itemCF matlab算法,基于物品的协同过滤算法(ItemCF)
物品相似度计算
余弦相似度公式:
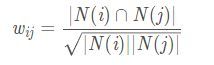
其中
![]() ,
,
![]() 分别表示对物品
分别表示对物品
![]() ,
,
![]() 喜欢的用户数,
喜欢的用户数,
![]() 为同时喜欢
为同时喜欢
![]() 和
和
![]() 的人数。我们这里还是使用漫威英雄举例:假设目前共有5个用户: A、B、C、D、E;共有5个漫威英雄人物:死侍、钢铁侠、美国队长、黑豹、蜘蛛侠。用户与人物之间的爱好程度如下图所示:
的人数。我们这里还是使用漫威英雄举例:假设目前共有5个用户: A、B、C、D、E;共有5个漫威英雄人物:死侍、钢铁侠、美国队长、黑豹、蜘蛛侠。用户与人物之间的爱好程度如下图所示:

共现矩阵,记录了同时爱好 i 和 j 的数量:
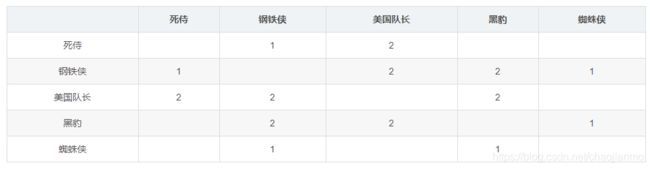
根据余弦相似度公式计算相似度:
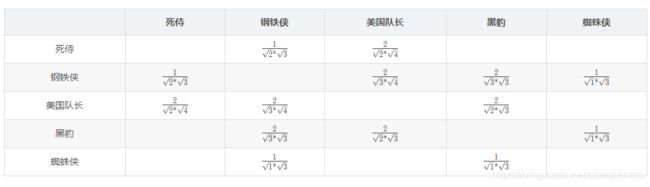
python 实现
import math
class ItemCF:
def __init__(self):
self.user_score_dict = self.initUserScore()
# self.items_sim = self.ItemSimilarity()
self.items_sim = self.ItemSimilarityBest()
# 初始化用户评分数据
def initUserScore(self):
user_score_dict = {
"A": {"a": 3.0, "b": 4.0, "c": 0.0, "d": 3.5, "e": 0.0},
"B": {"a": 4.0, "b": 0.0, "c": 4.5, "d": 0.0, "e": 3.5},
"C": {"a": 0.0, "b": 3.5, "c": 0.0, "d": 0.0, "e": 3.0},
"D": {"a": 0.0, "b": 4.0, "c": 0.0, "d": 3.5, "e": 3.0},
}
return user_score_dict
# 计算item之间的相似度
def ItemSimilarity(self):
itemSim = dict()
# 得到每个物品有多少用户产生过行为
item_user_count = dict()
# 共现矩阵
count = dict()
for user, item in self.user_score_dict.items():
for i in item.keys():
item_user_count.setdefault(i, 0)
if self.user_score_dict[user][i] > 0.0:
item_user_count[i] += 1
for j in item.keys():
count.setdefault(i, {}).setdefault(j, 0)
if (
self.user_score_dict[user][i] > 0.0
and self.user_score_dict[user][j] > 0.0
and i != j
):
count[i][j] += 1
# 共现矩阵 -> 相似度矩阵
for i, related_items in count.items():
itemSim.setdefault(i, dict())
for j, cuv in related_items.items():
itemSim[i].setdefault(j, 0)
itemSim[i][j] = cuv / item_user_count[i]
return itemSim
# 计算item之间的相似度 优化后
def ItemSimilarityBest(self):
itemSim = dict()
# 得到每个物品有多少用户产生过行为
item_user_count = dict()
# 共现矩阵
count = dict()
for user, item in self.user_score_dict.items():
for i in item.keys():
item_user_count.setdefault(i, 0)
if self.user_score_dict[user][i] > 0.0:
item_user_count[i] += 1
for j in item.keys():
count.setdefault(i, {}).setdefault(j, 0)
if (
self.user_score_dict[user][i] > 0.0
and self.user_score_dict[user][j] > 0.0
and i != j
):
count[i][j] += 1
# 共现矩阵 -> 相似度矩阵
for i, related_items in count.items():
itemSim.setdefault(i, dict())
for j, cuv in related_items.items():
itemSim[i].setdefault(j, 0)
itemSim[i][j] = cuv / math.sqrt(item_user_count[i] * item_user_count[j])
return itemSim
# 预测用户对item的评分
def preUserItemScore(self, userA, item):
score = 0.0
for item1 in self.items_sim[item].keys():
if item1 != item:
score += (
self.items_sim[item][item1] * self.user_score_dict[userA][item1]
)
return score
# 为用户推荐物品
def recommend(self, userA):
# 计算userA 未评分item的可能评分
user_item_score_dict = dict()
for item in self.user_score_dict[userA].keys():
# if self.user_score_dict[userA][item] <= 0:
user_item_score_dict[item] = self.preUserItemScore(userA, item)
return user_item_score_dict
if __name__ == "__main__":
ib = ItemCF()
print(ib.recommend("C"))