Seaborn 入门
一、Seanborn
Seaborn是基于Matplotlib的Python数据可视化库,对matplotlib进行二次封装而成。它提供了一个高级界面,用于绘制引人入胜且内容丰富的统计图形,只是在Matplotlib上进行了更高级的API封装,从而使作图更加容易。
Seaborn是针对统计绘图的,能满足数据分析90%的绘图需求,需要复杂的自定义图形还需要使用到Matplotlib
Seaborn解决Matplotlib面临的两个主要问题
- 默认Matplotlib参数
- 使用Data FrameSeaborn
Seaborn官网:http://seaborn.pydata.org/
二、Seaborn特点
- 绘图接口更为集成,可通过少量参数设置实现大量封装绘图
- 多数图表具有统计学含义,例如分布、关系、统计、回归等
- 对Pandas和Numpy数据类型支持非常友好
- 风格设置更为多样,例如风格、绘图环境和颜色配置等
三、Seaborn库

四、Seaborn 环境配置
安装:pip install seaborn
五、 Seaborn 导入数据
1、从导入Pandas开始,Pandas是用于管理关系数据集, Seaborn在处理DataFrames时非常方便,DataFrames是用于数据分析最广泛使用的数据结构。
# Pandas for managing datasets import pandas as pd
2、导入Matplotlib库
# Matplotlib for additional customization from matplotlib import pyplot as plt
3、导入Seaborn库
import seaborn as sns
加载内置数据集:https://github.com/mwaskom/seaborn-data
4、导入数据框
加载所需的数据集load_dataset()
import seaborn as sns
#加载数据
tips=sns.load_dataset('tips')
# tips
# 计算小费百分比
tips['tip_pct']=tips['tip']/(tips['total_bill']-tips['tip'])
#显示前5条
tips.head()输出-

要查看Seaborn库中的所有可用数据集,可以将以下命令与 get_dataset_names()函数一起使用
import seaborn as sns
import matplotlib.pyplot as plt
#设置中文
plt.rcParams['font.sans-serif']='Microsoft YaHei'
plt.rcParams['font.size']=14
#必须去除警告信息
import warnings # 去除部分警告信息
warnings.filterwarnings('ignore')
#seaborn中有内置的数据集,获得所有的名字(必须有网络)
names=sns.get_dataset_names()
print(names)输出的数据集列表
六、Seaborn - 可视化数据
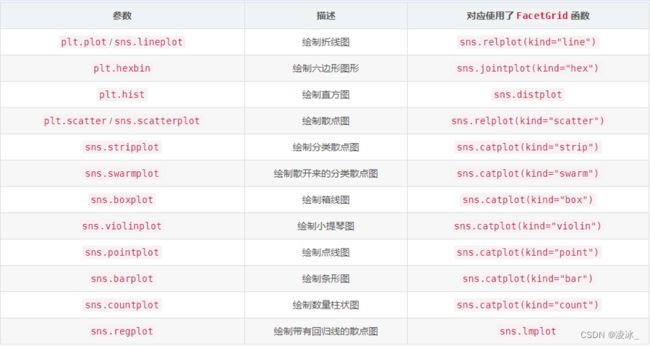
1、条形图
官网:http://seaborn.pydata.org/generated/seaborn.barplot.html
seaborn.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=
, ci=95, n_boot=1000, units=None, orient=None, color=None, palette=None, saturation=0.75, errcolor='.26', errwidth=None, capsize=None, dodge=True, ax=None, **kwargs) 参数:
data: pandas.dataframe对象
x:绘图的x轴变量
y:绘图的y轴变量
hue:区分维度,不同类别的曲线添加不同颜色
orient: “v” | “h”, 可选图的方向(垂直或水平)
estimator:用于估计每个分类箱内的统计函数,默认为mean。当然你也可以设置estimator=np.median/np.std/np.var……
order:设置特征值的顺序,例如:order=[‘Sat’,‘Sun’];
ci:允许的误差的范围(控制误差棒的百分比,在0-100之间),若填写"sd",则用标准误差(默认为95),也可设置ci=None;
capsize:设置误差棒帽条(上下两根横线)的宽度,float;
errcolor:表示置信区间的线条的颜色;
errwidth:float,设置误差条线(和帽)的厚度。
注意:x、y和hue均为源于data中的某一列值
#设置画布
sns.set(rc={'figure.figsize':(4,3)})
#条形图
sns.barplot(data=tips,x='tip_pct',y='day')
# 柱子的值表示tip_pct的平均值,黑线表示%95的置信区间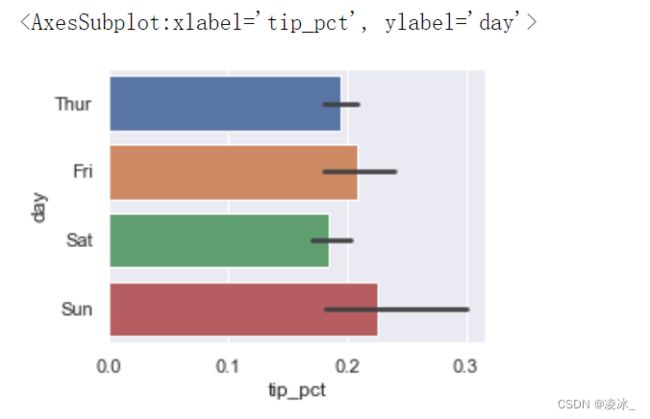
import numpy as np
#设置画布
sns.set(rc={'figure.figsize':(10,5)})
#条形图
sns.barplot(data=tips,x='tip_pct',y='day',hue='sex',estimator=np.median,capsize=0.2,errcolor='c')
# 直方图是一种条形图,用于给出频率的离散显示。数据点被分成离散的,均匀间隔的箱,并且绘制每个箱中数据点的数量。
import seaborn as sns
#加载数据
tips=sns.load_dataset('tips')
#tips.head()
#设置画布
sns.set(rc={'figure.figsize':(4,3)})
#小费比例
tips['tip_pct']=tips['tip']/(tips['total_bill']-tips['tip'])
# 使用之前的小费数据制作小费占总费用百分比的直方图
tips['tip_pct'].plot.hist(bins=50) 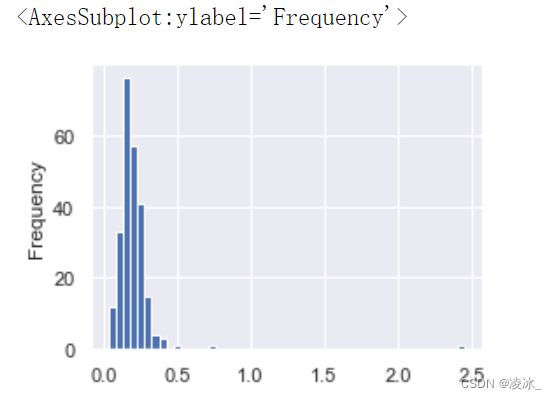
# 密度图是一种和直方图相关的图表类型,它通过计算可能产生观测数据的连续概率分布估计而产生。
# 通常的做法是将这种分布近似为’内核’的混合,也就是像正态分布那样简单的分布。
# 因此密度图也称为内核密度估计图
tips['tip_pct'].plot.density() 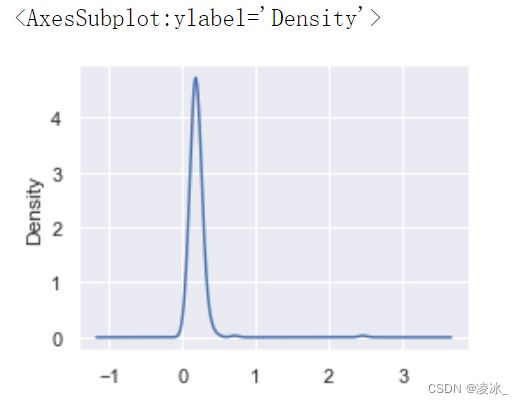
2、直方图
官网:http://seaborn.pydata.org/generated/seaborn.displot.html
distplot主要功能是绘制单变量的直方图,且还可以在直方图的基础上施加kdeplot和rugplot的部分内容,是一个功能非常强大且实用的函数
seaborn.displot(data=None, *, x=None, y=None, hue=None, row=None, col=None, weights=None, kind='hist', rug=False, rug_kws=None, log_scale=None, legend=True, palette=None, hue_order=None, hue_norm=None, color=None, col_wrap=None, row_order=None, col_order=None, height=5, aspect=1, facet_kws=None, **kwargs)
参数:
data: pandas.dataframe对象
x:绘图的x轴变量
y:绘图的y轴变量
hue:区分维度,不同类别的曲线添加不同颜色 bins:int型变量,用于确定直方图中显示直方的数量,默认为None,这时bins的具体个数由Freedman-Diaconis准则来确定
hist:bool型变量,控制是否绘制直方图,默认为True
kde:bool型变量,控制是否绘制核密度估计曲线,默认为True
rug:bool型变量,控制是否绘制对应rugplot的部分,默认为False
fit:传入scipy.stats中的分布类型,用于在观察变量上抽取相关统计特征来强行拟合指定的分布,下文的例子中会有具体说明,默认为None,即不进行拟合 hist_kws,kde_kws,rug_kws:这几个变量都接受字典形式的输入,键值对分别对应各自原生函数中的参数名称与参数值,在下文中会有示例
color:用于控制除了fit部分拟合出的曲线之外的所有对象的色彩
vertical:bool型,控制是否颠倒x-y轴,默认为False,即不颠倒
norm_hist:bool型变量,用于控制直方图高度代表的意义,为True直方图高度表示对应的密度,为False时代表的是对应的直方区间内记录值个数,默认为False
label:控制图像中的图例标签显示内容
使用distplot方法可以同时绘制直方图和密度图
import numpy as np
import pandas as pd
#使用distplot方法可以同时绘制直方图和密度图
c1 = np.random.normal(0, 1, size = 200)
c2 = np.random.normal(10, 2, size = 200)
#一维数据
values = pd.Series(np.concatenate([c1,c2]))
#bins:int或list,控制直方图的个数100
sns.distplot(values,bins = 100,color = 'r') 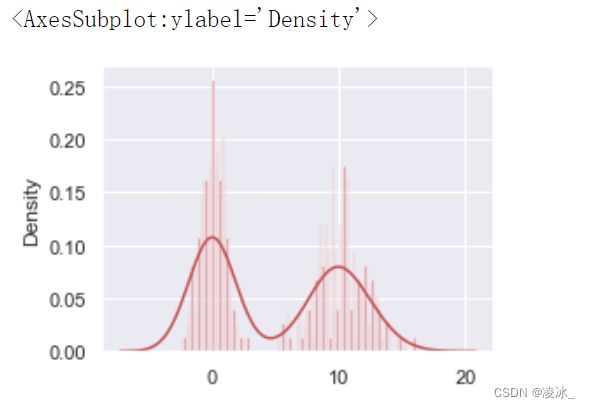
import matplotlib.pyplot as plt
#数据
x= np.random.normal(0, 1, size = 100)
#创建一个一行三列的画布
fig,axes=plt.subplots(1,3)
# hist和kde参数调节是否显示直方图及核密度估计(默认hist,kde均为True)
sns.distplot(x,ax=axes[0]) #左图
sns.distplot(x,hist=False,ax=axes[1]) #中图
sns.distplot(x,kde=False,ax=axes[2]) #右图 
import seaborn as sns
#密方图
#加载数据
penguins=sns.load_dataset('penguins')
#显示前5条
penguins.head()
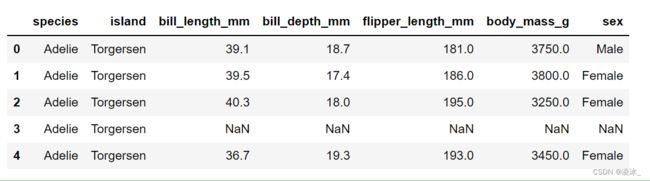
sns.displot(data=penguins,x='bill_depth_mm')
sns.displot(data=penguins,x='bill_depth_mm',kind='kde')

sns.displot(data=penguins,x='bill_depth_mm',kind='ecdf')

sns.displot(data=penguins,x='bill_depth_mm',kde=True)
sns.displot(data=penguins,x='bill_depth_mm',y='flipper_length_mm')

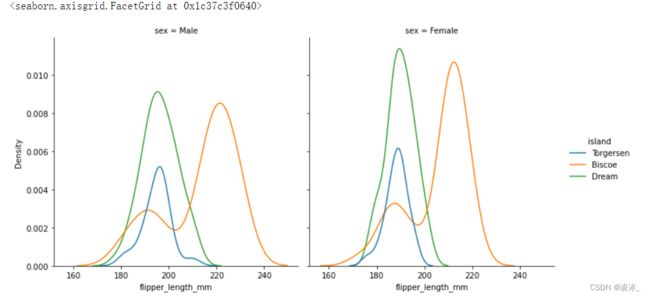
sns.displot(data=penguins, x="flipper_length_mm", hue="island", multiple="stack")

sns.displot(data=penguins, x="flipper_length_mm", hue="island", col="sex", kind="kde")