kettle数据同步完善版
kettle实现数据增量同步完善版
前言
前段时间有记录一次使用kettle实现数据同步的操作,内容包括kettle的安装配置job的创建translate的创建等。
当时做的时候使用使用的是写死的时间点(也就是每次同步的时候都会从这个时间点开始查询数据再做对比,并完成数据的同步更新到target数据源中)。当然开始再数据量小并且使用主键ID做数据对比的情况下,数据同步的速度还是非常快的,
但是随着数据的不断增加和不同的业务需求变更,有些业务我们不能使用ID来进行数据的对比,这个时候数据量特别大的情况下就会明显感觉到数据同步的速度吃力,再加上我需要开VPN从客户生产环境上同步测试环境,由于网速的限制和服务器硬件的因素导致后期同步速度非常慢。
原本以为就是为了同步一些数据够用就行了,但是因为需求需要每天实时更新数据,所以不得不对当时同步的方式进行“升级”。
摘要
本次记录主要是在上一次的方法基础上进行升级改造的,所以本次将不再详细记录kettle的安装配置job的创建translate的创建等。
本次使用环境如下
数据源:
source 数据源 : MySQL ;
target 数据源 :MySQL;
kettle版本:windows 版 7.0
完成内容:
1 通过设置更新时间戳完成数据的实时增量同步;
注意:为了记录明确易读,本次使用简单的demo进行记录,直接记录核心逻辑,如果有其他业务需求可以在此基础上进行升级改造即可。
1 核心逻辑
如何完成近实时的增量同步,我们首先需要考虑两个关键因素:近实时、增量。
近实时:
其实很容易实现,我们可以根据业务需求让kettle 定时循环去执行我们的job即可,比如源数据某一张表的数据是每一个小时增加若干条数据,那么我们就可以设置循环的频率为 30分钟/次 这样 在业务上其实就完成了近实时的同步(不排除在同步的工程中源数据表正好有有新的数据新增进来,但是一般不会出现这种情况,如果想要避免,可以将循环间隔再次缩短即可)
增量:
其实增量已经很明显了,就是上次已经同步过的数据,job第二次执行同步的时候我们只需要同步源数据表新增的数据即可,那么想要实现这种增量新增,我们只能利用时间戳,来进行过滤;
1.1 基于逻辑分析的实现概览
上面分析了近实时和增量,接下来就是我们针对本次demo的具体实现了,先来看一下实现概览:

上图是我们最终的一个job:
1 点击开始
2 开始后,我们需要先去查询上次同步的时间戳,这个时间戳我们需要进行持久化存储到我们的target数据源时间戳表里,我们在同步实现可以手动创建一条时间戳,作为我们开始同步的数据日期,当第一次执行的时候就是从创建的时间戳以及之后的数据进行同步。并且我们获取时间戳的时候需要将查询出来的时间戳设置为全局变量,因为后面要使用这个时间戳;
3 根据时间戳去删除当前时间戳和时间戳之后的数据,这样做的目的是回滚一段时间的数据,避免我们漏数据。
4 数据同步,其实就是我们数据同步的核心逻辑,我们需要建立一个translate 来实现具体逻辑;(转换里面一定是根据时间戳进行查询的数据,就是这里我们用到了时间戳,它也是增量同步的核心所在)
5 数据同步结束,我们就需要将target中同步的数据根据时间排序取出最新的时间同时更新时间戳,以便下次job执行的时候使用最新的时间戳;
6 成功。
2 准备工作
开始之前先准备一下source和target数据源牵扯的表和测试数据
2.1 target数据源时间戳表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tel_time_temp
-- ----------------------------
DROP TABLE IF EXISTS `tel_time_temp`;
CREATE TABLE `tel_time_temp` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`etl_type` bigint(20) NULL DEFAULT NULL COMMENT '时间戳业务类型(用于明确是哪一个job的时间戳)',
`temp_time` datetime NULL DEFAULT NULL COMMENT '时间戳',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
-- ----------------------------
-- Records of tel_time_temp
-- ----------------------------
INSERT INTO `tel_time_temp` VALUES (1, 1, '2022-01-29 00:00:00');
SET FOREIGN_KEY_CHECKS = 1;
2.2 source 数据源表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tab_source
-- ----------------------------
DROP TABLE IF EXISTS `tab_source`;
CREATE TABLE `tab_source` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`tm` datetime NULL DEFAULT NULL COMMENT '监测时间',
`drp` decimal(10, 3) NULL DEFAULT NULL COMMENT '降雨量',
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',
`update_time` datetime NULL DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of tab_source
-- ----------------------------
INSERT INTO `tab_source` VALUES (1, '2022-01-28 15:38:49', 10.000, '2022-01-28 15:39:01', '2022-01-28 15:39:06');
INSERT INTO `tab_source` VALUES (2, '2022-01-28 15:39:16', 12.300, '2022-01-28 15:39:22', '2022-01-28 15:39:24');
INSERT INTO `tab_source` VALUES (3, '2022-01-28 15:39:37', 15.300, '2022-01-28 15:39:43', '2022-01-28 15:39:45');
INSERT INTO `tab_source` VALUES (4, '2022-01-28 15:40:08', 15.360, '2022-01-28 15:40:14', '2022-01-28 15:40:16');
INSERT INTO `tab_source` VALUES (5, '2022-01-28 15:40:24', 14.230, '2022-01-28 15:40:30', '2022-01-28 15:40:32');
INSERT INTO `tab_source` VALUES (6, '2022-01-29 20:45:41', 66.000, '2022-01-29 20:45:48', '2022-01-29 20:45:51');
INSERT INTO `tab_source` VALUES (7, '2022-01-29 20:46:55', 88.000, '2022-01-29 20:46:58', '2022-01-29 20:47:02');
SET FOREIGN_KEY_CHECKS = 1;
2.3 target 数据源表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tab_target
-- ----------------------------
DROP TABLE IF EXISTS `tab_target`;
CREATE TABLE `tab_target` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`tm` datetime NULL DEFAULT NULL COMMENT '监测时间',
`drp` decimal(10, 3) NULL DEFAULT NULL COMMENT '降雨量',
`update_time` datetime NULL DEFAULT NULL COMMENT '更新时间',
`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
3 获取时间戳
获取时间戳中有两个操作,一个是从target数据源的时间戳表中查询时间戳,另一个是将时间戳更新到全局变量中存储起来备用。
所以我们可以建立一个转换translate来完成这样两个操作
如图

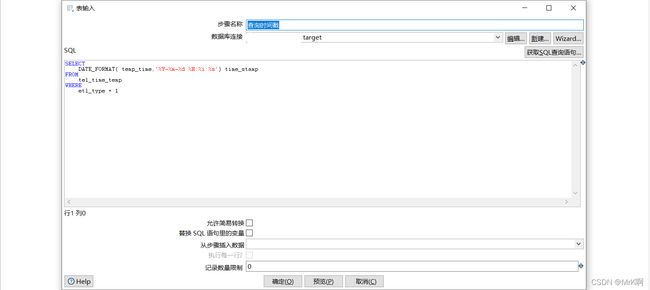
3.1 查询时间戳
创建表输入从target数据源的时间戳表中查询上次同步的时间戳。
注意我们尽量将tm转换成指定格式的字符串,方便后期比较,如果不同的数据库类型直接使用时间进行比较可能会出现问题,导致同步数据失败或者同步到重复的数据。
3.2将时间戳更新到全局变量
将时间戳设置为全局变量
变量活动类型可以为该变量设置四种有效活动范围,分别是JVM、该Job、父Job和祖父Job(demo中使用的是该job)

4 删除时间戳及以后数据
在job中创建一个sql脚本来完成即可

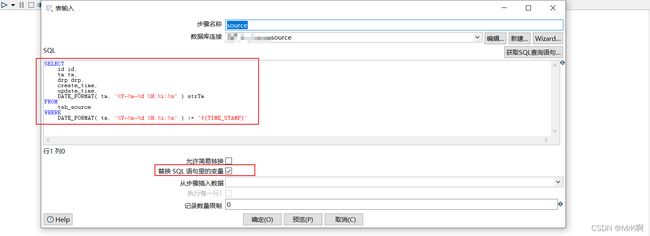
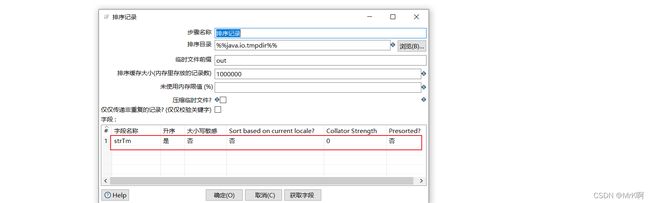
5 数据同步
这里的数据同步就不再具体记录如何创建了,具体可参考kettle的安装配置job的创建translate的创建等。
下面列出部分截图:


6 更新时间戳
更新时间戳我们只需要在job中田间SQL脚本即可。
set @new_etl_start_time_stamp =(select tm FROM tab_target ORDER BY tm DESC LIMIT 1);
update tel_time_temp set temp_time=@new_etl_start_time_stamp where etl_type =1;

7 执行看效果
我们设置job每一分钟执行一次,通过第一次执行前后看时间戳表和target表中数据变化判断同步是否成功,然后source表中新增一条数据,看一分钟后是否再一次更新时间戳表和target表。
执行前:时间戳表和target表数据如下


执行job 并打印日志
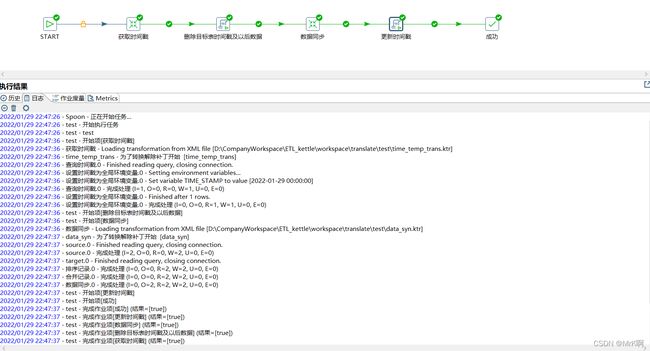
执行后查看时间戳和target表数据变化:可以看到正好是source数据源中时间戳之后的两条数据


接下来source数据源表中新增一条最新数据,再次执行看一下时间戳和数据变化
图例可以看到时间戳和数据都已经发生变化。
INSERT INTO `source`.`tab_source` (`tm`, `drp`, `create_time`, `update_time`) VALUES ('2022-01-30 00:00:00', 99.000, '2022-01-30 00:00:00', '2022-01-30 00:00:00');


8 结束语
记录到此结束。对于后端开发来说,接触最多的往往不是代码,很多情况下是对业务数据的处理。