基于深度学习算法和传统立体匹配算法的双目立体视觉
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
01 立体视觉是什么?
在开始之前,我相信很多站友都会有这个疑问,所以我想先在这里做一下简要的介绍,以方便大家快速地了解这个项目。我们知道,人类通过眼睛感知世界、获取信息。人类获取信息的方式有很多 种,可通过眼睛、耳朵、触觉、嗅觉、味觉等,但我们接受到的绝大部分信息都是通过视觉的方式获取到的。由此可见,视觉系统在人类的生存、生产、发展中起到了极其重要的作用。随着计算机技术、智能机器人等的广泛研究与应用,不少科学家尝试将人类视觉系统功能赋予机器。让机器获取与人类一般的视觉能力,是许多科研工作者长期以来的追求。目前,虽然还不能够使机器获得与人类一模一样的视觉感知能力与认知能力,但自上世纪中叶以来,各种视觉技术理论与图像处理技术得到了飞速的发展,我们正朝着这一目标不断前进。

立体视觉是计算机视觉的重要组成部分,而双目立体视觉又是立体视觉的一个重要分支。它是基于两幅图像的,通过模拟人眼视觉的方式,由两个视点对同一个物体进行观察,具体是由不同位置的两台相机(或一台相机经过旋转和移动)对同一场景进行拍摄,然后通过三角测量的原理来计算空间点在两幅图像中像素间的视差,根据视差来恢复目标物体的深度信息,最后可以根据深度信息来恢复物体的三维形状。

作为一个完整的计算机视觉三维重建系统必须包含以下几个部分:图像采集、图像预处理、相机标定、特征点提取和立体匹配、深度信息计算、三维坐标计算以及后处理等。比较关键的技术有相机标定技术、图像立体匹配以及空间点的三维坐标计算三项。

02 立体视觉原理
立体视觉原理示意图如下图所示,右眼能看到被视物体的右侧,左眼能看到被视物体的左侧,左右眼视网膜上形成2副存在视差的图像,经大脑融合处理后,大脑根据视差判断物体的空间位置关系,使人产生立体视觉。
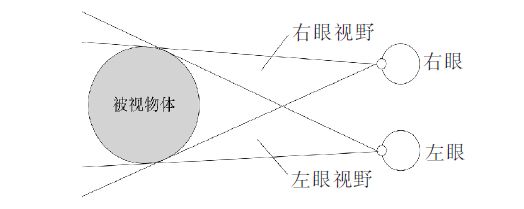
在机器视觉中,以仿生学原理获取视差图像,人类立体视觉获取的视差以角度表示,计算机获取的视差大小则以2 副图像之间的像素坐标差值表示。机器视觉中,需通过3D显示设备呈现立体景象,根据物体远近表现的视差,分为正视差、负视差和零视差,并以此形成立体感。
03 左右视图
左右视图即来自于左右眼睛或摄像头的图像,我们网路的训练用到的左右视图是来自Middlebury数据库中供立体匹配算法研究的一组参考图像。

04 深度学习算法
我们采用了基于全卷积神经网络的立体匹配,利用大量的图像对与真实视差图像进行训练,学习图像对到视差图的直接映射。视差平滑假设,然后解决一个优化问题。卷积神经网络可以进行端到端的学习,立体匹配则要求进行像素级别的视差计算,一般的卷积神经网络的无结构输出结果无法满足要求。我们通过全卷积神经网络可以对任意尺寸的图像进行输入,进行端到端的学习,进行像素级别的预测,全卷积网络结构采用双塔式网络结构,去掉全连接层,输入为同一场景对应的两张的图像,输出为视差图。
05 网络结构图
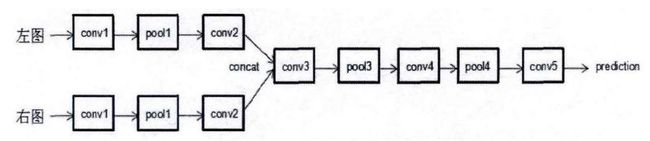
我们使用全卷积神经网络进行光流预测,基于全卷积神经网络的立体匹配网络结构采用如图所示,整个网络采用双塔式网络结构。因为双目立体匹配输入为两张图像,此网络输入具有两个分支,输入分别为参考图像r与匹配图像m,r与m是同一场景不同视角的两幅图像,再分别经过三层卷积(具体层数可以进一步调节)与池化层变换进行特征提取,再把两个分支的特征图首尾相接进行聚合,形成双塔式结构。把聚合的特征图继续执行卷积与池化操作,进行更高层次的抽象语义特征提取,最后结合高层的语义信息与低层的位置信息进行提炼(refinement ),既可以获取语义信息,又可以保持更好的空间结构,获取更加精准的预测,符合人脑生物特性,通过这个双塔式全卷机神经网络,进行像素级别的预测,可以直接进行图像对到视差图的映射。
06 传统立体匹配算法
Census 变换在实际场景中,造成亮度差异的原因有很多,如由于左右摄像机不同的视角接受到的光强不一致,摄像机增益、电平可能存在差异,以及图像采集不同通道的噪声不同等,cencus方法保留了窗口中像素的位置特征,并且对亮度偏差较为鲁棒,简单讲就是能够减少光照差异引起的误匹配。
在视图中选取任一点,以该点为中心划出一个例如3 × 3 的矩形,矩形中除中心点之外的每一点都与中心点进行比较,灰度值小于中心点即记为1,灰度大于中心点的则记为0,以所得长度为 8 的只有 0 和 1 的序列作为该中心点的 census 序列,即 中心像素的灰度值被census 序列替换。经过census变换后的图像使用 汉明距离计算相似度,所谓图像匹配就是在视差图中找出与参考像素点相似度最高的点,而汉明距正是视差图像素与参考像素相似度的度量。实现原理
对于欲求取视差的左右视图,要比较两个视图中两点的相似度, 可将此两点census值逐位进行异或运算,然后计算结果为1 的个数,记为此两点之间的汉明值,汉明值是两点间相似度的一种体现,汉明值愈小,两点相似度愈大实现算法时先异或再统计1的个数即可,汉明距越小即相似度越高。具体操作
07 结果误差率
我们深度学习算法的实验结果的最终误差率只有7.25%!!!


08 三维重建的结果
以下是我们深度学习算法最终的实验结果:

09 算法源码
由于代码文件过大,所以在此呢,站长就放上整个代码文件的截图哈。
深度学习算法源码截图
传统立体算法源码截图
1、DP算法

2、Census算法
3、SAD算法

巨人的肩膀
[1] 张克兵.基于双目视觉的特征目标三维信息构建[D].哈尔滨:哈尔滨工业大学,2012.
[2] 马颂德,张正友.计算机视觉-计算理论与算法基础[M].北京:科学出版社,2003:1-21.
[3] 陈拓.基于卷积神经网络的立体匹配技术研究[D].浙江:浙江大学,2017.
[4] 戴杰.基于深度学习的立体匹配研究[D].北京:北京邮电大学,2016.
[5] 刘云海,白鹏.一种基于卷积神经网络的双目立体匹配方法:中国,105956597A[P].2016.
[6] Haeusler R, Nair R, Kondermann D. Ensemble learning for confidence measuresin stereo vision[C]//2013 IEEE Conference on Computer Vision and PatternRecognition (CVPR). IEEE ComputerSociety, 2013:5695-5703.
[7] Lecun Y, Boser B, Denker JS,et al. Backpropagation applied to handwrittenZip code recognition[J]. NeuralComputation, 1989, 1(4):541-551.
[8] 赵茏菲. 双目立体视觉中局部立体匹配算法研究[D].河北:河北大学,2015.
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

