备注检索py_mat
MATLAB and py
- MATLAB
-
- dbstop if error
- numel
- cat
- py
-
- python学习记录
-
- 类
-
- 类属性
- 静态方法
- 类方法
- __enter__() 和 __exit__() 方法(没看懂)
- 迭代
- @check_login内部会执行以下操作:
- 计算运行时间
- 对应数组元素相乘
- 两个变量 for
- log对数
- np.logical_and
- if多条件
- numpy.intersect1d
- with
- python 读取mat文件
- only integer scalar arrays can be converted to a scalar index
- python 描述路径的三种格式
- np.where
- 注意py中的切片方式
- Python创建类似Matlab中的cell数组
- Object arrays cannot be loaded when allow_pickle=False
- list 变numpy
- np.concatenate()
- 判断数组是否为空
- 增加一行或者一列(insert)
- .extend 和.append
- numpy维度
-
- 多维数组变成一维
- 增加维度
- 减少维度
- 维度变化
- 报错
-
- 路径报错
- 装库报错
- 频谱图
- range()函数
- imbalanced-learn
- np.column_stack
- python滤波
- 画图
-
- backend 设置 matplotlib
- 希腊字母
- legend
- 点图
- 阴影
- 设置y轴标签
- 设置xy轴范围
- 保存图片
- %matplotlib
MATLAB
dbstop if error
当MATLAB运行程时,MATLAB遇到错误就会停在发生错误的那一行代码
numel
数组元素的数目
cat
串联数组
py
python学习记录
参考链接
https://www.itprojects.cn/coursecenter
之前一直没有对这部分内容系统性的去看,代码中很多面向过程的处理,复用率低且不规范
类
面向对象编程,对类 ,继承重写的理解,如何对类进行复用,隐藏函数,私有参数多态
类属性
用来存储共享的数据
静态方法
@staticmethod修饰的方法,就是静态方法 不需要self参数
类方法
如果想要让一个方法成为类方法我们只需要在这个方法的前面添加@classmethod即可,与此同时需要在方法的第1个形参位置添加cls
enter() 和 exit() 方法(没看懂)
迭代
之前 关于 for in 这种方式一直使用,以为是matlab中类似的方法,就是for的一种变形,在python里面使用更加方便,运来in后面是一个迭代器,平时使用是数组是可以迭代的,在pytorch使用的时候我们定义的dataset本质上是将数据放到了迭代器里。
只要是通过isinstance来判断出是Iterable类的实例,即isinstance的结果是True那么就表示,这个数据类型是可以迭代的数据类型。
isinstance(100, Iterable)
False
@check_login内部会执行以下操作:
步骤1:执行check_login函数
执行check_login函数 ,并将 @check_login 下面的函数作为check_login函数的参数
即:
计算运行时间
import time
start = time.clock()
# 程序代码段运行
end = time.clock()
print(end-start)
对应数组元素相乘
np.multipy(x1,x2)
两个变量 for
for x, y in ((a,b) for a in path_csv for b in path_x):
log对数
对于单个数字的计算
import math
math.log(x[, base])
math.log(10,math.e)
对于数组的取log 利用numpy
np.log
以10为底np.log10(x)
以e为底np.log(x)
np.logical_and
(逻辑与)
if多条件
and or 括号
numpy.intersect1d
数组交集
with
with语句的工作原理:
紧跟with后面的语句会被求值,返回对象的__enter__()方法被调用,这个方法的返回值将被赋值给as关键字后面的变量,当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法。
with语句最关键的地方在于被求值对象必须有__enter__()和__exit__()这两个方法,那我们就可以通过自己实现这两方法来自定义with语句处理异常。
示例代码:
#encoding=utf-8
class opened(object):
def __init__(self,filename):
self.handle=open(filename)
print "Resource:%s"%filename
def __enter__(self):
print "[enter%s]: Allocate resource."%self.handle
return self.handle#可以返回不同的对象
def __exit__(self,exc_type,exc_value,exc_trackback):
print "[Exit %s]: Free resource." %self.handle
if exc_trackback is None:
print "[Exit %s]:Exited without exception."%self.handle
self.handle.close()
else:
print "[Exit %s]: Exited with exception raised."%self.handle
return False # 可以省略,缺省的None也是被看做是False
with opened(r'd:\\xxx.txt') as fp:
for line in fp.readlines():
print line
opened中的__enter__() 返回的是自身的引用,这个引用可以赋值给 as 子句中的fp变量;
返回值的类型可以根据实际需要设置为不同的类型,不必是上下文管理器对象本身。
exit() 方法中对变量exc_trackback进行检测,如果不为 None,表示发生了异常,返回 False 表示需要由外部代码逻辑对异常进行处理;
如果没有发生异常,缺省的返回值为 None,在布尔环境中也是被看做 False,但是由于没有异常发生,exit() 的三个参数都为 None,上下文管理代码可以检测这种情况,做正常处理。exit()方法的3个参数,分别代表异常的类型、值、以及堆栈信息。
参考链接https://www.cnblogs.com/xiaxiaoxu/p/9747551.html
python 读取mat文件
使用scipy:
import scipy.io as scio
data_path="train.mat"
data = scio.loadmat(data_path)
data_train_label=data_train.get('label')#取出字典里的label
data_train_data=data_train.get('data')#取出字典里的data
mat是结构体的形式,就多写一层
only integer scalar arrays can be converted to a scalar index
TypeError: only integer scalar arrays can be converted to a scalar index
报错信息直接翻译过来是只有整型标量数组才能转换成标量索引,然而问题一般都不在于你的索引是不是整数。这个报错一般会出现在你想使用一个索引数组去索引一个列表,即诸如list[indexarray]的形式,此时就会出现此报错。
比较简单的解决方法是把你想要索引的列表转换为numpy数组,再对其进行索引,即:np.array(list)[indexarray]
扩展一下,用索引列表去索引另一个列表也是不被允许的,即使用 list[indexlist] 时会出现 list indices must be integers or slices, not list的报错信息,此时同样可以将list转化为ndarray避免报错。
最后总结一下,在python中用索引数组或索引列表去索引某个列表都是不被允许的;相反,你既可以用索引数组也可以用索引列表去索引某个numpy数组。所以当你想使用较为简便的索引操作时,尽可能地将数据类型转换为numpy数组进行处理,而不是列表。
参考链接:https://blog.csdn.net/tcltyan/article/details/108430613
python 描述路径的三种格式
方式一:转义的方式
'd:\\a.txt'
方式二:显式声明字符串不用转义
'd:r\a.txt'
方式三:使用Linux的路径/
'd:/a.txt'
np.where
np.where(condition,x,y)
多条件时condition,&表示与,|表示或。
注意py中的切片方式
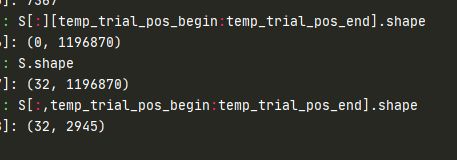
后面一种切片方式才是对的
Python创建类似Matlab中的cell数组
npose = 5
nsmile = 2
poseSmile_cell = np.empty((npose,nsmile),dtype=object)
for i in range(5):
for k in range(2):
poseSmile_cell[i,k] = np.zeros((4,4))
print poseSmile_cell.shape
读取和处理长短不同的数据的一个格式
参考链接
https://blog.csdn.net/raby_gyl/article/details/78016690
Object arrays cannot be loaded when allow_pickle=False
load的文件中包含object格式
load语句里面加上allow_pickle=True
参考链接
https://blog.csdn.net/hejp_123/article/details/94553524
list 变numpy
np.array(a)
np.concatenate()
- 两个一维数组
import numpy as np
a=[1,2,3]
b=[4,5,6]
np.concatenate((a,b),axis=0)
#输出
array([1, 2, 3, 4, 5, 6])
- 两个二维数组
- 两个三维数组
- 多个数组一起合并
- https://www.jianshu.com/p/a094a954ff61
判断数组是否为空
第一种是if x is None;
第二种是 if not x:;
第三种是if not x is None(这句这样理解更清晰if not (x is None)) 。
if x is not None是最好的写法,清晰,不会出现错误,以后坚持使用这种写法。
使用if not x这种写法的前提是:必须清楚x等于None, False, 空字符串"", 0, 空列表[], 空字典{}, 空元组()时对你的判断没有影响才行。
增加一行或者一列(insert)
import numpy as np
a = np.array([[1,2,3],[4,5,6],[7,8,9]])
b = np.array([[0,0,0]])
c = np.insert(a, 0, values=b, axis=0)
d = np.insert(a, 0, values=b, axis=1)
print(c)
print(d)
#输出
>>c
[[0 0 0]
[1 2 3]
[4 5 6]
[7 8 9]]
https://www.cnblogs.com/wqbin/p/11904002.html
.extend 和.append
lis.append(a)添加的是a这个整体;
list1=[1,3,4,5]
a=(1,2)
list1.append(a)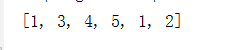
print(list1)
#输出
[1,3,4,5,(1,2)]
而 lis.extend(a) 会把a中的各个元素分开, a中的内容不再是一个整体
list1=[1,3,4,5]
a=(1,2)
list1.extend(a)
print(list1)
#输出
[1,3,4,5,1,2]
https://blog.csdn.net/qq_39062888/article/details/88430512
numpy维度
多维数组变成一维
np.ravel()
增加维度
x1 = x[np.newaxis, :] ##增加行维度
x1 =x[:, np.newaxis] ##增加列维度
https://www.jb51.net/article/144967.htm
减少维度
np.squeeze
维度变化
reshape
注意两种形式,默认是先行后列的填进新的shape里
参考链接
报错
路径报错
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 48-49: truncated \uXXXX escape
d1file =r'D:\code_cloud\change_to_image\deep_learning_code\use_sub.mat'
装库报错
ValueError: check_hostname requires server_hostname

关上科学上网就可以了
参考链接
https://blog.csdn.net/u010037715/article/details/118277228
频谱图
import matplotlib.pyplot as plt
ax.pcolormesh(t, f, Sxx)
ax.set_ylabel('Frequency [Hz]')
ax.set_xlabel('Time [sec]')
plt.show()
range()函数
区别在于range()函数是python内置函数,arange()是numpy多维数组库里面的库函数。前者所实现的数据间隔步长只能为整数,后者可以是浮点数。
函数说明: range(start, stop[, step]) -> range object,根据start与stop指定的范围以及step设定的步长,生成一个序列。
参数含义:start:计数从start开始。默认是从0开始。例如range(5)等价于range(0, 5);
end:技术到end结束,但不包括end.例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
scan:每次跳跃的间距,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
函数返回的是一个range object
np.arange()
函数返回一个有终点和起点的固定步长的排列,如[1,2,3,4,5],起点是1,终点是6,步长为1。
参数个数情况: np.arange()函数分为一个参数,两个参数,三个参数三种情况
1)一个参数时,参数值为终点,起点取默认值0,步长取默认值1。
2)两个参数时,第一个参数为起点,第二个参数为终点,步长取默认值1。
3)三个参数时,第一个参数为起点,第二个参数为终点,第三个参数为步长。其中步长支持小数
https://blog.csdn.net/qianwenhong/article/details/41414809
imbalanced-learn
数据不平衡处理的库
np.column_stack
按列合并
python滤波
from scipy import signal
(b,a)=signal.butter(4,2*5/250,btype='low',output='ba')
S=signal.filtfilt(b,a,S)
画图
backend 设置 matplotlib
查看 系统支持的交互式后端格式
import matplotlib as mpl
mpl.rcsetup.interactive_bk
['GTK3Agg',
'GTK3Cairo',
'GTK4Agg',
'GTK4Cairo',
'MacOSX',
'nbAgg',
'QtAgg',
'QtCairo',
'Qt5Agg',
'Qt5Cairo',
'TkAgg',
'TkCairo',
'WebAgg',
'WX',
'WXAgg',
'WXCairo']
引入
import matplotlib.pyplot as plt
mpl.use( 'QtAgg')
希腊字母
plt.ylabel('Value/'+r'$\mu$'+'V');
legend
plt.plot(x,y1, label='Original Signal',color='blue');
plt.plot(x,y2, linestyle=':', label='Transformed Wavelet Signal',color='red');
plt.legend();
点图
ss1=[68,418,650,906];
ss2=[36,99,387,455,620,680,876,940];
plt.scatter(x[ss2],y1[ss2],marker='D', edgecolor='green',
facecolor='green');#,x[ss],y2[ss],marker='_'
plt.scatter(x[ss1],y1[ss1],marker='D',edgecolor='red',
facecolor='red');#,x[ss],y2[ss],marker='_'
plt.scatter(x[ss2],y2[ss2],marker='D',edgecolor='green',
facecolor='green');#,x[ss],y2[ss],marker='_'
plt.scatter(x[ss1],y2[ss1],marker='D',edgecolor='red',
facecolor='red');#,x[ss],y2[ss],marker='_'
阴影
plt.fill_between(x, -18,143 ,facecolor='grey', alpha=0.3)
设置y轴标签
plt.yticks([-80,-40,-18,0,40,80,120,143,160,200], ['-80','-40',r'$\theta_l$','0','40','80','120', r'$\theta_h$','160','200'])
设置xy轴范围
plt.xlim(0,4);plt.ylim(-70,205)
保存图片
fig=epochs[sub_num].plot()
fig.savefig(str(sub_num+label*30)+'filterdata.png')
其实非常简单,但是之前我一直使用plt.savefig plt.show()可以观察到图片 plt.savefig 保存的就是空白图片
%matplotlib
而具体作用是当你调用matplotlib.pyplot的绘图函数plot()进行绘图的时候,或者生成一个figure画布的时候,可以直接在你的python console里面生成图像。