]()
将默认的localhost改为slave1,另一台改为slave2
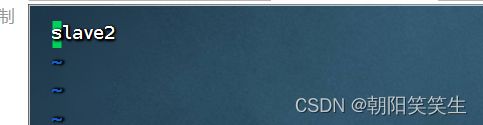
Master上设置免密登录

设置slave1免密登录
ssh-copy-id root@slave1
并验证
ssh slave1
同样完成slave2
ssh-copy-id root@slave2
ssh slave2

接下来设置时间同步
下载安装ntp 和ntpdate服务器
yum -y install ntp ntpdate

三台机器都要安装上
配置/etc/ntp.conf文件
vi /etc/ntp.conf
![]()
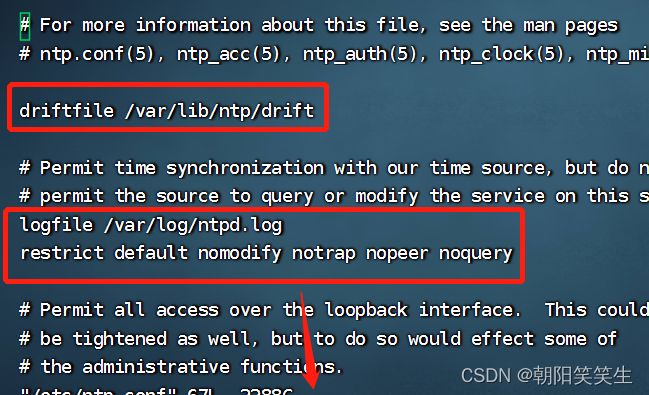
后面的直接复制进去替换原文件就可以了
driftfile /var/lib/ntp/drift
logfile /var/log/ntpd.log
restrict default nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict ::1
restrict 192.168.241.0 mask 255.255.255.0 nomodify notrap
server 0.asia.pool.ntp.org iburst
server 1.asia.pool.ntp.org iburst
server 2.asia.pool.ntp.org iburst
server 3.asia.pool.ntp.org iburst
server 127.127.1.0 iburst
fudge 127.127.1.0 stratum 10
restrict 0.asia.pool.ntp.org nomodify notrap noquery
restrict 1.asia.pool.ntp.org nomodify notrap noquery
restrict 2.asia.pool.ntp.org nomodify notrap noquery
restrict 3.asia.pool.ntp.org nomodify notrap noquery
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys
disable monitor
接下来ntp服务器初始化
systemctl enable ntpd
systemctl enable ntpdate
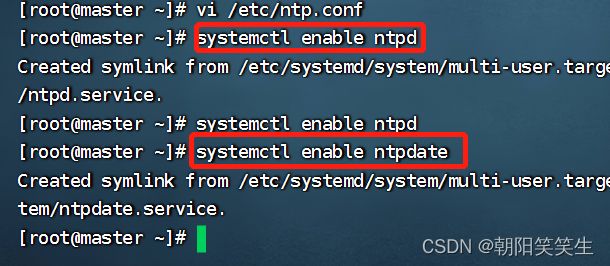
检查是否启动
systemctl is-enabled ntpdate
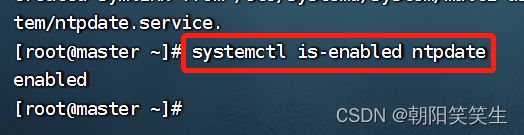
启动ntp 并检查对应进程
systemctl start ntpd
ps -ef | grep ntpd
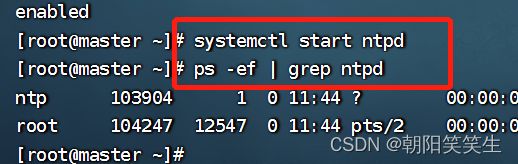
查看ntp的情况
ntpq -p

执行同步并测试
hwclock -w
ntpstat
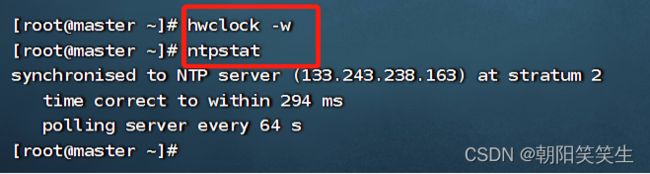
接下来去salve1配置客户端服务器
设置定时器
crontab -e

10 23 * * * (/usr/sbin/ntpdate -u 192.168.241.161 && /sbin/hwclock -w) &> /var/log/ntpdate.log

ntpdate进行初始化
systemctl enable ntpdate

执行格式化
hdfs namenode -format

启动集群
start-dfs.sh
启动失败可以尝试下面操作后再启动
vi /etc/ssh/ssh_config #在最后面添加如下语句即可 StrictHostKeyChecking no UserKnownHostsFile /dev/null
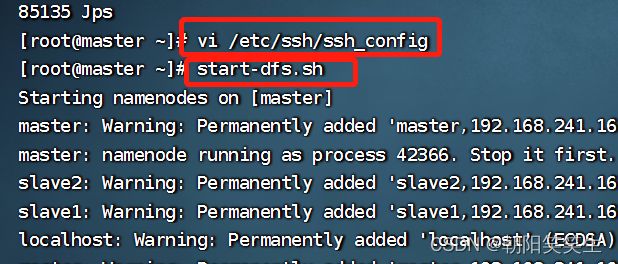
jps查看情况
启动yarn
start-yarn.sh
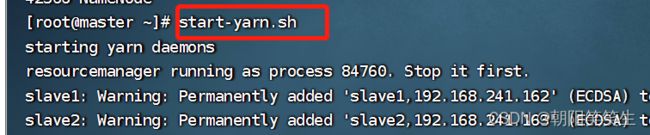
查看日志文件
cd /opt/apps/hadoop/logs


more hadoop-root-datanode-master.log

浏览器打开http://192.168.241.161:50070/

案例测试
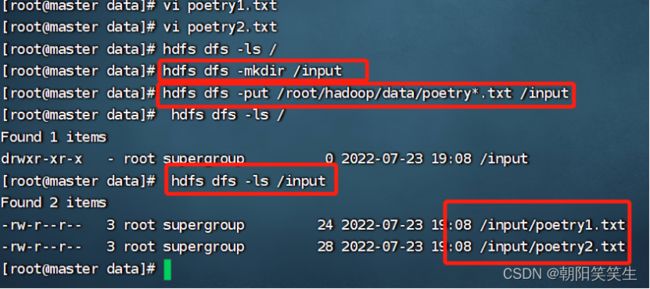
hadoop/data文件夹中创建测试文件vi poetry1.txt
hello world
how are you
再创建第二个文件
vi poetry2.txt

fine,thank you
ok, good bye

创建文件夹 input
hdfs dfs -mkdir /input
上传到分布式文件系统 input中
hdfs dfs -put /root/hadoop/data/poetry*.txt /input
查看是否上传成功
hdfs dfs -ls /input
执行程序自带应用
进入应用文件夹
cd $HADOOP_HOME/share/hadoop/mapreduce
执行应用程序
hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output1
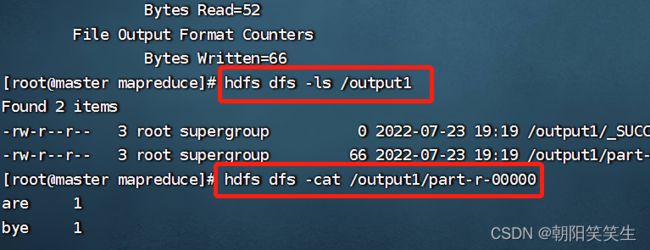
执行成功查看执行结果
hdfs dfs -ls /output1
hdfs dfs -cat /output1/part-r-00000
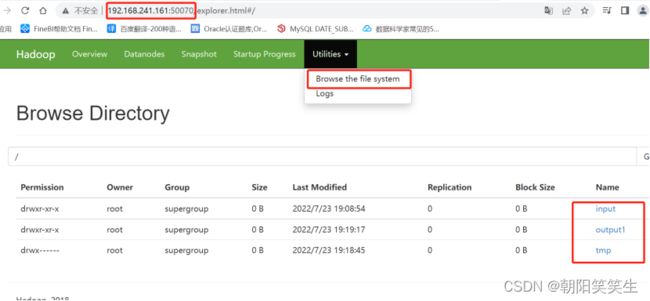
网页查看效果
stop-dfs.sh
stop-yarn.sh
注意事项
每次运行结束 Hadoop 后,都要执行 stop-all.sh 关掉Hadoop所有服务。下次想重新运行 Hadoop,不用再格式化 NameNode ,直接启动 Hadoop 即可
到这里基本OK了,干了几天的结果,希望对各位有所帮助,呀买碟、奥利给