<<Python深度学习>>二分类问题之多个深度学习网络优劣
文章目录
- 一. 书中默认网络模型 - 更换Optimizer后效果有改善
-
- 1. 网络模型
- 2. Compile模型
-
- 2.1 RMSprop
- 2.2 SGD
- 2.3 Adagrad
- 2.4 Adam
- 二. 另外一个模型
-
- 1. 网络模型
- 2. Compile模型
-
- 2.1 RMSprop
- 2.2 SGD
- 2.3 Adagrad
- 2.4 Adam
- 三. 总结
本文旨在通过一个简单的二分类问题, 利用不同的模型, 参数来理解背后的含义.
模型训练的最终结果是在测试集上得到最低的loss,已经最高的精度.
一. 书中默认网络模型 - 更换Optimizer后效果有改善
1. 网络模型
model=models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 160016
_________________________________________________________________
dense_1 (Dense) (None, 16) 272
_________________________________________________________________
dense_2 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
2. Compile模型
2.1 RMSprop
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
history=model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val,y_val))
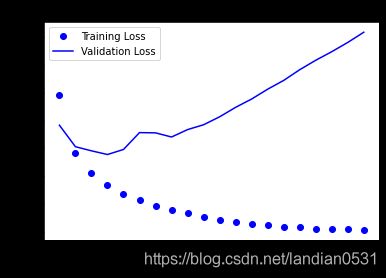
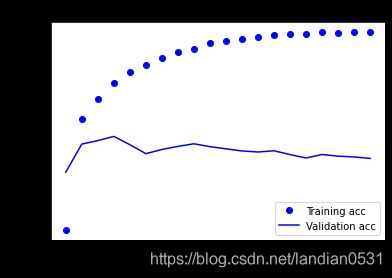
通过训练得出如下结果:
训练loss不断下降, accuracy不断上升, 这是梯度下降预期的效果.
但是在验证集上效果非常不好, 根据书中所说, 为防止过拟合,在三轮之后停止训练.
在测试集上结果: loss: 0.7933 - accuracy: 0.8474
以下是只训练4轮的结果:
可以看到loss比之前低了, 精度和之前相比提升不多.
history=model.fit(partial_x_train,
partial_y_train,
epochs=4,
batch_size=512,
validation_data=(x_val,y_val))
测试集: loss: 0.3365 - accuracy: 0.8633


2.2 SGD
把Optimizer 从 RMSprop换成SGD, epochs=20 训练集和验证集基本重合. (所以如果增加epochs到100, 结果会怎样呢?)
测试集: loss: 0.3867 - acc: 0.8436
model.compile(optimizer='SGD',
loss='binary_crossentropy',
metrics=['acc'])


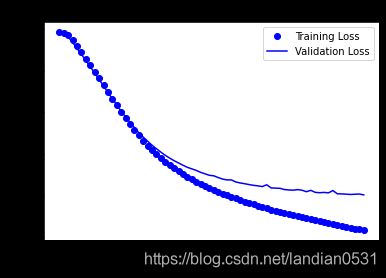
Epochs加到100, 结果如下:
虽然测试集依然有空间, 但是验证集在epochs=70左右就无法继续优化了.
测试集结果:loss: 0.3109 - acc: 0.8707

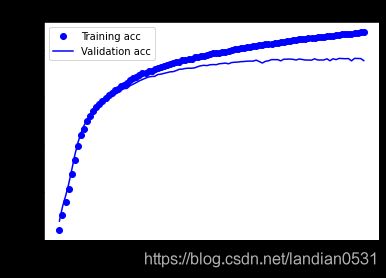
为求最佳, epochs=70, 结果:loss: 0.3041 - acc: 0.8748

2.3 Adagrad
经过测试 Epochs加到200, 虽然进展缓慢, 但是最后依然还有些许上升空间.
测试集结果:loss: 0.3259 - acc: 0.8682
model.compile(optimizer='Adagrad',
loss='binary_crossentropy',
metrics=['acc'])


2.4 Adam
经过测试epochs=5时, 最佳.
测试集: loss: 0.3095 - acc: 0.8770


结论, 在这个数据集上,Optimizer的改变对最后结果有影响, 那如果我们改变模型结构呢???
二. 另外一个模型
参考
https://builtin.com/data-science/how-build-neural-network-keras
源代码有误, 略作修改.
1. 网络模型
from keras import models
from keras import layers
model=models.Sequential()
# Input - Layer
model.add(layers.Dense(50, activation = "relu", input_shape=(10000, )))
# Hidden - Layers
model.add(layers.Dropout(0.3, noise_shape=None, seed=None))
model.add(layers.Dense(50, activation = "relu"))
model.add(layers.Dropout(0.2, noise_shape=None, seed=None))
model.add(layers.Dense(50, activation = "relu"))
# Output- Layer
model.add(layers.Dense(1, activation = "sigmoid"))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 50) 500050
_________________________________________________________________
dropout (Dropout) (None, 50) 0
_________________________________________________________________
dense_1 (Dense) (None, 50) 2550
_________________________________________________________________
dropout_1 (Dropout) (None, 50) 0
_________________________________________________________________
dense_2 (Dense) (None, 50) 2550
_________________________________________________________________
dense_3 (Dense) (None, 1) 51
=================================================================
Total params: 505,201
Trainable params: 505,201
Non-trainable params: 0
2. Compile模型
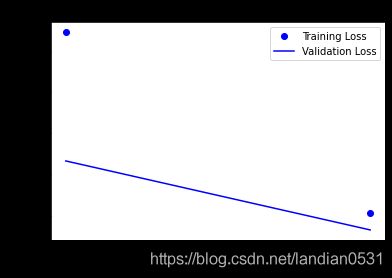
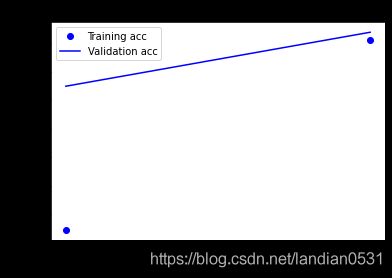
2.1 RMSprop
经过测试 epochs=3 最佳
测试集:loss: loss: 0.2951 - accuracy: 0.8820
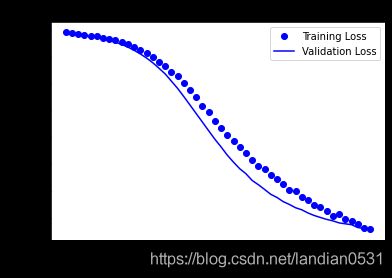
2.2 SGD
epochs=50最佳, 测试集: loss: 0.3345 - acc: 0.8604
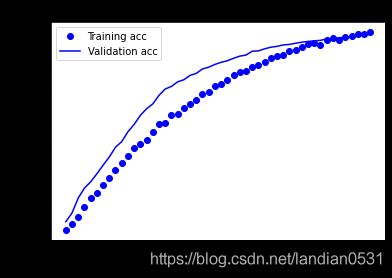
2.3 Adagrad
epochs=200 结果:
测试集:0.3220 - acc: 0.8670

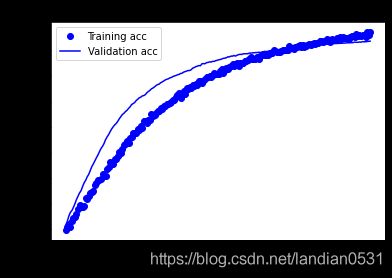
2.4 Adam
用网页上的Adam试试, epochs只有2, batch_size=500.
测试集:loss: 0.2893 - acc: 0.8830 目前最好成绩!!
我也尝试了增加epochs, 但是数据直接起飞, 所以epochs=2是最好的.
三. 总结
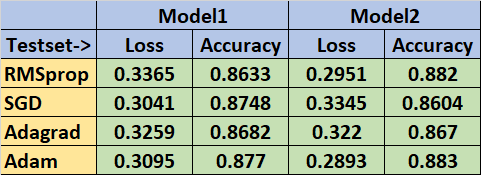
一通测试下来, 结果如下: