Win10下尝试训练tensorflow的官网models分支中的DeepLabV3p模型
Win10下尝试训练tensorflow的官网models分支中的DeepLabV3p模型
- 一、系统环境介绍
- 二、models源码运行环境配置
-
- 2.1下载models源码并安装依赖包
- 2.2tensorflow进行升版
- 2.3models源码降版下载
- 2.4tensorflow1.15.0安装
- 三、模型训练
-
- 3.1训练数据准备
- 3.2模型训练
- 四、总结
- 参考文档
一、系统环境介绍
操作系统:Windows10专业版
安装工具:miniconda
CUDA:10.1
cuDNN:7.6.5
tensorflow:tensorflow-gpu2.3.0
本文尝试使用GitHub上的tensorflow的models分支进行DeepLabV3p模型训练,将尝试过程记录在本文,最终得出结论如下:
(1)GitHub上的tensorflow的models分支只适用于tensorflow1系列,而不适用于2系列,原因一为models分支中代码是基于1系列编写,原因二为models的依赖包版本问题只有在1系列才能够解决,所以tensorflow-gpu2.3.0无法使用models分支;
(2)基于models分支只适用于tensorflow1系列的结论,tensorflow1系列最新版本为1.15.0,该版本的GPU版本只支持cuda10,不支持10.1及以上版本,因此如要使用GPU加速训练models分支,则只能安装cuda10。
tensorflowGPU安装教程可参照tensorflow-gpu版本安装教程(过程详细)。
补充结论:经在显卡租用网站AutoDL上测试,models分支在Ubuntu系统下可在cuda11.4上进行训练,测试环境为:Ubuntu系统18.04,tensorflow1.15.5版本,cuda11.4。
二、models源码运行环境配置
2.1下载models源码并安装依赖包
在GitHub上下载tensorflow的models分支源码,地址为https://github.com/tensorflow/models,使用git工具进行下载,下载命令如下:
git clone https://github.com/tensorflow/models.git
本文将models下载至D:\tensorflow路径。
下载完成后,根据官网安装步骤说明,先不必进行添加models路径至PYTHONPATH步骤,因为添加路径是为了最终执行训练代码。
首先打开miniconda命令行终端,激活tensorflow环境,进入models的同一级路径,输入如下命令进行依赖包的安装,:
pip install -r models/official/requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
安装结束后报出如下错误:
![]()
错误表明tensorflow2.3.0要求numpy小于1.19.0,但是models的依赖环境中要求numpy>=1.20,numpy版本出现冲突。尝试忽略错误,在python中导入tensorflow包,结果报出“AttributeError: module ‘numpy’ has no attribute ‘object’”错误,无法执行tensorflow代码。
2.2tensorflow进行升版
考虑到models的依赖环境中要求numpy>=1.20,而当前tensorflow的版本为2.3.0要求numpy小于1.19.0,所以计划对tensorflow进行升版,查看升版后numpy版本是否达到1.20及以上。尝试安装2.4.0、2.5.0、2.6.0版本的tensorflow-gpu,但numpy版本均未达到1.20及以上,且当tensorflow-gpu版本为2.4.0及以上时,导入包时提示找不到cuda的dll文件,即无法使用GPU进行训练,根据官网的介绍,2.4.0及以上版本的tensorflow只支持cuda11.0及以上,而本机安装的cuda为10.1。
综上,对tensorflow进行升版尝试失败。
2.3models源码降版下载
因为当前版本的models依赖环境中要求numpy>=1.20,所以计划对models进行降级,查看降版后numpy版本是否小于1.19。在GitHub上逐一选择models分支的版本,并查看requirements.txt文件中对numpy版本的要求,最终发现v2.3.0版本对numpy版本仅要求>=1.15.4,且同时包含research文件夹(deeplab模型存在于该文件夹中),因此下载该版本的源码,命令如下:
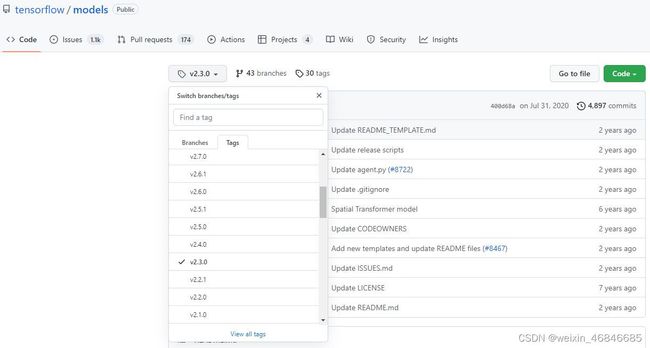
git clone -b v2.3.0 https://github.com/tensorflow/models.git
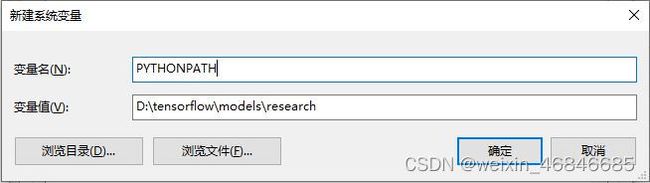
下载后不再进行依赖包的安装,而是添加models/research的完整路径(如本机中为D:\tensorflow\models\research)至环境变量,步骤为打开电脑的环境变量窗口,系统环境变量——新建——添加PYTHONPATH及models/research路径,如下图:
添加后重启miniconda命令行终端,激活tensorflow环境后,执行deeplab文件夹下的model_test.py文件,结果添加链接描述报出如下错误:
“AttributeError:module tensorflow no attribute app”,经搜索可知该错误是在tf2.0环境中执行1.0代码导致,而经检查发现,最新版models源码中也为tf1.0代码。
2.4tensorflow1.15.0安装
由于发现models源码基于tf1.0编写,而tf1.0最新版本为1.15.0,因此安装tf-gpu1.15.0,安装教程如第一节所介绍,安装完毕后,按照2.1节所述进行依赖包的安装,安装结束后报出错误“Error: subprocess-exited-with -error”,如下图:

忽略该错误,按照2.3节中的添加路径执行deeplab文件夹下的model_test.py尝试,爆出错误“If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.”,如下图:

经搜索,解决方法为安装protobuf3.19.0,命令如下:
pip install protobuf==3.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
继续执行model_test.py,报出错误“ModuleNotFoundError: No module named ‘nets’”,如下图:

经检查,发现nets位于models\research\slim文件夹下,所以将models\research\slim也添加至环境变量中,问题得到解决。

继续执行model_test.py,报出错误“ModuleNotFoundError: No module named ‘tf_slim’”,如下图:

经搜索,解决方法为安装tf_slim,命令如下:
pip install tf_slim -i https://pypi.tuna.tsinghua.edu.cn/simple
继续执行model_test.py,不再弹出错误,如下图所示,说明测试成功:

三、模型训练
3.1训练数据准备
以PascalVOC2012数据集为数据进行训练,在deepab/datasets文件夹内有一文件名为download_and_convert_voc2012.sh的脚本文件,该脚本文件功能为voc2012数据压缩包,解压后调用remove_gt_colormap.py文件进行数据集中标签图像的颜色转换,该脚本在Windows下无法运行,但可以由人工操作进行替代。
首先下载voc2012数据压缩包,下载地址为https://data.deepai.org/PascalVOC2012.zip,下载完成后解压至某一路径。
然后使用文本编辑器打开remove_gt_colormap.py,将里面voc2012数据集的存储路径替换为实际路径,如下图:

修改后执行py文件,报出“ModuleNotFoundError: No module named ‘PIL’”错误,因此安装pillow包,安装后执行,执行效果如下图:


执行前标签为彩色,执行后将标签中的目标区域以标签的索引值作为灰度值填充。
接下来需将voc数据转换为tf训练的专用数据格式,即TFRecord格式,打开deepab/datasets文件夹下的build_voc2012_data.py文件,将voc数据集路径更改为实际路径,并设置生成的TFRecord文件保存路径,如下图:

然后运行build_voc2012_data.py文件,结果报出“Windows fatal exception: access violation”错误,如下图:

经参照其他博客,发现需将deepab/datasets文件夹下的build_data.py文件中38行中的图片格式由‘png’更改为‘jpg’,因为voc2012中的图片格式为jpg格式,重新运行,顺利生成TFRecord文件:
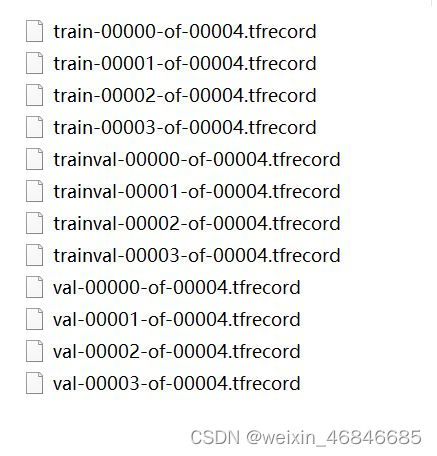
3.2模型训练
首先下载预训练模型,下载地址为https://github.com/tensorflow/models/blob/master/research/deeplab/g3doc/model_zoo.md,其中提供了基于PASCAL VOC 2012、Cityscapes、ADE20K、ImageNet数据集及mobilenet、xception、resnet主干网络训练的模型:

打开deepab文件夹下train.py文件,对其中训练参数进行修改,参数修改可参照https://blog.csdn.net/fightingxyz/article/details/105488802博客内容,然后运行该文件开始模型训练:

打开任务管理器发现,终端训练只占用了CPU资源和内存资源,而GPU资源未被使用,说明tensorflow-GPU1.15.0确实无法使用cuda10.1,如要使用GPU加速,只能安装cuda10。
四、总结
总结如下:
(1)GitHub上的tensorflow的models分支只适用于tensorflow1系列,而不适用于2系列,原因一为models分支中代码是基于1系列编写,原因二为models的依赖包版本问题只有在1系列才能够解决,所以tensorflow-gpu2.3.0无法使用models分支;
(2)基于models分支只适用于tensorflow1系列的结论,tensorflow1系列最新版本为1.15.0,该版本的GPU版本只支持cuda10,不支持10.1及以上版本,因此如要使用GPU加速训练models分支,则只能安装cuda10。
参考文档
tensorflow-gpu版本安装教程(过程详细)
图像分割:Tensorflow Deeplabv3+训练人像分割数据集
运行官网tensorflow的deeplabv3代码
win10系统下使用deeplabv3训练自己的数据
tensorflow上实现deeplabv3+
AttributeError:module tensorflow no attribute app解决办法
ModuleNotFoundError: No module named ‘tensorflow.contrib‘ 解决方法
解决tensorflow2.x中使用tf.contrib.slim包时出现的No module named:tensorflow.contrib 问题
windows 环境下 Python 添加环境变量方法大全!!!(PYTHONPATH)
your generated code is out of date and must be regenerated with protoc >= 3.19.0.
TF的ObjectAPI遇到ModuleNotFoundError: No module named ‘tf_slim‘
23、OpenMV使用tensorflow 1.15.0训练模型mobilenet_v1_1.0_224进行车辆识别
Ubuntu下添加Python环境变量