[OTA]Optimal Transport Assignment for Object Detection(CVPR. 2021)
![[OTA]Optimal Transport Assignment for Object Detection(CVPR. 2021)_第1张图片](http://img.e-com-net.com/image/info8/c42b9aaf9bc34005a616cd2af21d6ff4.jpg)
1. Motivation
-
DeTR [3] examines the idea of global optimal matching. But the Hungarian algo- rithm they adopted can only work in a one-to-one assign- ment manner.
-
One-to-Many 的方法。
So far, for the CNN based detectors in one-to-many scenarios, a global optimal assigning strategy remains uncharted.
-
Label Assignment
To train the detector, defining cls and reg targets for each anchor is a necessary procedure, which is called label assignment in object detection.
-
Such static strategies ignore a fact that for objects with different sizes, shapes or occlusion condition, the appropriate posi- tive/negative (pos/neg) division boundaries may vary.
文中认为对于ambiguous anchors的制定是非常重要的。
- Hence the assignment for ambiguous anchors is non-trivial and requires further information beyond the local view.
要将独立的最优分配转化为全局的最优分配。
- Thus a better assigning strategy should get rid of the convention of pursuing optimal assignment for each gt independently and turn to the ideology of global optimum, in other words, finding the global high confidence assignment for all gts in an image.
2. Contribution
相比于DETR的one-to–one Label Assignment,本文认为One-to-Many的Lbael Assignment同样可以对训练有帮助,也可以将制定带有global view的labels。
OT将anchor看做demander,将gt看做supplier。每一个gt供应positive label的数量看做为“每一个gt需要多少个positive anchor来完成训练过程,更好的收敛“。
OTA分别要求anchor与gt以及anchor与background pair-wise的loss,其中anchor与gt pair的transportation cost是cls和reg的loss,而anchor与background的pair-wise loss 只需要计算cls loss就好。
-
To achieve the global optimal assigning result under the one-to-many situation, we propose to formulate label as-signment as an Optimal Transport (OT) problem – a special form of Linear Programming (LP) in Optimization Theory.
-
we define each gt as a supplier who supplies a certain number of labels, and define each anchor as a de- mander who needs one unit label.
-
In this context, the number of positive labels each gt supplies can be interpreted as “how many positive anchors that gt needs for better convergence during the training process”.
-
The unit transportation cost between each anchor-gt pair is defined as the weighted summation of their pair-wise cls and reg losses.
-
The cost between background and a certain anchor is defined as their pair-wise classification loss only.
-
OTA also achieves the SOTA performance among one-stage detectors on a crowded pedestrian detection dataset named CrowdHu- man [35], showing OTA’s generalization ability on different detection benchmarks
3.Method
![[OTA]Optimal Transport Assignment for Object Detection(CVPR. 2021)_第2张图片](http://img.e-com-net.com/image/info8/092e438a87a3479b80e3c0fd2302b67a.jpg)
3.1. Optimal Transport
- Transporting cost for each unit of good from supplier i to demander j is denoted by c i j c_{ij} cij
- We thus address this issue by a fast iterative solution, named Sinkhorn-Knopp
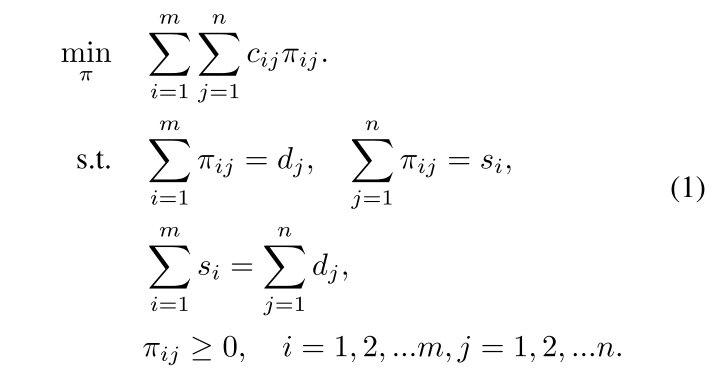
3.2 OT for Label Assignment
m gt targets and n anchors. 根据one-to-many的关系,一个supplier有多个unit(一个unit对应一个demander),一个demander(anchor)值对应一个supplier(gt)。
- we view each gt as a supplier who holds k units of positive labels ( s i = k s_i=k si=k, i = 1, 2, …, m)。
- each anchor as a demander who needs one unit of label(i.e. d j = 1 d_j = 1 dj=1, j= 1,2,…, n)。
c f g c^{fg} cfg前景cost的公式如下所示:(one unit)
其中,Lcls和Lreg分别是cross entropy loss 和 IoU Loss(也可以被其他常用损失函数取代)。α是平衡参数。
对于 c b g c^{bg} cbg背景cost的公式如下所示:
negative labels的数量为 n − m × k n-m\times k n−m×k。 m × k m \times k m×k表示gt共有的所有units,而n表示anchor的个数,由于每一个unit就对应一个anchor(demander)。因此剩余的数量就要分配为negative labels。
c b g ∈ R 1 × n c^{bg}\in R^{1\times n} cbg∈R1×n, c f g ∈ R m × n c^{fg} \in R^{m \times n} cfg∈Rm×n。cat起来可以得到最后的cost matrix c ∈ R ( m + 1 ) × n c \in R^{(m+1) \times n} c∈R(m+1)×n
supply vector s的公式如下所示:
因此可以得到optimal transportation plan π ∗ ∈ R ( m + 1 ) × n \pi^* \in R^{(m+1)\times n} π∗∈R(m+1)×n。
接下来使用线程的Sinkhorn-Knopp Iteration方法,为每一个anchor制定一个gt,这个gt是传输了最大数量的label。
- After getting π∗, one can decode the correspond- ing label assigning solution by assigning each anchor to the supplier who transports the largest amount of labels to them.
OTA在训练中有一定的增加,测试无损耗。
- OTA only increases the total training time by less than 20% and is totally cost-free in testing phase.
3.3 Advanced Designs
3.3.1 Center Prior
加入center prior有利于在前期训练稳定,并且提升网络性能。
- However, for general detection datasets like COCO, we find the Center Prior still benefit the training of OTA.
- Hence, we impose a Center Prior to the cost matrix. For each gt, we select r 2 r^2 r2 closest anchors from each FPN level according to the center distance between anchors and gts.
- As for anchors not in the r 2 r^2 r2 closest list, their corresponding entries in the cost matrix c will be subject to an additional constant cost to reduce the possibility they are assigned as positive samples during the training stage.
3.3.2 Dynamic k Estimation
对于每个gt对应k个anchor的选取,作者采用简单基于IOU的方法来制定。
- we propose a simple but effective method to roughly estimate the appropriate number of pos- itive anchors for each gt based on the IoU values between predicted bounding boxes and gts.
对于每个gt,挑选top q高的iou的 predicted-box,并将iou值全部加起来,来代表每个gt估算的positive anchors的数量,也就是公式中的k。作者将这个方法,命名为Dynamic k Estimation。
- Dynamic k Estimation: Specifically, for each gt, we select the top q predictions according to IoU values. These IoU values are summed up to represent this gt’s estimated number of positive anchors.
- 完整的算法如下:
4. Experiments
4.1 Ablation Studies and Analysis
4.1.1 Effects of Individual Components.
4.1.2 Effects of r
4.1.3 Ambiguous Anchors Handling
4.1.4 Effects of k
4.2 Comparison with State-of-the-art Methods
4.3 Experiments on CrowdHuman
5. Code
class SinkhornDistance(torch.nn.Module):
r"""
Given two empirical measures each with :math:`P_1` locations
:math:`x\in\mathbb{R}^{D_1}` and :math:`P_2` locations :math:`y\in\mathbb{R}^{D_2}`,
outputs an approximation of the regularized OT cost for point clouds.
Args:
eps (float): regularization coefficient
max_iter (int): maximum number of Sinkhorn iterations
reduction (string, optional): Specifies the reduction to apply to the output:
'none' | 'mean' | 'sum'. 'none': no reduction will be applied,
'mean': the sum of the output will be divided by the number of
elements in the output, 'sum': the output will be summed. Default: 'none'
Shape:
- Input: :math:`(N, P_1, D_1)`, :math:`(N, P_2, D_2)`
- Output: :math:`(N)` or :math:`()`, depending on `reduction`
"""
def __init__(self, eps=1e-3, max_iter=100, reduction='none'):
super(SinkhornDistance, self).__init__()
self.eps = eps # 0.1
self.max_iter = max_iter # 50
self.reduction = reduction # none
def forward(self, mu, nu, C):
'''
C: tensor of [num_gt + 1, num_anchor]
mu: tensor of [num_gt + 1]
nu: tensor of [num_anchor]
'''
u = torch.ones_like(mu) # [num_gt + 1]
v = torch.ones_like(nu) # [num_anchor]
# Sinkhorn iterations
for i in range(self.max_iter):
v = self.eps * \
(torch.log(
nu + 1e-8) - torch.logsumexp(self.M(C, u, v).transpose(-2, -1), dim=-1)) + v # [num_anchor]
u = self.eps * \
(torch.log(
mu + 1e-8) - torch.logsumexp(self.M(C, u, v), dim=-1)) + u # [num_gt + 1]
U, V = u, v
# Transport plan pi = diag(a)*K*diag(b)
pi = torch.exp(
self.M(C, U, V)).detach() # [num_gt + 1, num_anchor]
# Sinkhorn distance
cost = torch.sum(
pi * C, dim=(-2, -1))
pdb.set_trace()
return cost, pi
def M(self, C, u, v):
'''
"Modified cost for logarithmic updates"
"$M_{ij} = (-c_{ij} + u_i + v_j) / epsilon$"
'''
return (-C + u.unsqueeze(-1) + v.unsqueeze(-2)) / self.eps
@torch.no_grad()
def get_ground_truth(self, shifts, targets, box_cls, box_delta, box_iou):
gt_classes = []
gt_shifts_deltas = []
gt_ious = []
assigned_units = []
box_cls = [permute_to_N_HWA_K(x, self.num_classes) for x in box_cls]
box_delta = [permute_to_N_HWA_K(x, 4) for x in box_delta]
box_iou = [permute_to_N_HWA_K(x, 1) for x in box_iou]
box_cls = torch.cat(box_cls, dim=1)
box_delta = torch.cat(box_delta, dim=1)
box_iou = torch.cat(box_iou, dim=1)
# for each img
for shifts_per_image, targets_per_image, box_cls_per_image, \
box_delta_per_image, box_iou_per_image in zip(
shifts, targets, box_cls, box_delta, box_iou):
pdb.set_trace()
shifts_over_all = torch.cat(shifts_per_image, dim=0)
gt_boxes = targets_per_image.gt_boxes
# In gt box and center.
deltas = self.shift2box_transform.get_deltas(
shifts_over_all, gt_boxes.tensor.unsqueeze(1))
is_in_boxes = deltas.min(dim=-1).values > 0.01 # 判断points 是否再gt box内部
# center_sampling_radius
center_sampling_radius = 2.5
centers = gt_boxes.get_centers() # get_centers function
is_in_centers = []
# for each level in each img
for stride, shifts_i in zip(self.fpn_strides, shifts_per_image):
radius = stride * center_sampling_radius
# center_boxes
center_boxes = torch.cat((
torch.max(centers - radius, gt_boxes.tensor[:, :2]),
torch.min(centers + radius, gt_boxes.tensor[:, 2:]),
), dim=-1)
# center_deltas
center_deltas = self.shift2box_transform.get_deltas(
shifts_i, center_boxes.unsqueeze(1))
is_in_centers.append(center_deltas.min(dim=-1).values > 0)
is_in_centers = torch.cat(is_in_centers, dim=1)
del centers, center_boxes, deltas, center_deltas
# 同时收到is_in_boxes 和 is_in_centers 两种过滤
is_in_boxes = (is_in_boxes & is_in_centers)
num_gt = len(targets_per_image) # gt
num_anchor = len(shifts_over_all) # total pixels
shape = (num_gt, num_anchor, -1)
gt_cls_per_image = F.one_hot(
targets_per_image.gt_classes, self.num_classes
).float() # [num_gt, 80]
pdb.set_trace()
with torch.no_grad():
# 和match的方法有点类似,暂时认为所有的pixel都可能和gt对应
# OT的分类loss和最后网络的loss不太一样, 对于所有的pixel, 它是将分类中的gt类别和bg类别分别考虑。而不像之前的cls loss在一起计算。
loss_cls = sigmoid_focal_loss_jit(
box_cls_per_image.unsqueeze(0).expand(shape), # [2, 20267, 80]
gt_cls_per_image.unsqueeze(1).expand(shape), # [2, 20267, 80]
alpha=self.focal_loss_alpha,
gamma=self.focal_loss_gamma,
).sum(dim=-1) # [2, 20267]
loss_cls_bg = sigmoid_focal_loss_jit(
box_cls_per_image, # [20267, 80]
torch.zeros_like(box_cls_per_image),
alpha=self.focal_loss_alpha,
gamma=self.focal_loss_gamma,
).sum(dim=-1) # [20267]
# deltas --> l,t,r,b
gt_delta_per_image = self.shift2box_transform.get_deltas(
shifts_over_all, gt_boxes.tensor.unsqueeze(1)
)
ious, loss_delta = get_ious_and_iou_loss(
box_delta_per_image.unsqueeze(0).expand(shape),
gt_delta_per_image,
box_mode="ltrb",
loss_type='iou'
)
# 不在center的pixel loss add constant value:(1 - is_in_boxes.float()) refer to paper
loss = loss_cls + self.reg_weight * loss_delta + 1e6 * (1 - is_in_boxes.float()) # [num_gt, num_anchor]
# Performing Dynamic k Estimation
topk_ious, _ = torch.topk(ious * is_in_boxes.float(), self.top_candidates, dim=1)
mu = ious.new_ones(num_gt + 1) # [num_gt + 1]
mu[:-1] = torch.clamp(topk_ious.sum(1).int(), min=1).float()
mu[-1] = num_anchor - mu[:-1].sum()
nu = ious.new_ones(num_anchor) # [num_anchor]
loss = torch.cat([loss, loss_cls_bg.unsqueeze(0)], dim=0) # [num_gt + 1, num_anchor] eg.[3, 20267]
# Solving Optimal-Transportation-Plan pi via Sinkhorn-Iteration.
_, pi = self.sinkhorn(mu, nu, loss) # pi [num_gt + 1, num_anchor]
# Rescale pi so that the max pi for each gt equals to 1.
rescale_factor, _ = pi.max(dim=1)
pi = pi / rescale_factor.unsqueeze(1)
max_assigned_units, matched_gt_inds = torch.max(pi, dim=0)
gt_classes_i = targets_per_image.gt_classes.new_ones(num_anchor) * self.num_classes # [num_anchor]
fg_mask = matched_gt_inds != num_gt # fg_mask
gt_classes_i[fg_mask] = targets_per_image.gt_classes[matched_gt_inds[fg_mask]]
gt_classes.append(gt_classes_i)
assigned_units.append(max_assigned_units)
box_target_per_image = gt_delta_per_image.new_zeros((num_anchor, 4))
box_target_per_image[fg_mask] = \
gt_delta_per_image[matched_gt_inds[fg_mask], torch.arange(num_anchor)[fg_mask]]
gt_shifts_deltas.append(box_target_per_image)
gt_ious_per_image = ious.new_zeros((num_anchor, 1))
gt_ious_per_image[fg_mask] = ious[matched_gt_inds[fg_mask],
torch.arange(num_anchor)[fg_mask]].unsqueeze(1)
gt_ious.append(gt_ious_per_image)
pdb.set_trace()
return torch.cat(gt_classes), torch.cat(gt_shifts_deltas), torch.cat(gt_ious)