第三章:PyTorch的主要组成模块
文章目录
-
- 第三章:PyTorch的主要组成模块
-
- 3.1 完成深度学习的必要部分
- 3.2 基本配置
-
- 3.2.1 导包的方式
- 3.2.2 超参数设置
- 3.3 数据读入
-
- 3.3.1 Dataset类
- 3.3.1 DataLoader
- 3.4 模型构建
-
- 3.4.1 神经网络的构造
- 3.4.2 神经网络中常见的层
- 3.4.3 模型示例
- 3.5 模型初始化
-
- 3.5.1 torch.nn.init内容
- 3.5.2 torch.nn.init使用
- 3.5.3 初始化函数的封装
- 3.6 损失函数
-
- 3.6.1 二分类交叉熵损失函数
- 3.6.2 交叉熵损失函数
- 3.6.3 L1损失函数
- 3.6.4 MSE损失函数
- 3.6.5 平滑L1 (Smooth L1)损失函数
- 3.6.6 目标泊松分布的负对数似然损失
- 3.6.7 KL散度
- 3.6.8 MarginRankingLoss
- 3.6.9 多标签边界损失函数
- 3.6.10 二分类损失函数
- 3.6.11 多分类的折页损失
- 3.6.12 三元组损失
- 3.6.13 HingEmbeddingLoss
- 3.6.14 余弦相似度
- 3.6.15 CTC损失函数
- 3.7 训练和评估
-
- 3.7.1 设置模型的状态
- 3.8 可视化
- 3.9 Pytorch优化器
-
- 3.9.1 Pytorch提供的优化器
- 3.9.2`Optimizer`的其他方法
- 3.9.3 实际操作
第三章:PyTorch的主要组成模块
3.1 完成深度学习的必要部分
- 数据进行预处理,同时划分训练集和测试集
- 接下来选择模型(深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来)
- 设定损失函数和优化方法(因此损失函数和优化器要能够保证反向传播能够在用户自行定义的模型结构上实现),以及对应的超参数
- 最后用模型去拟合训练集数据,并在验证集/测试集上计算模型表现。
深度学习中训练和验证过程最大的特点在于读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
3.2 基本配置
常见的包有os、numpy等,此外还需要调用PyTorch自身一些模块便于灵活使用,比如torch、torch.nn、torch.utils.data.Dataset、torch.utils.data.DataLoader、torch.optimizer等等。
3.2.1 导包的方式
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer
同时还有一些坑能用上的包,表格处理:pandas;视觉:cv2;可视化:matplotlib、seaborn;下游分析和指标计算:sklearn
3.2.2 超参数设置
- batch size
- 初始学习率(初始)
- 训练次数(max_epochs)
batch_size = 16
# 批次的大小
lr = 1e-4
# 优化器的学习率
max_epochs = 100
- GPU配置
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
还会有一些其他模块或用户自定义模块会用到的参数,有需要也可以在一开始进行设置。
3.3 数据读入
PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
3.3.1 Dataset类
定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
__init__: 用于向类中传入外部参数,同时定义样本集__getitem__: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据__len__: 用于返回数据集的样本数
自己定义Dataset类:
class MyDataset(Dataset):
def __init__(self, data_dir, info_csv, image_list, transform=None):
"""
Args:
data_dir: path to image directory.
info_csv: path to the csv file containing image indexes
with corresponding labels.
image_list: path to the txt file contains image names to training/validation set
transform: optional transform to be applied on a sample.
"""
label_info = pd.read_csv(info_csv)
image_file = open(image_list).readlines()
self.data_dir = data_dir
self.image_file = image_file
self.label_info = label_info
self.transform = transform
def __getitem__(self, index):
"""
Args:
index: the index of item
Returns:
image and its labels
"""
image_name = self.image_file[index].strip('\n')
raw_label = self.label_info.loc[self.label_info['Image_index'] == image_name]
label = raw_label.iloc[:,0]
image_name = os.path.join(self.data_dir, image_name)
image = Image.open(image_name).convert('RGB')
if self.transform is not None:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.image_file)
3.3.1 DataLoader
构建好Dataset后,就可以使用DataLoader来按批次读入数据了
from torch.utils.data import DataLoader
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, num_workers=4, shuffle=False)
- batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数
- num_workers:有多少个进程用于读取数据
- shuffle:是否将读入的数据打乱
- drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
其中PyTorch中的DataLoader的读取可以使用next和iter来完成
images, labels = next(iter(val_loader))
3.4 模型构建
PyTorch中神经网络构造一般是基于 Module 类的模型来完成的,它让模型构造更加灵活。
3.4.1 神经网络的构造
Module 类是所有神经⽹网络模块的基类,其中Module 类的 init 函数和 forward 函数分别用于创建模型参数和定义前向计算。
以 MLP 类的重载为例
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
以上的 MLP 类中⽆须定义反向传播函数。系统将通过⾃动求梯度⽽自动⽣成反向传播所需的 backward 函数。
可以实例化 MLP 类得到模型变量 net ,初始化 net 并传入输⼊数据 X 做一次前向计算。

net(X) 会调用 MLP 继承⾃自 Module 类的 call 函数,这个函数将调⽤用 MLP 类定义的forward 函数来完成前向计算。
nn.Module 的__call__方法调用forward方法的具体流程:
-
调用module的call方法
-
module的call里面调用module的forward方法
-
forward里面如果碰到Module的子类,回到第1步,如果碰到的是Function的子类,继续往下
-
调用Function的call方法
-
Function的call方法调用了Function的forward方法。
-
Function的forward返回值
-
module的forward返回值
-
在module的call进行forward_hook操作,然后返回值。
3.4.2 神经网络中常见的层
- 不含模型参数的层
定义了一个将输入减掉均值后输出的层,并将层的计算定义在了 forward 函数里
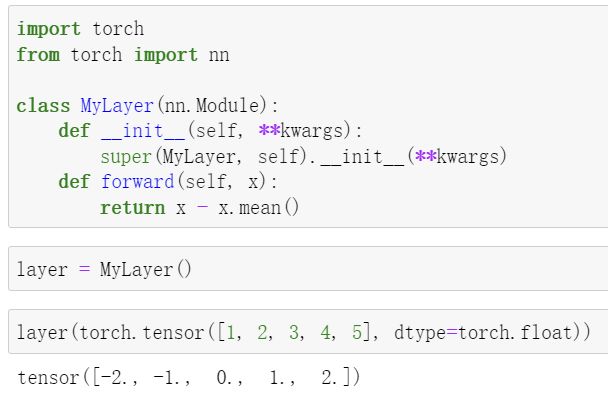
- 含模型参数的层
torch.mm是两个矩阵相乘,即两个二维的张量相乘
Parameter 类其实是 Tensor 的子类,如果一 个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表里。所以在⾃定义含模型参数的层时,我们应该将参数定义成 Parameter 。
用ParameterList 定义参数列表:
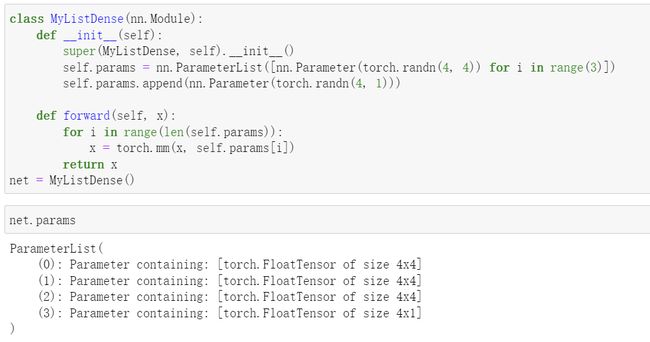
用ParameterDict定义参数字典:

-
二维卷积层nn.Conv2d()
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏差来得到输出。
nn.Conv2d(in_channels, out_channels,kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zero’)功能:对多个二维信号进行二维卷积
主要参数:
in_channels:输入的通道数
out_channels:输出通道数,等价于卷积核的个数
kernel_size:卷积核的尺寸
stride:步长
padding:补边
dilation:空洞卷积的大小,通常用于图像分割
groups:分组卷积的设置,通常用于图像轻量化
bias:偏置 -
池化层
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。
一维最大池化(max pooling)操作
class torch.nn.MaxPool1d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
3.4.3 模型示例
一个神经网络的典型训练过程如下:
- 定义包含一些可学习参数(或者叫权重)的神经网络
- 在输入数据集上迭代
- 通过网络处理输入
- 计算 loss (输出和正确答案的距离)
- 将梯度反向传播给网络的参数
- 更新网络的权重,一般使用一个简单的规则:
weight = weight - learning_rate * gradient
- LeNet
3.5 模型初始化
PyTorch在torch.nn.init中为我们提供了常用的初始化方法。一个好的权重值,会使模型收敛速度提高,使模型准确率更精确。
3.5.1 torch.nn.init内容
torch.nn.init提供了以下初始化方法:
torch.nn.init.uniform_(tensor, a=0.0, b=1.0)torch.nn.init.normal_(tensor, mean=0.0, std=1.0)torch.nn.init.constant_(tensor, val)torch.nn.init.ones_(tensor)torch.nn.init.zeros_(tensor)torch.nn.init.eye_(tensor)torch.nn.init.dirac_(tensor, groups=1)torch.nn.init.xavier_uniform_(tensor, gain=1.0)torch.nn.init.xavier_normal_(tensor, gain=1.0)torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan__in’, nonlinearity=‘leaky_relu’)torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)torch.nn.init.orthogonal_(tensor, gain=1)torch.nn.init.sparse_(tensor, sparsity, std=0.01)torch.nn.init.calculate_gain(nonlinearity, param=None)
这些函数除了calculate_gain,所有函数的后缀都带有下划线,意味着这些函数将会直接原地更改输入张量的值。
3.5.2 torch.nn.init使用
通常会根据实际模型来使用torch.nn.init进行初始化,通常使用isinstance来进行判断模块属于什么类型。
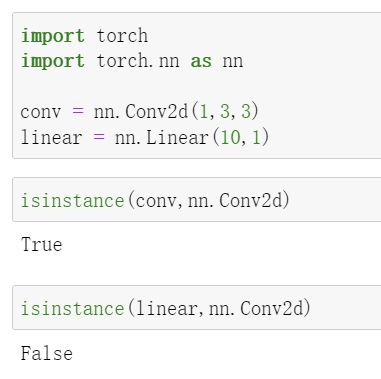
对于不同的类型层,我们就可以设置不同的权值初始化的方法

kaiming初始化:

常数初始化:
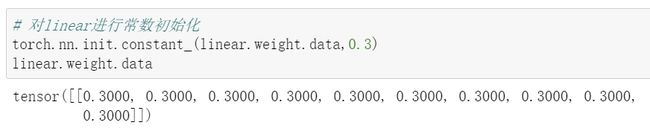
3.5.3 初始化函数的封装
将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。
def initialize_weights(self):
for m in self.modules():
# 判断是否属于Conv2d
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
# 判断是否有偏置
if m.bias is not None:
torch.nn.init.constant_(m.bias.data,0.3)
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0.1)
if m.bias is not None:
torch.nn.init.zeros_(m.bias.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zeros_()
3.6 损失函数
损失函数是数据输入到模型当中,产生的结果与真实标签的评价指标,我们的模型可以按照损失函数的目标来做出改进。
3.6.1 二分类交叉熵损失函数
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
功能:计算二分类任务时的交叉熵(Cross Entropy)函数。在二分类中,label是{0,1}。对于进入交叉熵函数的input为概率分布的形式。一般来说,input为sigmoid激活层的输出,或者softmax的输出。
主要参数:
weight:每个类别的loss设置权值
size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
reduce:数据类型为bool,为True时,loss的返回是标量。
3.6.2 交叉熵损失函数
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
功能:计算交叉熵函数
主要参数:
weight:每个类别的loss设置权值。
size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。
ignore_index:忽略某个类的损失函数。
reduce:数据类型为bool,为True时,loss的返回是标量。
3.6.3 L1损失函数
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
功能: 计算输出y和真实标签target之间的差值的绝对值。
我们需要知道的是,reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。 sum:所有元素求和,返回标量。 mean:加权平均,返回标量。 如果选择none,那么返回的结果是和输入元素相同尺寸的。默认计算方式是求平均。
3.6.4 MSE损失函数
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
功能: 计算输出y和真实标签target之差的平方。
和L1Loss一样,MSELoss损失函数中,reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。 sum:所有元素求和,返回标量。默认计算方式是求平均。
3.6.5 平滑L1 (Smooth L1)损失函数
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
功能: L1的平滑输出,其功能是减轻离群点带来的影响
reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。 sum:所有元素求和,返回标量。默认计算方式是求平均。
提醒: 之后的损失函数中,关于reduction 这个参数依旧会存在。所以,之后就不再单独说明。
3.6.6 目标泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')
功能: 泊松分布的负对数似然损失函数
主要参数:
log_input:输入是否为对数形式,决定计算公式。
full:计算所有 loss,默认为 False。
eps:修正项,避免 input 为 0 时,log(input) 为 nan 的情况。
3.6.7 KL散度
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
功能: 计算KL散度,也就是计算相对熵。用于连续分布的距离度量,并且对离散采用的连续输出空间分布进行回归通常很有用。
主要参数:
reduction:计算模式,可为 none/sum/mean/batchmean。
none:逐个元素计算。
sum:所有元素求和,返回标量。
mean:加权平均,返回标量。
batchmean:batchsize 维度求平均值。
3.6.8 MarginRankingLoss
torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')
功能: 计算两个向量之间的相似度,用于排序任务。该方法用于计算两组数据之间的差异。
主要参数:
margin:边界值,x1 与x2 之间的差异值。
reduction:计算模式,可为 none/sum/mean。
3.6.9 多标签边界损失函数
torch.nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction='mean')
功能: 对于多标签分类问题计算损失函数。
主要参数:
reduction:计算模式,可为 none/sum/mean。
3.6.10 二分类损失函数
torch.nn.SoftMarginLoss(size_average=None, reduce=None, reduction='mean')torch.nn.(size_average=None, reduce=None, reduction='mean')
功能: 计算二分类的 logistic 损失。
主要参数:
reduction:计算模式,可为 none/sum/mean。
3.6.11 多分类的折页损失
torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, size_average=None, reduce=None, reduction='mean')
功能: 计算多分类的折页损失
主要参数:
reduction:计算模式,可为 none/sum/mean。
p:可选 1 或 2。
weight:各类别的 loss 设置权值。
margin:边界值
3.6.12 三元组损失
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='mean')
功能: 计算三元组损失。
三元组: 这是一种数据的存储或者使用格式。<实体1,关系,实体2>。在项目中,也可以表示为< anchor, positive examples , negative examples>
在这个损失函数中,我们希望去anchor的距离更接近positive examples,而远离negative examples
主要参数:
reduction:计算模式,可为 none/sum/mean。
p:可选 1 或 2。
margin:边界值
3.6.13 HingEmbeddingLoss
torch.nn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction='mean')
功能: 对输出的embedding结果做Hing损失计算
主要参数:
reduction:计算模式,可为 none/sum/mean。
margin:边界值
3.6.14 余弦相似度
torch.nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean')
功能: 对两个向量做余弦相似度
主要参数:
reduction:计算模式,可为 none/sum/mean。
margin:可取值[-1,1] ,推荐为[0,0.5] 。
3.6.15 CTC损失函数
torch.nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False)
功能: 用于解决时序类数据的分类
计算连续时间序列和目标序列之间的损失。CTCLoss对输入和目标的可能排列的概率进行求和,产生一个损失值,这个损失值对每个输入节点来说是可分的。输入与目标的对齐方式被假定为 “多对一”,这就限制了目标序列的长度,使其必须是≤输入长度。
主要参数:
reduction:计算模式,可为 none/sum/mean。
blank:blank label。
zero_infinity:无穷大的值或梯度值为
3.7 训练和评估
3.7.1 设置模型的状态
如果是训练状态,那么模型的参数应该支持反向传播的修改;如果是验证/测试状态,则不应该修改模型参数。在PyTorch中,模型的状态设置非常简便,如下的两个操作二选一即可:
model.train() # 训练状态
model.eval() # 验证/测试状态
用for循环读取DataLoader中的全部数据
for data, label in train_loader:
之后将数据放到GPU上用于后续计算,此处以.cuda()为例
data, label = data.cuda(), label.cuda()
开始用当前批次数据做训练时,应当先将优化器的梯度置零:
optimizer.zero_grad()
之后将data送入模型中训练:
output = model(data)
根据预先定义的criterion计算损失函数:
loss = criterion(output, label)
将loss反向传播回网络:
loss.backward()
使用优化器更新模型参数:
optimizer.step()
这样一个训练过程就完成了,后续还可以计算模型准确率等指标。
验证/测试的流程基本与训练过程一致,不同点在于:
- 需要预先设置torch.no_grad,以及将model调至eval模式
- 不需要将优化器的梯度置零
- 不需要将loss反向回传到网络
- 不需要更新optimizer
3.7.2 图像分类的训练/验证过程
一个完整的图像分类的训练过程如下所示:
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(label, output)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
一个完整图像分类的验证过程如下所示:
def val(epoch):
model.eval()
val_loss = 0
with torch.no_grad():
for data, label in val_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
running_accu += torch.sum(preds == label.data)
val_loss = val_loss/len(val_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, val_loss))
3.8 可视化
某些任务在训练完成后,需要对一些必要的内容进行可视化,比如分类的ROC曲线,卷积网络中的卷积核,以及训练/验证过程的损失函数曲线等等。
3.9 Pytorch优化器
优化器是根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值,使得模型输出更加接近真实标签。
3.9.1 Pytorch提供的优化器
Pytorch提供了一个优化器的库torch.optim,在这里面提供了十种优化器:
torch.optim.ASGDtorch.optim.Adadeltatorch.optim.Adagradtorch.optim.Adamtorch.optim.AdamWtorch.optim.Adamaxtorch.optim.LBFGStorch.optim.RMSproptorch.optim.Rproptorch.optim.SGDtorch.optim.SparseAdam
以上这些优化算法均继承于基类Optimizer
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
3.9.2Optimizer的其他方法
-
zero_grad():清空所管理参数的梯度,PyTorch的特性是张量的梯度不自动清零,因此每次反向传播后都需要清空梯度。 -
step():执行一步梯度更新,参数更新 -
add_param_group():添加参数组 -
load_state_dict():加载状态参数字典,可以用来进行模型的断点续训练,继续上次的参数进行训练 -
state_dict():获取优化器当前状态信息字典
3.9.3 实际操作
import os
import torch
# 设置权重,服从正态分布 --> 2 x 2
weight = torch.randn((2, 2), requires_grad=True)
# 设置梯度为全1矩阵 --> 2 x 2
weight.grad = torch.ones((2, 2))
# 输出现有的weight和data
print("The data of weight before step:\n{}".format(weight.data))
print("The grad of weight before step:\n{}".format(weight.grad))

# 实例化优化器
optimizer = torch.optim.SGD([weight], lr=0.1, momentum=0.9)
# 进行一步操作
optimizer.step()
# 查看进行一步后的值,梯度
print("The data of weight after step:\n{}".format(weight.data))
print("The grad of weight after step:\n{}".format(weight.grad))

optimizer.zero_grad()
# 检验权重是否为0
print("The grad of weight after optimizer.zero_grad():\n{}".format(weight.grad))

# 输出参数
print("optimizer.params_group is \n{}".format(optimizer.param_groups))
# 查看参数位置,optimizer和weight的位置一样,我觉得这里可以参考Python是基于值管理
print("weight in optimizer:{}\nweight in weight:{}\n".format(id(optimizer.param_groups[0]['params'][0]), id(weight)))

# 添加参数:weight2
weight2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": weight2, 'lr': 0.0001, 'nesterov': True})
# 查看现有的参数
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))

# 查看当前状态信息
opt_state_dict = optimizer.state_dict()
print("state_dict before step:\n", opt_state_dict)

# 进行5次step操作
for _ in range(50):
optimizer.step()
# 输出现有状态信息
print("state_dict after step:\n", optimizer.state_dict())

# 保存参数信息
torch.save(optimizer.state_dict(),os.path.join(r"E:\Study\JupyterProject\datawhale_pytorch\Attention_Unet", "optimizer_state_dict.pkl"))
print("----------done-----------")

# 加载参数信息
state_dict = torch.load(r"E:\Study\JupyterProject\datawhale_pytorch\Attention_Unet\optimizer_state_dict.pkl") # 需要修改为你自己的路径
optimizer.load_state_dict(state_dict)
print("load state_dict successfully\n{}".format(state_dict))

# 输出最后属性信息
print("\n{}".format(optimizer.defaults))
print("\n{}".format(optimizer.state))
print("\n{}".format(optimizer.param_groups))

注意:
- 每个优化器都是一个类,我们一定要进行实例化才能使用,比如下方实现:
class Net(nn.Moddule):
···
net = Net()
optim = torch.optim.SGD(net.parameters(),lr=lr)
optim.step()
-
optimizer在一个神经网络的epoch中需要实现下面两个步骤:
-
梯度置零
-
梯度更新
-
optimizer = torch.optim.SGD(net.parameters(), lr=1e-5)
for epoch in range(EPOCH):
...
optimizer.zero_grad() #梯度置零
loss = ... #计算loss
loss.backward() #BP反向传播
optimizer.step() #梯度更新
- 给网络不同的层赋予不同的优化器参数。
文章参考:https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E4%B8%89%E7%AB%A0/index.html