智源青年科学家梁云:异构系统中张量计算的自动调度和优化框架

与6位图灵奖得主和100多位专家
共同探讨人工智能的下一个十年
长按图片,内行盛会,首次免费注册
北京智源大会倒计时:9天
计算机体系结构领域国际顶级会议每次往往仅录用几十篇论文,录用率在20%左右,难度极大。国内学者在顶会上开始发表论文,是最近十几年的事情。
ASPLOS与HPCA是计算机体系结构领域的旗舰会议。其中ASPLOS综合了体系结构、编程语言、编译、操作系统等多个方向,HPCA则主要针对高性能体系结构设计。过去的三十多年里,它们推动了多项计算机系统技术的发展,RISC、RAID、大规模多处理器、Cluster架构网络存储、机器学习加速器等诸多计算机体系结构领域的重大技术突破,都最早发表在这两个会议之上。
2020年4月12日上午,北京智源人工智能研究院和北京大学高能效计算与应用中心联合主办了“AI芯片体系架构和软件专题报告会”,五位学者结合在2020年计算机体系结构顶级会议(ASPLOS和HPCA)中发表的最新研究成果,针对AI芯片和体系结构领域的几个关键挑战:芯片加速、能耗和反对抗攻击等,详细介绍了他们的最新思考和解决方案。超过1900名观众在线观摩了学者们的报告。报告主题分别是:
本次报告会主席、智源青年科学家和北京大学研究员梁云《FlexTensor: An Automatic Schedule Exploration and Optimization Framework for Tensor Computation on Heterogeneous System》
美国南加州大学PhD Candidate骆沁毅《Prague: High-Performance Heterogeneity-Aware Asynchronous Decentralized Training》
清华大学交叉信息研究院助理教授高鸣宇《Interstellar: Using Halide's Scheduling Language to Analyze DNN Accelerators》
智源青年科学家、中国科学院计算技术研究所副研究员陈晓明《Communication Lower Bound in Convolution Accelerators》
中国科学院信息工程研究所研究员和信息安全国家重点实验室副主任侯锐《DNN Guard: An Elastic Heterogeneous Architecture for DNN Accelerator against Adversarial Attacks》
本篇是此次活动演讲内容的第三篇文章,今天我们将介绍北京大学高能效计算与应用中心长聘副教授、智源青年科学家梁云的主题报告《FlexTensor: An Automatic Schedule Exploration and Optimization Framework for Tensor Computation on Heterogeneous System》(异构系统中张量计算的自动调度和优化框架)。

梁云,主要研究领域为计算机体系结构、编译优化、芯片设计自动化。在 MICRO、HPCA、PPoPP、DAC 等顶级会议发表论文 90 多篇,谷歌学术引用超过 2500 次。根据 CSrankings 的统计,共发表 24 篇顶级会议论文,8 次被评选或提名为国际会议最佳论文,包括 ICCAD 2017 和 FCCM 2011 最佳论文、DAC 2017、2012 和 PPoPP 2019 的最佳论文提名。
在本次报告中,梁云详细介绍了他们团队发表的ASPLOS 2020上的最新成果——FlexTensor, 这是一个适用于异构系统的张量计算的调度探索和优化框架,它可以自动的对张量计算进行优化,使得程序员只需编写高级的张量程序,而不用考虑硬件平台的优化细节。本次报告中,梁云层层解析了实现FlexTensor框架的关键路径,如优化空间定义、用模拟退火算法结合机器学习等,抽丝剥茧地向大家呈现出该框架的奥妙之处。
整理:智源社区 张鼎盛、happylion
一、背景介绍
随着人工智能和专用硬件的普及,深度学习网络也在不断涌现,深度学习中使用的都是张量运算,为了让硬件能够支持人工智能应用并更好的发挥芯片的性能,每个硬件芯片都会提供高层的库来做张量运算,比如Intel的MKL、Nvidia的CuDNN等。

图1:不同硬件提供的算子库
目前手动开发库的流程如图2所示。程序员会手动描述算法,优化工程师手动优化并生成不同平台的代码,任何一个环节如果做出修改的话,其它的流程也都需要做出调整,整个设计过程当中需要手动探索不同的优化策略和不同的设计方案,所以这是一个非常耗时的过程。

图2:手动开发库流程
最近几年,学术界、工业界开始关注一个热点领域——自动代码生成(Automatic Code Generation),这个过程当中主要有两步:一步就是计算(Compute),一步就是调度(Schedule)。计算就是用一个上层的算法Tensor描述语言进行描述,并不涉及到任何一个底层硬件的细节。
下图举了一个计算的例子就是针对向量相加(Vector Add),两个向量相加,长度大小是16,通过一个Lambda表达式表达这样的加法。在上层会手写这样一个计算的描述,接下来会在上面做一些调度的优化,优化当中会包括各种各样的Primitive。

图3:向量相加
自动代码生成的代表工作
目前自动代码生成领域比较有代表性的是两份工作:一份是Halide,由麻省理工学院的 Jonothan教授提出,在学术界和产业界有非常大的影响力;另一份是TVM,由华盛顿大学Tianqi Chen提出,也在学术界和产业界产生了很大的影响力。
Halide最早提出将计算和调度分离,但是专注于图像处理领域,虽然针对CPU可以生成非常高性能的代码,但是针对新兴人工智能硬件来说,生成的代码性能相对差一些。

图4:Halide 特性
TVM,则沿用了Halide的计算和调度分离的技术,也可以针对不同硬件生成底层代码,例如CPU、GPU和嵌入式代码,专注于机器学习领域。TVM提供了一个叫做Auto TVM的自动化工具,它需要程序员手动输出模板(Template),然后可以帮助程序员自动探索这些参数,进行自动调整。

图5:TVM 特性
自动代码生成的难点
但手动优化书写模板有很大的挑战性,如图6列举了两点:
1. Primitive选择非常多,如果没有一个很好的排序搜索,并不知道应该选择哪些。
2. Primitive的组合和参数的空间构成了一个非常庞大的整个的搜索空间,可能是几亿个甚至几十亿个。

图6:手写模板的挑战
接下来如图7所示,列举了手写调度(Schedule)的困难,左图对比了三种输入大小不同的卷积,然后也对比了三种不同的Schedule A、B、C,区别就是 Primitive 的组合是不一样的,右下角对比的是同一个Primitive的组合,但是改变不同的参数,这里改变的是切分因子(Split Factor),所呈现出来的趋势也有很大的不同。可以从图中看出手写调度是很困难的,因为取决于输入的规模、Primitive的组合、不同的参数,并且不同的硬件都会带来不同的性能。

图7:手写调度的挑战
二、FlexTensor 架构的设计思想和工作流程
鉴于目前为止,设计流程的优化过程是半自动化的,面临着手写模板等挑战性问题,所以梁云团队希望能实现一个完全自动化的优化过程解决方案:它可以提供高性能,并且可以迁移到不同的硬件,程序员并不需要去写底层代码,整个开发周期也非常短。为了实现这个目标,梁云团队提出了FlexTensor 的架构,使得优化(Optimization)步骤变成一个全自动的流程,不需要任何程序员介入,程序员只需要写一个上层算法,整个算子库的产生过程就可以交给算法工程师完成。

图8:FlexTensor的设计理念
FlexTensor 的架构流程如图9所示,优化步骤实现全自动。首先输入的是计算语句,然后经过静态分析生成结构化的信息和统计学的信息,基于这两种信息会生成一个优化空间进行探索和评估,最后生成源码。下面,我们依次介绍FlexTensor 工作流程的几个关键步骤。

图9:FlexTensor的架构流程
①静态分析
这里使用简单的卷积乘法例子来介绍如何使用静态分析描述。如下图的三重卷积,使用静态分析后会生成一个MiniGraph,计算的过程可分成多步完成。静态分析产生的两种信息,一种是统计学信息包括循环次数和节点等等,另一种是结构信息包括计算图结构等等。

图10:卷积的静态分析
②调度空间生成
静态分析之后就会生成调度空间,如图11所示统计出来的三重循环次数可以限制切分引子,还加入了剪枝操作限定 Primitive 的组合深度,也可以对优化的空间做剪枝操作,针对特定硬件可以预先决定出来一些优化的选项。

图11:生成调度空间
③调度空间重组
接下来要对调度空间进行重组,如图12所示,将线性组合的不同点随机放到一个列表当中,但是不同的点之间实际上是有关联性的。
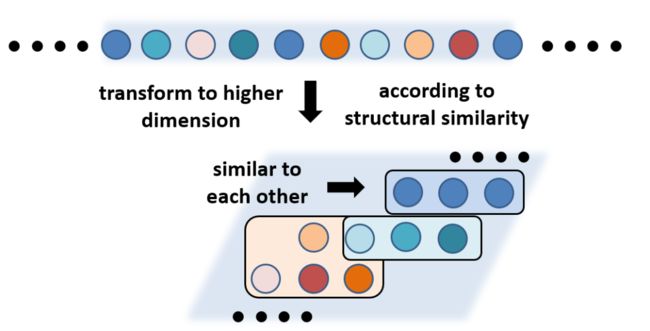
图12:随机点
通过把这些点组成一个高维的空间,相似的点聚合在一起,这样的话就可以更有助于搜索。如图13所示,例如在杂乱无章的列表当中,从最开始的点到最优的点,要经过八步搜索,但是当重组以后可能从第一步到最优的点只需要两步搜索,这就是优化空间重组的目的。

图13:重组优化
④高效探索
高效探索分两步,启发式搜索(Heuristics)和机器学习。目的是找到开始的点,评估这个点是好是坏和应该朝着哪个方向进行搜索。针对不同硬件,评估方式也有所区别。CPU和GPU编译是非常快,每次运行时间也很短,就可以直接在硬件进行测量。FPGA或CGRA需要的时间很长,可能需要几个小时,就通过Cost Model方式做评估。
启发式搜索是基于模拟退火算法寻找起始点,在已经评估的点当中寻找最好的。为了避免局部最优,梁云团队设计了以下的概率公式,点越好选择它的概率就越大。公式中V*是已知的最优点,也可以选择其它非优的点。

机器学习部分是通过Q-Learning选择方向,每次预测不同方向的Q值,选择最大的,也会去除已访问的点以避免回溯。具体来说使用的是DQN算法,把输入的点生成向量,表示不同方向上的Q值,再选择最大的Q值为最好的方向。
DQN算法涉及推断(Inference)和训练(Training)。推理是把所有已评估的点放在H集合当中,每次更新H集合。选择一个点后,经过DQN算法输出一个向量,选择一个最大的方向,再做评估,把点不断加入H集合。
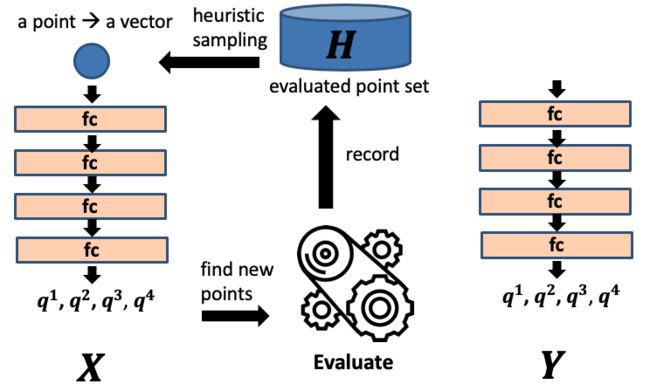
图14:DQN算法的推断
训练时会为原始网络X创建一个孪生网络(Twin Network) Y,整个过程当中X和Y迭代相互更新。Y表示真值,每次用X输出的值和Y算出损失(Loss),再适度更新X。然后周期性的用X更新Y。

图15:DQN 算法的训练
⑤代码生成
最后是代码生成,针对CPU、GPU和FPGA三种硬件。
CPU专注的优化手段包括多平铺(Multi-level tiling), 多线程(Multi-level Threading)和向量化(Vectoration)。GPU专注的是多线程和线程块结构的组合和共享内存的使用。FPGA自定了三个阶段的流水线(Pipeline),分别是数据读取,计算和写入。最重要的优化手段是带宽,也会考虑DSP资源和BRAM存储的限制。
三、实验方式与结果
接下来,梁云介绍了FlexTensor的实验情况。实验利用了12种广泛使用的Tensor计算,如Conv、GEMM等,并比较了几何平均数和绝对性能,而且还在不同平台上和已有的手动开发库做了对比。结果表明,FlexTensor在以下诸多方面都表现出不错的提升。
总体GPU实验结果
在三个平台上,FlexTensor都比CuDNN性能有所提升。

图16:总体GPU实验结果
Convo2d-GPU实验结果
平均比cuDNN有1.5倍绝对性能的提升,比PyTorch (Native)有1.56倍绝对性能的提升。

图 17:Conv2d-GPU实验结果
Convo2d-CPU实验结果
几何平均数得到更大的提升, 绝对性能比MKL-DNN差一点。主要原因是在C6配置上FlexTensor比PyTorch差距较大。其它方面FlexTensor都表现得非常好,所以这个实验当中几何平均数可以更真实地反映效果。

图 18:Conv2d-CPU实验结果
Convo2d-FPGA实验结果
和之前的手动优化相比也有1.5倍左右的性能提升。
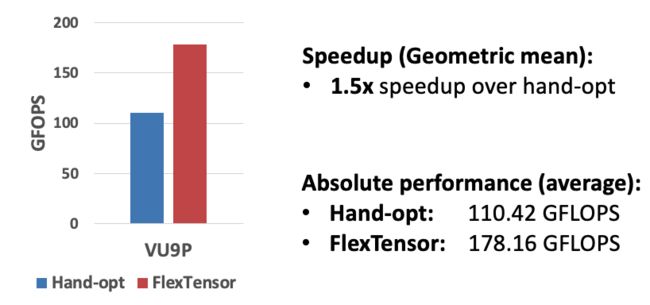
图19:Conv2d-FPGA实验结果
Auto-TVM与手写模板对比结果
最后,和Auto-TVM手写模板相比,FlexTensor自动化模板搜索比Auto-TVM性能更高(见图20),并且只使用了27%的时间就达到此性能(见图 21)。

图20:FlexTensor和TVM比较实验结果

图21:FlexTensor和TVM探索时间和性能比较 (红线是FlexTensor加上Q-Learning,蓝线是FlexTensor没有Q-Learming,绿线是TVM)
结语
演讲最后,梁云总结FlexTensor的特征,便是将张量计算的优化变成全自动过程,针对不同的硬件,如CPU、GPU和FPGA等生成不同的张量算子库,其核心技术便是基于DQN算法的Q-Learning以及启发式搜索。
据悉,FlexTensor项目已经开源,感兴趣的朋友们可以在Github上下载、体会它的奥妙,网址是:https://github.com/KnowingNothing/FlexTensor。
Q&A
Q:这项工作和HeteroCL有什么区别?
A:HeteroCL是针对FPGA是编程范式,我们是针对张量运算的自动生成算子库,而且面向异构系统包括CPU、FPGA、GPU目的不一样。
Q:FlexTensor开源就是已经把Source Code Release,GPU上面比较的对象是目前最优的时限吗?自动优化相比手动优化更好吗?
A:CPU都是已经优化的,cuDNN是GPU上最优的Library,包括INTEL和MQL相比,都是对比当前最优。
Q:相比TVM的区别是什么?
A:目前为止,TVM 优化是半自动的,但是Primitive的组合非常难写,有非常多的Primitive选择,组合空间非常大,所以我们把这一步变成了自动化。这是主要区别。
- 2020北京智源大会设立智能体系架构与芯片论坛-
-点击阅读原文或长按图片,内行盛会,首次免费注册-




