基于强化学习和析取图模型的统一调度框架
框架定义
基于析取图模型的复杂车间调度问题存在两类决策点:一是需要根据工序排序规则(Job sequencing rule,JSR)对就绪任务集合中的所有工序进行优先级排序,选择最优先的工序进行加工;二是需要根据机床分派规则(Machine assignment rule,MAR),为之前选择的最优先工序从其所有可选机床集合中选择最优先的机床。在一般的作业车间调度问题中,由于机床提前确定,只存在JSR一个决策点,而在柔性作业车间调度问题中这两类决策点均存在。本文针对作业车间和柔性作业车间调度问题进行研究,采用强化学习方法分别训练单个决策点和同时训练两个决策点,得到优秀的调度策略。
图17为本文设计的基于强化学习和析取图模型的统一调度框架,该框架将作为后续三部分研究内容的设计基础。虽然这三章内容按照研究问题由作业车间调度到柔性作业车间调度、约束条件由少量简单到大量复杂、训练算法由值函数法和策略梯度法到混合并行算法这三个方面逐层递进的方式进行组织,但是这三章所要解决的问题类型、考虑的约束和采用的训练算法都是基于该统一调度框架实例化出来的,这也验证了强化学习跨领域求解问题的能力,即可以通过与不同的环境进行交互,定义不同的状态、动作、奖励等元素,实现对不同问题的求解。

该框架主要包含四部分:调度环境生成器、训练层、算法层和测试层。
调度环境生成器的作用体现在三方面,首先可根据用户自定义的参数分布生成问题实例,这些参数包括工件数、工序数、机床数等,可通过控制工序可选机床数来生成作业车间调度问题还是柔性作业车间调度问题,然后将这些实例传递到训练层构成训练集和验证集;强化学习的训练过程同元启发式算法的迭代优化一样,都需要一定的扰动来平衡算法的探索和利用,调度环境生成器的第二个作用就是可以自定义随机种子以保证强化学习训练实验的可复现性;最后生成器还可生成扰动事件以产生新的问题实例,这些实例在测试层构成了测试集,用于测试训练后的调度策略。
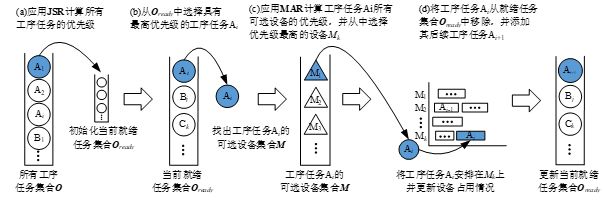
训练层包括状态感知器、动作执行器、奖励计算器、训练集和验证集以及析取图模型。状态感知器用于根据调度特征计算反映调度问题本质的调度状态,并传递给算法层,状态可以是一幅图像,一组由整体信息、任务信息和机床信息构成的特征向量,或者是由整体和局部信息构成的特征向量;动作执行器将接收到的强化学习动作序号映射为可以影响调度结果的排序规则或约束设置;奖励计算器则根据调度目标和设计的奖励函数,在一个或一组动作执行完后对其进行评价,并传递给算法层,奖励可以是等价奖励也可以是启发式奖励;训练集存储了用于训练强化学习代理的训练样本,这些样本最好在状态空间中均匀分布以使训练的模型具有更优的拟合能力;验证集用于调整模型的超参数和对模型的能力进行初步评估,通常每训练一定次数后就验证一次;如果说强化学习的输出决定了采取的动作,那么基于析取图模型的调度生成方式就决定了动作对调度结果的影响。在求解作业车间调度问题时,只有一个决策点,此时的动作就是一个JSR,该规则将对所有工序任务进行排序,并从当前就绪任务集合中选择优先级最高的工序。在求解柔性作业车间调度问题时,动作可以是一组JSR和MAR,同时确定最优先的工序和最优先的机床,也可以添加一个约束,利用基于先验知识的优先级分派规则得到一个满足约束的完整解。基于析取图模型的调度分派过程如图18所示。
算法层也称为代理层,其决定了强化学习代理的运行机制,包括强化学习算法库、策略网络以及探索和利用策略。很多强化学习算法都是基于值函数法的,该方法适用于离散动作空间问题,可以将该方法用于进行规则选择的作业车间调度问题;策略梯度法直接参数化策略,在离散和连续动作空间上均有效,可使用该算法训练输出选择下一道工序的概率;演员-评论家算法则综合了值函数法和策略梯度法的优势,演员负责使用策略函数生成动作并与环境交互,评论家使用价值函数负责评估演员的表现,并指导演员下一阶段的动作。因此在算法层构建了包括不同强化学习算法的算法库,可以针对所求解问题的不同特点,从中选择不同的强化学习算法进行状态、动作、奖励、网络、策略等元素的设计;由于调度状态是连续值,如松弛率、工时等,所以状态空间无限大,传统的表格型强化学习将面临维数灾难,因此需要借助神经网络强大的拟合能力来逼近值函数或策略函数,根据强化学习算法和调度状态表达的不同,可以采用不同形式的网络,卷积神经网络可以有效地处理图像,指针网络能够根据输入序列得到输出序列,Actor-critic网络同时输出动作和值函数。强化学习算法根据接收到的状态和奖励,基于梯度下降或上升来优化网络参数;探索和利用策略用于平衡探索和利用,保证在尝试更多动作的同时也充分借鉴已有的知识。在值函数法中通常采用 -贪婪递减策略或考虑精英机制的 -贪婪递减策略,而在策略梯度法和演员-评论家方法中常使用Softmax,根据预测概率输出动作。
当代理训练结束后,就得到了一个最优调度策略,将该策略传递到测试层进行最终的评价。测试层包括状态感知器、动作执行器、事件处理器、测试集和析取图模型。这里的状态感知器和动作执行器与训练层中的类似,不同的是感知后的状态不会再传递给算法层,只需要将状态输入到调度策略中就能得到动作,再交由动作执行器;当机床故障、交货期变更等事件发生后,事件处理器用于处理这些扰动事件,更新调度状态,得到新的调度实例,并构成测试集;测试过程仍然基于析取图模型,如图19所示。

框架通用性
根据以上提出的统一调度框架,其通用性体现在以下几个方面:
- (1) 调度环境生成器可覆盖不同类型的调度问题
当按照参数分布只生成一台机床时,且每个工件仅有一道工序,则可得到单机调度问题;当按照参数分布生成多台机床,每个工件仅有一道工序,各工序可在任意一台机床上加工,则得到并行调度问题;当按照参数分布生成多台机床,每个工件具有相同的工艺路线,且每道工序只能在一台机床上加工,则得到一般流水车间调度问题;当按照参数分布生成多台机床时,每个工件具有相同的工艺路线,且部分工序可在多台机床上加工,则得到具有并行机的流水车间调度问题;当按照参数分布生成多台机床,每个工件的工艺路线不同,且每道工序只能在一台机床上加工,则得到作业车间调度问题;当按照参数分布生成多台机床,每个工件的工艺路线不同,且每道工序可有多台机床加工,则得到柔性作业车间调度问题。因此这部分是训练层、算法层和测试层所共享的。
- (2) 算法层通过算法库实现不同的交互策略
算法层的算法库由各种强化学习算法构成,强化学习算法决定了梯度计算方式,策略网络决定了强化学习的输入和输出,探索和利用策略有利于平衡新知识和已有知识的利用。通过这三个组成部分的有机组合,可实现规则选择、工序选择和交互约束设置,因此算法层是可重用的,用户可以在定义状态、动作、奖励、策略网络、探索和利用策略等元素后,方便地实现新的强化学习算法并丰富算法库,从而实现不同的交互策略和对不同问题的求解。
- (3) 基于析取图模型的通用求解过程
尽管通过参数分布可以生成不同的调度问题,但是这些问题都将基于析取图模型进行求解,而析取图模型对这些问题的表达通用性就决定了求解过程也是通用的,即先将入度为0的工序任务添加到就绪任务集合,然后选择最优先的工序和机床,并将该工序安排在该机床完成负荷的更新,最后将该工序的后置工序添加至就绪任务集合,继续下一次迭代直到就绪任务集合为空。
框架实例化
基于以上框架,可以实例化出针对不同调度问题的求解框架,其中图20为训练时的框架实例化过程(测试时的该过程与之类似,这里不再赘述),其包括了训练层的实例化、调度问题的实例化和算法层的实例化。下面将从这三个不同调度问题介绍具体的实例化过程。
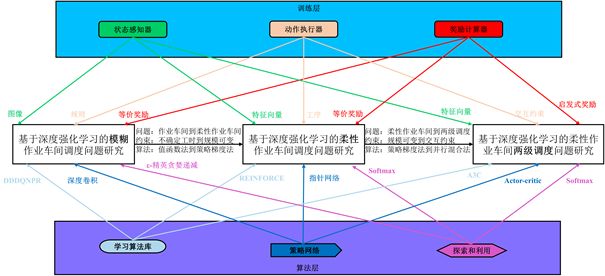
- (1) 模糊作业车间调度问题
调度环境生成器根据工时分布,生成每道工序只有一台机床可加工的作业车间调度问题,该问题以图像的形式输入到深度卷积神经网络中,神经网络根据ε-精英探索递减策略从动作集合中选择一个启发式规则,并根据此规则选择最优先的工件,之后奖励计算器根据设计的等价奖励返回一个瞬时奖励值,图像、动作和瞬时奖励就构成了一条经验数据,再从算法库中选择考虑优先级经验回放的dueling double DQN(DDDQNPR)对数据进行训练,经过一定代数的训练,得到最终的规则选择策略。
- (2) 不同规模的柔性作业车间调度问题
调度环境根据机床数分布、工件数分布、工序数分布、工序可选机床数分布、工时分布,生成每道工序具有多台可选机床的柔性作业车间调度问题,构造表达该问题的特征向量并输入到指针网络中,利用注意力机制从输入序列中选择所对应的工序及其机床,当得到一个完整的调度序列后奖励计算器根据设计的等价奖励返回一个最终奖励值,从算法库中选择策略梯度法REINFORCE进行梯度上升,经过一定代数的训练,得到最终的调度构造策略。
- (3) 具有交互约束的柔性作业车间两级调度问题
调度环境根据交货期因子分布对已有的柔性作业车间调度问题实例进行扰动,从而得到具有不同特征的问题集合,构造这些问题的调度特征向量,并输入到演员-评论家Actor-critic网络中,根据概率输出交互调整,该交互调整以约束的形式添加至调度中,然后基于先验知识快速得到调度解,并根据奖励计算器得到启发式奖励对该交互调整进行评价,特征向量、交互调整和启发式奖励就构成了一条经验数据,从算法库中选择异步并行A3C算法对数据进行训练,经过一定代数的训练,得到最终的调度交互策略。
通过以上可以看出,这三个研究内容是问题、约束和算法三个层面递进的关系,第一个内容仅求解了作业车间调度问题,考虑工时不确定性因素,采用值函数法进行规则选择,第二个内容则进一步考虑了柔性作业车间调度问题,除了工时不确定以外,还考虑了不同规模,采用策略梯度法直接构造调度解,第三个内容则进一步考虑了柔性作业车间两级调度,考虑了加班、外协等交互约束,采用并行的值函数和策略梯度混合算法学习交互策略,并提升训练速度。此外,所有实例化过程均需要重新定义状态、动作、奖励、算法、策略网络、探索和利用策略等元素,在后续章节中将给出这些元素的详细定义,以及实例化后得到的具体调度框架。