PointConv理解与解析
PointConv理解与解析
文章目录
- PointConv理解与解析
-
-
- 一、目前点云分割算法的缺点
- 二、PointConv的贡献
- 三、PointConv的结构
- 四、实验
- 五、加群交流
-
一、目前点云分割算法的缺点
基于体素化的点云分割: 体素化的方法受三维体积分辨率和三维卷积计算量的限制。使用体素化进行的点云的分割会造成巨大的计算量。这对我们计算的设备有这很大的要求,代价过于昂贵,使得使用体素化的方法在最近几年并不常用。
基于直接使用点云作为输入进行点云分割: PointNet和PointNet++尽管在直接使用点云作为输入在语义分割方面在时间和空间上均取得较大的成功,但是点云的在PointNet和PointNet++的方法中均在全局使用了MaxPooling,但MaxPooling只能够保留局部或者全局最明显的特征信息,而对于其他相对不是很明显的信息采用直接抛弃掉,但是往往有时候这些相对不是很明显得信息往往能够很大的帮助网络进行语义分割。
与上面两种方法不同的是,PointCNN在点云上使用二维卷积的方法来进行语义分割。通过使用X-Conv来聚合点的空间结构信息和局部特征信息。但是相对于本文的PointConv,PointCNN并没有实现点云的置换不变性。
二、PointConv的贡献
当我们拿到一篇好的论文的时候,我们不应该把所有的注意力集中在如何网络机构是怎么样的?他的网络的设计是怎样的?我们跟应该回到最初始的原点,分析为什么这么做?这么做是为了实现什么?是为了改进哪方面带来的不做。
首先由于一个场景或者一个物体代表它本身所需要的点的数量是相当的庞大的,如果我们不做任何的处理,直接把所有的点云的点直接作为输入在网络中进行计算,这将造成无法估计计算量。所以目前所有的基于点云上的算法,第一步做的都是最远点采样(FPS) ,从宏观上来看,最远点采样的方法在减少点云样本数量的同时也极大的保留点云的原始的空间结构。但是从微观上看,最远点采样的算法属于非均匀采样,这样就会导致某些局部区域点大量聚集,而某些区域的的点的数量只有寥寥无几。而PointConv正是发现这一问题,尝试着通过核密度估计方法来解决这个问题,所以博主认为这也是PointConv提出的最大的一个贡献。
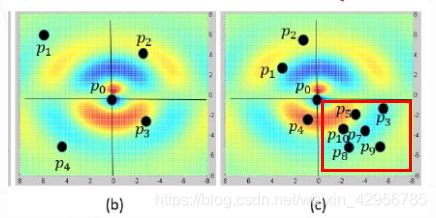
图一
对于图一笔者给出的解释是,我们尽可能的希望我们通过最远点采样得到的采样的点分布是(b)的情况,采样点近似于均匀分布。但是绝大部分的时候,我们的采样点的分布更接近于(c),这也更接近真实的情况。但是我们从(c) 中很轻而易举的想到一个例子作者为什么要使用核密度估计啦。
**例子:**假设图©中的点,红色方框里面的点是代表桌面上的点。而p1,p2则代表的是桌角上的点的。那我们可以很容易的知道,当我们的网络要知道哪个区域是代表桌面,那么则会有七八个点告诉我们的网络该区域是桌面,而当我们的网络想知道桌角是哪个区域的时候,只有一到两个点可以告知它。当网络在提取特征的时候,如果失去了这两个点的特征,那我们的网络就将永远失去了对该场景桌面特征的提取,但是对于桌面特征的提取,即使我们的网络丢失了好几点,但是最终还是有点可以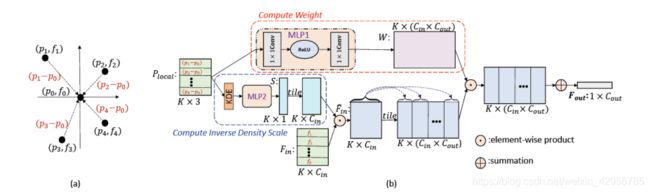 告诉我们网络,该区域是桌面。理所当然,如果我们能有意的提高p1,p2这两个代表桌角点的权重,让我们的网络重视这个两个点,这样就不至于网络会丢失这两个点的特征。理所当然我们也要降低点密度较大的地方的权重。
告诉我们网络,该区域是桌面。理所当然,如果我们能有意的提高p1,p2这两个代表桌角点的权重,让我们的网络重视这个两个点,这样就不至于网络会丢失这两个点的特征。理所当然我们也要降低点密度较大的地方的权重。
三、PointConv的结构
首先,我们来看一下PointConv的特征聚合的结构:
图(b) 中的Plocal、Fin就是通过最远点采样后得到的点,然后按照图(a)的方法——以采样点为局部坐标的中心,将临近点转变为相对于采样点的局部坐标形成Plocal,而临近点的特征则形成Fin。
上半部分: 直接将Plocal的坐标直接丢经MLP1中,最终得到值近似成一个权重W,这权重将会直接和下半部分得到的特征直接相乘。所以上半部分的主要任务就是将局部坐标的空间结构信息加入网络中(博主自我理解)。
下半部分: 首先使用KDE(核密度估计)的方法计算每个临近点的密度,KDE算的密度是密度越大地方值越大,所以我们这边需要使用的是密度的倒数,把密度的倒数送进MLP2中最终得到S,并将临近点的密度S复制了Cin次,将密度与Fin进行相乘,这样就达到了通过密度来干预特征权重的作用。
相乘部分: 这一部分则是我们常见的相乘的操作。
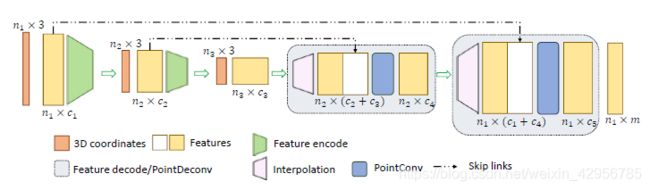
这一部分就是特征传播层:
特征传播层对于分割任务其实是相当重要的,如何把特征聚合得到的粗糙层信息传播到精细层的信息是至关重要的,这也直接影响到我们分割的精度。传统的或者可以说是常用的方法一般是通过三个点进行线性插值的方法来进行特征传播,但PointConv的作者认为这并不能够很好的做到点云的特征的传播。所以作者重新设计了一个更好的特征传播层。
作者将Pointconv的部分加入了线性插值之后,这使得网络能更好的特征的传播。作者通过实验也说明这个方法的作用。

**高效的PointConv:**从之前的PointConv可以直接推出,W权重这一部分将会造成很大的计算量,所以作者根据这个改进之前的网络结构使得网络的计算量变小。
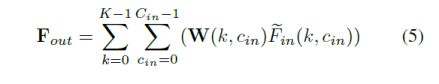
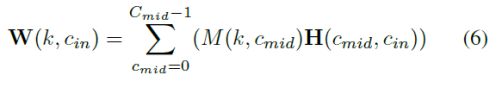
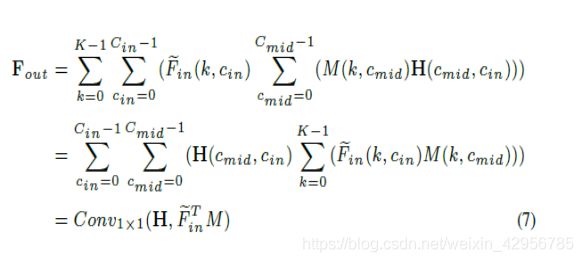
这里应用作者的原话来解释网络的有效性:

对于公式5和公式6推理出公式7的其实很简单,在这就不做过多的赘述。
四、实验
分割实验:
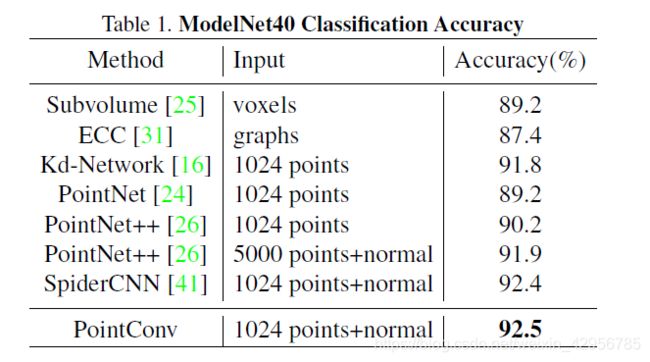
在model40的分割上,目前各种方法都取得了较高精度,但对于PointConv在这方面也取得了突破。
部分分割(ShapeNet):
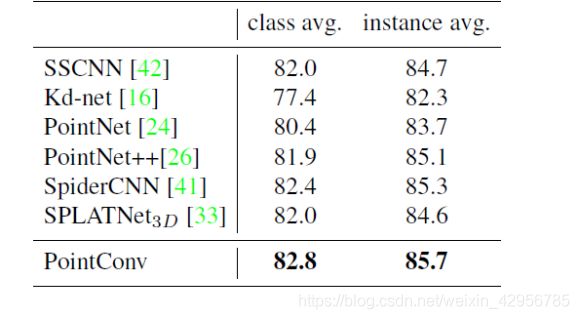
从图中我们可以很明显的看出,PointConv在每一类的平均精度和实例分割的平均精度都高于其他网络的水平。
语义分割(ScanNet):
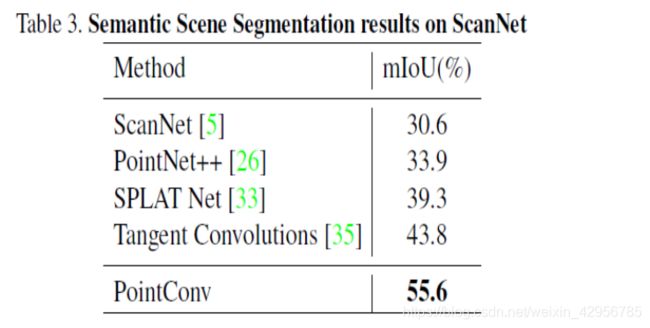
论文中只有给去mIOU的精度,在这个的精度上,PointConv提高了10%以上的精度。但是文中并没有给出语义分割的精度,博主就擅自改变了代码的输出,测试了在ScanNet的精度,在这里假设博主代码更改没有错误的话,PointConv在这方面的精度只有80%~81%左右,这也逊色于PointNet++等其他网络。
论文地址:https://arxiv.org/pdf/1811.07246.pdf
代码地址:https://github.com/DylanWusee/pointconv
五、加群交流
公众号交流: