主动学习(Active Learning,AL)
记录学习过程,简单介绍一下对主动学习的理解
文章目录
- 一、为什么要使用主动学习?
- 二、主动学习的步骤
-
- 收集数据&选取模型
- 训练模型
- 判断精度是否达到要求
- 定义查询策略
- 代码流程
- 其他
一、为什么要使用主动学习?
降低成本
针对有监督的学习任务,存在标记成本较为昂贵且标记难以大量获取的问题。
在此问题背景下,主动学习(Active Learning, AL)尝试通过选择性的标记较少数据而训练出表现较好的模型。
例如,此时我们有大量的猫和狗的数据,假设人为标记他们的类别是成本非常高的事情,这时需要用到主动学习从中挑选部分数据对他们进行标注以节约成本,用主动模型选取出的标注数据训练的模型比随机选取出的相同数量的标注数据训练的模型精度更高。
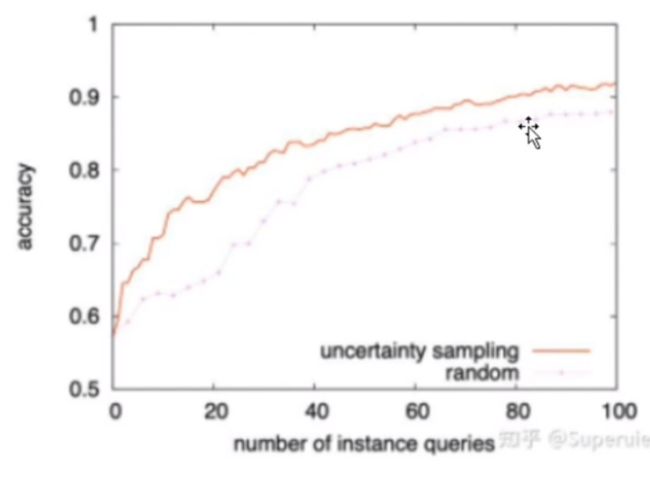
在数据量相同的情况下,利用主动学习选取的样本训练出的模型比随机选取的模型训练处的模型表现得更好。
二、主动学习的步骤
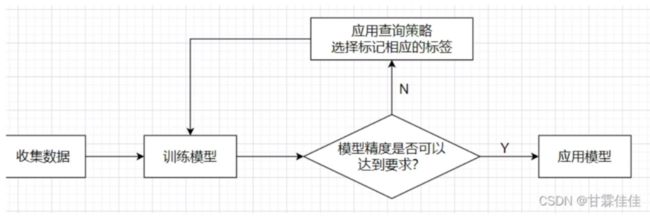
主动学习的关键是你选择的模型、使用的不确定性度量以及应用于请求标注的查询策略。
收集数据&选取模型
开始先选择一定数量的数据进行标注,选取我们需要训练的模型(比如逻辑回归模型)。
训练模型
将标注好的数据放入模型中进行训练,此时精度不会很高。
判断精度是否达到要求
若精度达到要求(比如99%),则表示模型以及训练好,可以应用。
若精度没有达到要求(比如只有12%),则表示模型未被训练好,这是需要利用主动学习选取对模型精度的提高最有用的数据进行人工标注。
定义查询策略
包括度量预测的不确定度和应用于请求标注的查询策略,返回策略选择出的需要标注的数据,进行人工标注,转至第2步。
查询策略决定了哪些样本是值得标记的,这样可以大大节约我们的标记成本。
def custom_query_strategy(classifer, X):
utility = utility_measure(classifer, X) #度量预测的不确定度(选择的依据)
query_idx = select_instances(utility) #应用于请求标注的查询策略
return query_idx,X[query_idx]
查询策略的灵魂就是效用函数
代码流程
"""
Active regression example with Gaussian processes.
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import WhiteKernel, RBF
from modAL.models import ActiveLearner
# query strategy for regression
def GP_regression_std(regressor, X):
_, std = regressor.predict(X, return_std=True)
return np.argmax(std)
# generating the data
X = np.random.choice(np.linspace(0, 20, 10000), size=200, replace=False).reshape(-1, 1)
y = np.sin(X) + np.random.normal(scale=0.3, size=X.shape)
# assembling initial training set
n_initial = 5
initial_idx = np.random.choice(range(len(X)), size=n_initial, replace=False)
X_initial, y_initial = X[initial_idx], y[initial_idx]
# defining the kernel for the Gaussian process
kernel = RBF(length_scale=1.0, length_scale_bounds=(1e-2, 1e3)) \
+ WhiteKernel(noise_level=1, noise_level_bounds=(1e-10, 1e+1))
# initializing the active learner
regressor = ActiveLearner(
estimator=GaussianProcessRegressor(kernel=kernel),
query_strategy=GP_regression_std,
X_training=X_initial.reshape(-1, 1), y_training=y_initial.reshape(-1, 1)
)
# plotting the initial estimation
with plt.style.context('seaborn-white'):
plt.figure(figsize=(14, 7))
x = np.linspace(0, 20, 1000)
pred, std = regressor.predict(x.reshape(-1,1), return_std=True)
plt.plot(x, pred)
plt.fill_between(x, pred.reshape(-1, )-std, pred.reshape(-1, )+std, alpha=0.2)
plt.scatter(X, y, c='k')
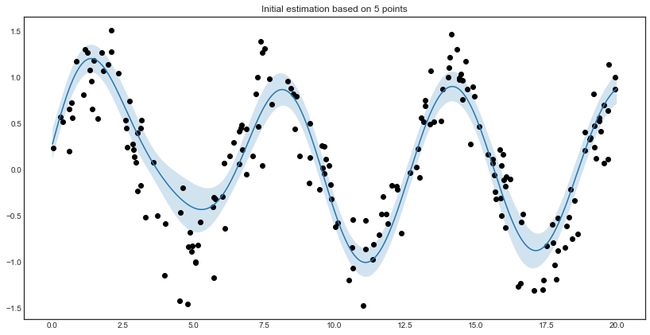
plt.title('Initial estimation based on %d points' % n_initial)
plt.show()
# active learning
n_queries = 10
for idx in range(n_queries):
query_idx, query_instance = regressor.query(X)
regressor.teach(X[query_idx].reshape(1, -1), y[query_idx].reshape(1, -1))
# plotting after active learning
with plt.style.context('seaborn-white'):
plt.figure(figsize=(14, 7))
x = np.linspace(0, 20, 1000)
pred, std = regressor.predict(x.reshape(-1,1), return_std=True)
plt.plot(x, pred)
plt.fill_between(x, pred.reshape(-1, )-std, pred.reshape(-1, )+std, alpha=0.2)
plt.scatter(X, y, c='k')
plt.title('Estimation after %d queries' % n_queries)
plt.show()
使用主动学习从15个样本中预测1000个样本的走势。
具体ipynb文件见作者仓库
其他
代码示例
这是github上的,里面有很多代码示例,其中就包括文章里的
conda activate pytorch
pip install --user modAL