[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第1张图片](http://img.e-com-net.com/image/info8/737fcf0e17aa4d1aa6a4028b4e68da4f.jpg)
1. Motivation
本文是基于fine-tuning based方法
- In this work, we observe and address the essential weakness of the fine- tuning based approach – constantly mislabeling novel in- stances as confusable categories, and improve the few-shot detection performance to the new state-of-the-art (SOTA)
2. Contribution
对比学习的引入。
- We present Few-Shot object detection via Contrastive pro- posals Encoding (FSCE), a simple yet effective fine-tune based approach for few-shot object detection
本文通过一个对比的分支来加强RoI,对比分支衡量proposal encoding之间的相似度。
- When trans- fer the base detector to few-shot novel data, we augment the primary Region-of-Interest (RoI) head with a contrastive branch, the contrastive branch measures the similarity between object proposal encodings
- contrastive proposal encoding (CPE) loss,
3. Methods
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第2张图片](http://img.e-com-net.com/image/info8/18cecd14d069494982227e68b3fcb0c3.jpg)
3.1 Preliminary
Rethinking the two-stage fine-tuning approach
作者指出,冻结了RPN,FPN以及ROI 特征提取的部分是不太合理的,因为这样子会使得特征只含有base classes。
虽然在TFA baseline中,不冻结RPN和ROI会造成性能的下降,但是本文指出,fine-tune ROI feature extractor 以及 box predictor效果更好
- In baseline TFA, unfreezing RPN and RoI feature extractor leads to degraded results for novel classes.
- We propose a stronger baseline which adapts much better to novel data with jointly fine-tuned feature extractors and box predictors
FSCE是对于TFA的改进,因此也是属于tranfer-learning based的方法。FSCE对于第二阶段的冻结层,只冻结了ROI之前的部分。将RoI feature extractor通过对比函数来监督。
-
However it is counter-intuitive that Feature Pyramid Network , RPN, especially the RoI feature extractor which contain semantic information learned from base classes only, could be transferred directly to novel classes without any form of training.
-
The backbone feature extractor is frozen during fine-tuning while the RoI feature extractor is supervised by a contrastive objective.
从图4可以得出,TFA在fine-tune阶段 rpn的positive anchor比base training少了很多。
那么作者的观点就是改善这些得分较低proposal objectness ,它们都无法通过RPN的nms操作,就被淘汰了。
除此之外,重新平衡前景proposals的比例,对于防止背景类统治fine-tuning阶段的梯度非常的关键。
- Our insight is to rescue the low objectness positive anchors that are suppressed.
- Besides, re-balancing the foreground proposals fraction is also critical to prevent the diffusive yet easy backgrounds from dominating the gradient descent for novel instances in fine-tuning
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第3张图片](http://img.e-com-net.com/image/info8/2e3ff95ed27044ffb04a783250560f54.jpg)
因此,作者的改进方法是解冻了RPN和RoI层,使用2个新的设定:使得RPN NMS后的proposals更多,并且使得在RoI head 部分进行loss计算采样的proposals减半,也就是在fine-tuning阶段减半的porposal只包含背景部分(即 1:1 各128个)。
- double the maximum number of proposals kept after NMS, this brings more foreground proposals for novel instances
- halving the number of sampled proposals in RoI head used for loss computation, as in fine-tuning stage the discarded half contains only backgrounds(standard RoI batch size is 512, and the number of foreground proposals are far less than half of it)
# default
ROI.BATCH_SIZE_PER_IMAGE = 512
# new for FSCE in configs
ROI.BATCH_SIZE_PER_IMAGE = 256
得到更强的baseline的实验如下:
其中Fine-tune FPN指的是不冻结FPN层。 refinement RPN、 ROI指的是对于2部分进行更改。总体而言相比TFA原先的backbone,提升很明显。
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第4张图片](http://img.e-com-net.com/image/info8/86a7080f022a4803b44082492f5c5b3b.jpg)
3.2. Contrastive object proposal encoding
本文在ROI的双分支结构中,引入并行的contrastive branch,由于ROI阶段会引入ReLU 非线性操作,本文认为这样子做会在0处截断,从而导致2个proposal embedding之间的特征无法被计算出来,因此改用MLP结构,得到的对比特征为128,从而是的类别相同的proposal之间的相似度越大,类别不同的proposal更有区分度(使用constrastive loss)
- we introduce a contrastive branch to the primary RoI head, parallel to the classifica- tion and regression branches.
- Therefore, the contrastive branch ap- plies a 1-layer multi-layer-perceptron (MLP) head with neg- ligible cost to encode the RoI feature to contrastive feature
3.3. Contrastive Proposal Encoding (CPE) Loss
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第5张图片](http://img.e-com-net.com/image/info8/02362cd98bbd46ba9e3d4e48e6cb661a.jpg)
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第6张图片](http://img.e-com-net.com/image/info8/23ec35f6cc114604944cd19120ca622b.jpg)
- Proposal consistency control
对于这个分支的输入是 { z i , u i , y i } i = 1 N \{z_i, u_i, y_i\}^N_{i=1} {zi,ui,yi}i=1N,其中 z i z_i zi是contrastive 的特征, y i y_i yi表示proposal boxes的gt-label, u i u_i ui是IOU
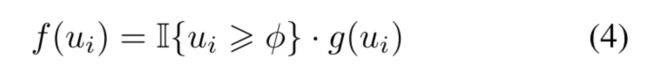
- training objectives
第一阶段的训练方法和TFA保持一致,在fine-tuning stage中,加入CPE loss。

4. Experiments
4.1 COCO
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第7张图片](http://img.e-com-net.com/image/info8/1639518ff1844a11a47f022f99c3500b.jpg)
不过相比于GFSD,FSCE的方法还是会forget base class。(5-shot VOC GFSD是:80.7)
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第8张图片](http://img.e-com-net.com/image/info8/bd506c52175c4c0ba5925ef932741321.jpg)
4.2 VOC
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第9张图片](http://img.e-com-net.com/image/info8/1a2c158348734f64b07e2ca424a1e06a.jpg)
4.3 Ablation
4.3.1 Components of our proposed FSCE
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第10张图片](http://img.e-com-net.com/image/info8/77f56d5d5eac433bae56d0de66b48b6a.jpg)
4.3.2 Ablation for contrastive branch hyper-parameters
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第11张图片](http://img.e-com-net.com/image/info8/6efb2ef59b0045a1933a74dfbe536d5d.jpg)
4.3.3 Ablation for Proposal Consistency Control
![[FSCE]FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding(CVPR. 2021)_第12张图片](http://img.e-com-net.com/image/info8/0850228a283e4810a569a71eab71e690.jpg)
class ContrastiveHead(nn.Module):
"""MLP head for contrastive representation learning, https://arxiv.org/abs/2003.04297
Args:
dim_in (int): dimension of the feature intended to be contrastively learned
feat_dim (int): dim of the feature to calculated contrastive loss
Return:
feat_normalized (tensor): L-2 normalized encoded feature,
so the cross-feature dot-product is cosine similarity (https://arxiv.org/abs/2004.11362)
"""
def __init__(self, dim_in, feat_dim):
'''
dim_in 1024
feat_dim 128
'''
super().__init__()
self.head = nn.Sequential(
nn.Linear(dim_in, dim_in),
nn.ReLU(inplace=True),
nn.Linear(dim_in, feat_dim),
)
for layer in self.head:
if isinstance(layer, nn.Linear):
weight_init.c2_xavier_fill(layer)
# pdb.set_trace()
def forward(self, x):
feat = self.head(x)
feat_normalized = F.normalize(feat, dim=1) # [bs x 256, 128]
# pdb.set_trace()
return feat_normalized
class SupConLoss(nn.Module):
"""Supervised Contrastive LOSS as defined in https://arxiv.org/pdf/2004.11362.pdf."""
def __init__(self, temperature=0.2, iou_threshold=0.5, reweight_func='none'):
'''Args:
tempearture: a constant to be divided by consine similarity to enlarge the magnitude
iou_threshold: consider proposals with higher credibility to increase consistency.
'''
super().__init__()
self.temperature = temperature # 0.2
self.iou_threshold = iou_threshold # 0.8
self.reweight_func = reweight_func # none
# pdb.set_trace()
def forward(self, features, labels, ious):
"""
Args:
features (tensor): shape of [M, K] where M is the number of features to be compared,
and K is the feature_dim. e.g., [8192, 128]
labels (tensor): shape of [M]. e.g., [8192]
"""
pdb.set_trace()
assert features.shape[0] == labels.shape[0] == ious.shape[0]
if len(labels.shape) == 1:
labels = labels.reshape(-1, 1) # [bs x 256, 1]
# mask of shape [None, None], mask_{i, j}=1 if sample i and sample j have the same label
label_mask = torch.eq(labels, labels.T).float().cuda() # [bs x 256, bs x 256] label_mask 用于过滤
# 这里注意下 features x features.T 在对角线上的元素由于L2正则化的原因, 都是1
similarity = torch.div(torch.matmul(features, features.T), self.temperature) # [bs x 256, bs x 256] according to eq(3)
# for numerical stability
# bs x 512, bs 512 --> bs x 512; 每一个proposal和其他的所有proposal 相似度最大的一个值(其实取得的最大的值也就是自己和自己的attention similarity) 因此下一步需要减去
sim_row_max, _ = torch.max(similarity, dim=1, keepdim=True)
similarity = similarity - sim_row_max.detach() # 做一个广播的减法 对于每一个proposal的特征值: 512 - 1(x512) 这样对角线上的值都是0
# mask out self-contrastive
logits_mask = torch.ones_like(similarity)
logits_mask.fill_diagonal_(0)
# 为什么不是在一个batch内计算 Contrastive loss?
exp_sim = torch.exp(similarity) * logits_mask # [bs x 256, bs x 256] according to eq(3) 因为e^0 = 1 所以需要logits_mask过滤对角线的元素
log_prob = similarity - torch.log(exp_sim.sum(dim=1, keepdim=True)) # [bs x 256, bs x 256]
# log_prob * logits_mask * label_mask 各个元素特征点乘 过滤每一行不同类别的、过滤对角线(自己和自己的similarity)
# sum(1) 512 --> 1 求和
# label_mask.sum(1) 表示每一个proposal的数量 相当于eq(3)的N_y
per_label_log_prob = (log_prob * logits_mask * label_mask).sum(1) / label_mask.sum(1) # [bs x 256]
keep = ious >= self.iou_threshold # [512]
per_label_log_prob = per_label_log_prob[keep] # 过滤
loss = -per_label_log_prob # 直接取负
coef = self._get_reweight_func(self.reweight_func)(ious) # none
coef = coef[keep]
loss = loss * coef
pdb.set_trace()
return loss.mean()
@staticmethod
def _get_reweight_func(option):
def trivial(iou):
return torch.ones_like(iou)
def exp_decay(iou):
return torch.exp(iou) - 1
def linear(iou):
return iou
if option == 'none':
return trivial
elif option == 'linear':
return linear
elif option == 'exp':
return exp_decay