智源发布 | 大规模并行训练效率提升神器 TDS

众所周知,「数据」、「算法」、「算力」是当下这轮人工智能技术崛起的重要驱动力。利用海量数据训练大规模机器学习模型有助于我们充分学习数据中蕴含的知识,实现更好的训练效果。然而,随着训练规模的扩大,单张 GPU 卡的显存与计算效率已经无法满足训练的需要,通过分布式训练框架实现多 GPU 并行训练成为了一种新的刚需。
为了提升多 GPU 并行训练的效率,研发更高效的并行计算框架是十分必要的。因此,作为北京人工智能研究院(简称「BAAI」)超大规模智能模型系统“悟道”的阶段进展,TDS(Tsinghua/Temporary DeepSpeed)插件横空出世,该插件进一步优化了如今最流行的DeepSpeed 并行计算框架,从而「多快好省」地训练一个大模型。更多细节请参阅智源「悟道」系统的中文预训练工程(https://github.com/TsinghuaAI/CPM-Pretrain)和TDS插件(https://github.com/TsinghuaAI/TDS)
多快好省:迈向高效大模型训练之路
回顾过去几年,人工智能领域的发展总是绕不开两个词——「深度学习」和「GPU」。随着一些现代深度学习模型参数量越来越大,其对计算资源的需求与日俱增,这种需求反过来也促进了计算设备的更新换代,两者相得益彰,推动着整个人工智能行业的发展。
在深度学习江湖中,科技巨头们具备「碾压性」的算力优势,每当它们训练出具有「骇人听闻」参数量的超大模型,并且在各个任务中「屠榜」,总会引来各路从业者的围观。而由于训练现代深度学习模型往往需要强大的算力作为支撑,从业者们每年都会翘首以待英伟达的黄老板从烤箱中掏出什么新的宝(xian)贝(ka)。
举例而言,OpenAI 近期发布了使用超过 10,000 张显卡训练的 GPU-3 模型,该模型具有 1,750 亿参数,在多个任务上取得了目前最佳的性能,堪称「一力降十会」!我们无法断言当前这种追求参数规模的态势是不是一条合理的人工智能发展路线,但至少在当下,传统框架在训练较大规模参数量的模型时实打实地遇到了瓶颈。为此,英伟达、微软等科技巨头针对「如何利用大规模 GPU 集群满足超大模型的训练需求」这一课题展开了「科研竞赛」。
为应对大规模计算集群高效训练方法的需求,北京智源人工智能研究院发挥其在硬件设计、模型架构、编程框架研发等方面的优势,组织智源「悟道」团队科研人员研发了 TDS 插件,对当下主流的并行计算框架进行了优化。

图 1:主流并行计算框架一览
深度学习并行计算框架进化史
TensorFlow 和 PyTorch 是当前在学术界中最为流行的深度学习编程框架,原生的 TensorFlow 和 PyTorch 都支持多 GPU 数据并行计算接口。

图 2:PyTorch 并行训练
就工业界而言,为了实现具有超大参数量的模型训练,NVIDIA 于 2019 年基于 PyTorch 实现了面向预训练语言模型的并行计算框架 Megatron-LM,该框架可以训练具有数十亿参数的模型。2020 年,微软在 Megatron-LM 的基础上研发了面向 PyTorch 编程的 DeepSpeed 并行计算框架,实现了包括「流水线并行」和「ZeRO 系列技术」在内的训练加速技术。

图 3:DeepSpeed 流水线模块中的问题
然而,DeepSpeed 工程存在一些一些鲁棒性方面的缺陷(例如,DeepSpeed 的流水线模块只能兼容特定输入输出格式的模型)。
为此,BAAI「悟道」项目团队为 DeepSpeed 实现了一个解决流水线并行模块中存在漏洞的插件「Tsinghua/Temporary DeepSpeed 」(TDS)。
TDS 重新实现了 DeepSpeed 的流水线并行模块,通过适配器模式(一种软件设计模式)将 DeepSpeed 的其它功能封装到该模块中,有效降低了使用难度。使用者只需要替换少数若干行代码就可以通过 TDS 插件解决 DeepSpeed 中存在的漏洞,同时不对 DeepSpeed 的其它功能产生影响。
常用并行计算方法概览
当前在 GPU 集群上常用的并行计算方式包括:数据并行、模型并行和流水线并行。我们可以混合使用这三种并行计算方式,即「混合并行」。对于 GPU 数量不足的使用者而言,微软 DeepSpeed 框架中提出的并行优化组件 The Zero Redundancy Optimizer (ZeRO) 和 ZeRO-Offload 技术可以混合使用 GPU 和 CPU,降低显存的压力。
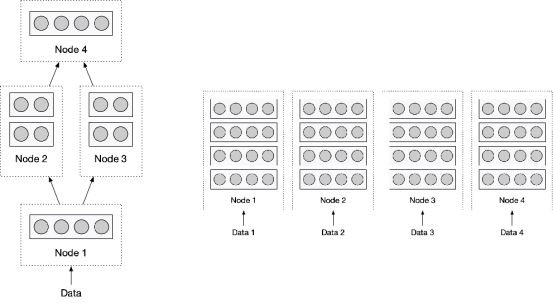
图 4:(左)模型、流水并行(右)数据并行
数据并行:将训练数据分而治之
数据并行是一种简单的并行计算方法,其思想是在分布式计算集群中的各个计算节点上复制一份相同的模型参数,进而在各个计算节点上使用相同的模型对各自接收到的输入数据进行计算。根据具体的实现方式,我们又可以将「数据并行」分为「同步训练」和「异步训练」模式。
模型并行与流水线并行:将模型由大化小
尽管数据并行往往可以有效提升计算效率,但是该方法无法拓展模型的参数。如果一个模型的参数量已经大到 GPU 显存无法存下,那么仅靠数据并行就无法解决显存不足的问题。此时,我们需要采用模型并行和流水线并行计算方法。
模型并行的主要思想是:将模型进行切分,然后将其分配到多个计算节点上,以减少单个计算节点的参数量。常见的切分方法是:将模型的每一层参数平均切分到多个计算节点上。该方式能够减少单个计算节点的参数量和计算量,但会引入大量的通信和同步开销。
流水线并行是另一种模型并行实现方式,它指的是:将模型按层为粒度进行切分,并且将不同层的参数分配给各个计算节点。流水线并行在对模型参数进行切分的同时,能够降低节点之间的通信量。但是,在我们启动和停止流水线之间的时间里,会有部分节点处于等待状态,这在某种程度上也导致了部分算力的浪费。
模型并行与流水线并行各有优劣,一般需要根据显卡、机器之间的通信速度来决定如何使用。
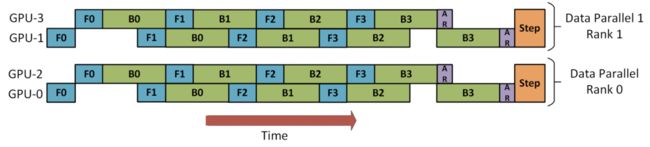
图 5:Microsoft 的 Deepspeed 中的
流水线并行示意图
通过智源 TDS 插件优化
DeepSpeed 框架
使用 DeepSpeed 实现流水并行
使用 DeepSpeed 进行流水并行只需要将模型的各个层加入队列中,并用队列实例化DeepSpeed 的「PipelineModule」类。然而,受限于 DeepSpeed 框架本身的设计,队列中的各个层输入的张量(Tensor)数和输出的张量数必须保持一致,以确保各层之间可以无缝衔接。例如,在实现一个流水线式并行的 Transformer 版本时,模型的每一层都需要输出「hidden_states」和「mask」,从而下一层的输入相衔接。具体的实现代码如下:
from deepspeed.pipe import PipelineModule, LayerSpec...class TransformerBlockPipe(TransformerBlock) def forward(self, ...): hidden, mask = ... ... output = super().forward(hidden, mask) return (output, mask)...class GPT2(PipelineModule): def __init__(self, num_layers, ...): ... specs = [TransformerBlockPipe() for _ in range(num_layers) ] ... super().__init__(layers=specs, ...)
我们也可以很容易地使用 DeepSpeed 进行混合加速。具体而言,我们只需要令加入流水队列里的模型基于模型并行实现。这个大家可以参考我们的代码或者查看Megatron-LM。
使用 TDS 优化训练流程
北京智源人工智能研究院发布的 TDS 插件重新实现了 Deepspeed 的流水线,通过适配器模式封装了 DeepSpeed 的其它功能,该插件十分易于使用。如果已经完成了对 DeepSpeed 的安装,我们只需要将 TDS 的代码拷贝到工程中,然后用以下的方式加载 deepspeed 库即可。
import tds as deepspeed
我们可以通过与上文中使用 DeepSpeed 的范例代码相同的训练流程代码来训练 TDS。首先,我们需要构建一个获取数据迭代器的模块。
def train_valid_test_datasets_provider(...): ... train_ds, valid_ds, test_ds = build_train_valid_test_datasets(...) ...return train_ds, valid_ds, test_ds
然后,需要一个从「data_iterator」中获取数据,并且分发给各个 GPU。
def get_batch(data_iterator): ...# 定义传输的数据类型 keys = ['text'] datatype = torch.int64# 将数据压缩之后广播到同一个数据并行group中的每个GPU上if data_iterator is not None: data = next(data_iterator)else: data = None data_b = mpu.broadcast_data(keys, data, datatype)# 将数据解压 tokens_ = data_b['text'].long()# 从数据中提取token, label, mask信息 tokens, labels, loss_mask, attention_mask, position_ids = (...) ...return tokens, labels, loss_mask, attention_mask, position_ids
流水线并行需要一个单独的数据获取分发模块,该模块的整体结构与上述代码中的「get_batch」类似,但有两个细微差别。首先,DeepSpeed 中将流水线并行的「data_iterator」交给了后台管理,所以「get_batch_pipe」只需要负责分发数据即可。第二,DeepSpeed 对给流水线使用的「data_iterator」是有格式限制的,必须返回两个元组(tuple),前一个元组被用来进行前馈的输入,后一个元组被用作损失函数的的输入。
def get_batch_pipe(data):... # 定义传输的数据类型keys = ['text']datatype = torch.int64 # 将数据压缩之后广播到同一个数据并行group中的每个GPU上data_b = mpu.broadcast_data(keys, data, datatype) # 将数据解压tokens_ = data_b['text'].long() # 从数据中提取token, label, mask信息tokens, labels, loss_mask, attention_mask, position_ids = (...)...return (tokens, position_ids, attention_mask), (labels, loss_mask)
在实现了数据获取的各项模块后,我们可以根据是否使用流水线并行返回不同的模型实现模型获取模块。与 DeepSpeed 相比,TDS 中需要制定「流水线中间的输入输出类型」、「是否需要保存梯度」,以及「是否需要对中间结果进行切割,并将其到多个 GPU 上,从而减少显存使用」。
def model_provider():"""Build the model.""" args = get_args()if args.pipe_parallel_size == 0 : model = GPT2Model(...)else: model = GPT2ModelPipe(...) model._megatron_batch_fn = get_batch_pipe# TDS中需要制定流水线中间的输入输出类型,是否需要保存梯度,以及是否需要将中间结果切割到多个GPU来减少显存使用 model._input_grad = [True, False] model._input_type = ['float', 'bool'] model._input_pipe_partitioned = [True, False]return model
最后,我们可以基于上述模块,启动「pretrain」,并开始计算。
from megatron.training import pretrain
if __name__ == "__main__": pretrain(train_valid_test_datasets_provider, model_provider, ...)
总结
从BERT 到 RoBERTa 再到 GPT3,大规模预训练模型日益受到深度学习从业者的关注。为了降低训练大规模机器学习的门槛,北京智源人工智能研究院发布了 TDS 并行训练组件,优化了目前最先进的 DeepSpeed 并行训练框架。欢迎大家使用该插件并向我们提出宝贵的建议,我们将持续维护 TDS 插件以及 CPM-Pretrain 中文预训练框架。
参考链接
[1]Shoeybi M, Patwary M, Puri R, et al. Megatron-LM: Training multi-billion parameter language models using model parallelism. 2019.
[2]Rajbhandari S, Rasley J, Ruwase O, et al. Zero: Memory optimization towards training a trillion parameter models. 2019.
[3]Rasley J, Rajbhandari S, Ruwase O, et al. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. 2020.
[4]Ren J, Rajbhandari S, Aminabadi R Y, et al. ZeRO-Offload: Democratizing Billion-Scale Model Training. 2021.
[5]DeepSpeed: https://github.com/microsoft/DeepSpeed
[6]DeepSpeed Examples for 3D parallelism: https://github.com/microsoft/DeepSpeedExamples/tree/20ea07a2a069696abec212e25476a9bf76aced70/Megatron-LM-v1.1.5-3D\_parallelism
[7]Megatron-LM: https://github.com/NVIDIA/Megatron-LM
[8]TDS: https://github.com/TsinghuaAI/TDS
CPM-Pretrain: https://github.com/TsinghuaAI/CPM-Pretrain
供稿作者
韩旭(清华大学自然语言处理与社会人文计算实验室)
陈晟祺(清华大学并行与分布式计算机系统实验室)
孙桢波(清华大学并行与分布式计算机系统实验室)

参与线下沙龙活动,扫描二维码报名:
