知识图谱补全-ProjE: Embedding Projection for Knowledge Graph Completion
ProjE: Embedding Projection for Knowledge Graph Completion阅读笔记
- background
- motivation
- model
- experiments
- conclusion
会议:Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17)
author :
Baoxu Shi and Tim Weninger
University of Notre Dame
Email: {bshi, tweninge}@nd.edu
background
1.图谱的发展,验证信息有效性和填补信息图谱缺失是很重要的
2.已有方法分成两类
2.1 表示学习,使用嵌入到低维向量,如tans系列(transE,transR),使用的是margin-based pairwise ranking loss fuction这个损失函数体现三元组的关系
2.2. 神经网络模型,如(Neural Tensot Network、the Compositional Vector Space Model)组合多层神经网络到现有模型中
存在的主要问题:
1.上述模型只用了一个三元组,路劲单跳的图谱。有个别扩展模型(RTransE,Usunier)实现了2-3跳。但是这些模型都依赖于丰富的输入数据。最重要的是随着路径的增长,模型大小指数型增长。加剧了模型参数已经很高的可伸缩性问题
2.上述模型大部分都不是一个self-contained model,他们或需要预训练的图谱嵌入(RTransE,CVSM),或需要预选择路径(PTransE,RTransE),或需要预计算的每个节点的内容嵌入(DKRL)。虽然TransE和TransH是self-contained的,但是论文的实验也只是用了预训练的TransE的嵌入作为输入
motivation
为解决上述的问题,本文的相关工作提出了四个亮点
提出一个project embedding model for KGC,四部分分别为:
1.将实体的候选集投影到输入数据的目标向量表示
2.使用可学习的组合算子将表示输入数据的嵌入向量组合成目标向量
3.集体优化了候选实体(关系)的集合,使用候选采样解决大数据集合。
4.本模型是一个self-contained 模型在长度为1的边上

对比了几个模型的参数量,本文模型排到了第五位。
model
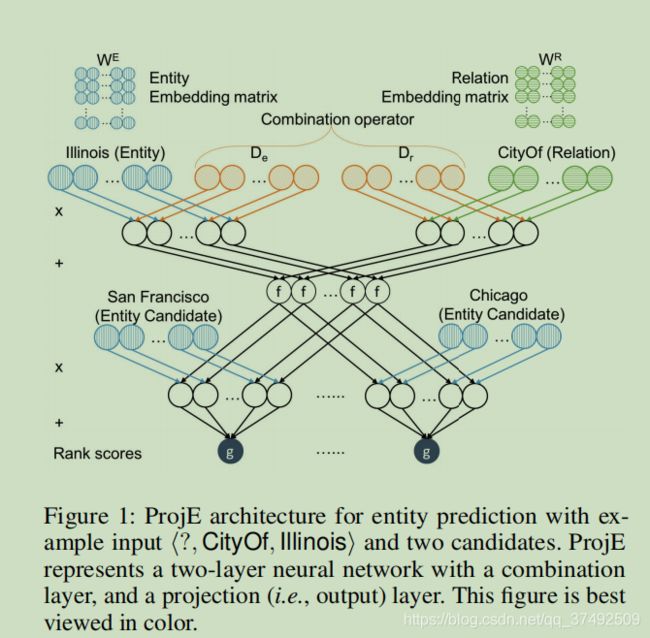
首先从一个图看下本文提出的模型,本文将补全任务视作排名任务并优化候选实体列表的集体分数。需要将所有的候选实体投影到同一嵌入向量中,为此学习了一个组合运算符,从输入数据中创建目标向量
1.ProjE框架
从图中我们可以看出来,同时输入实体嵌入和关系嵌入,本文将预测任务视作排名问题,将排名top的视作正确实体。为了生成排序列表,将每个实体投影到目标向量中通过两个输入向量组合运算符
现有模型中都是定义一个特定的矩阵运算符联合实体和(或)关系,本文认为在早期不同维度之间的特征没有必要交互,为此本文的组合元素运算符是对角矩阵,其定义为:
![]()
其中 D e D_{e} De 和 D r D_{r} Dr都是 k ∗ k k *k k∗k的对角矩阵,作为全局实体和关系的权重, b c ∈ R k b_{c}\in{R^k} bc∈Rk,是偏置。
使用了上述组合运算符,我们可以定义为嵌入投影函数为
![]()
其中 f f f和 g g g 都是激活函数, W c ∈ R s × k W^c \in{R^{s \times k}} Wc∈Rs×k 候选实体矩阵, b p b_{p} bp是投影偏置, s s s是候选实体的数量, h ( e , r ) h(e,r) h(e,r) 是分数向量 ,每个元素表示 W c W_{c} Wc中某些候选实体与组合输入嵌入 e ⊕ r e \oplus r e⊕r之间的相似性。
虽然 s s s相对来说是一个大的数,由于共享了参数, W c W_{c} Wc是包含实体嵌入矩阵 W e W_{e} We中存在的 s s s行的候选实体矩阵,简单的说候选实体矩阵没有引入新的变量参数,和TransE,TransR等类似,参数少。
ProjE可以看作神经网络包括组合层和投影层(输出层),举个例子,有一个尾实体lllinois和关系CityOf,我们的任务就是计算么个头实体的分数。
2.损失函数
传统有两种方法获得排序列表,一个是pointwise,一个是listwise。Trans家族使用的是pairwise ranking loss function。因为他们的排名分数是独立计算的,在本质上是pointwise方法,本文提出了两种方法,分别是ProjE_pointwise和ProjE_listwise通过使用不同的激活函数。
2.1 ProjE_pointwise
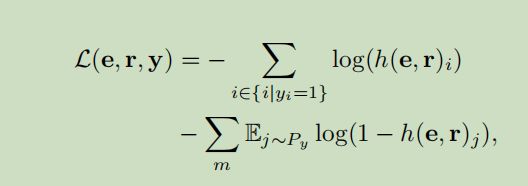
由于实体的相对顺序和预测无关,为此生成二进制标签向量,其中 E − E_{-} E−的分数为0, E + E_{+} E+分数为1,因为我们最大化似然函数在分数向量 h ( e , r ) h(e,r) h(e,r)和二进制标签向量,凭直觉将本任务视为多分类问题,为此损失函数定义为如上所示。
在式中 e , r e,r e,r是 S S S中训练实例的输入嵌入向量, y ∈ R s y\in{R^s} y∈Rs是二进制标签向量, y i = 1 y_{i}=1 yi=1说明候选 i i i是候选标签, m m m是从负候选分布中的候选采样数目,由于视作了多分类问题,使用sigmoid和tanh激活函数作为 g ( ⋅ ) g(·) g(⋅)和 f ( ⋅ ) f(·) f(⋅)
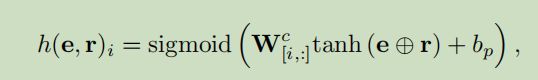
2.2 ProjE_listwise
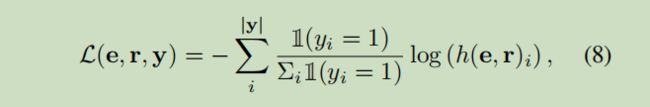
使用的是softmax和tanh激活函数

3.候选集采样
虽然限制了参数的数量,但是投影操作还是由于大量的候选实体而花销巨大,为了减少在训练阶段的候选实体数目,需要采样。本文采用Word2Vec中的负采样方法。
对于实体e和关系r以及二进制标签向量y,本文使用所有正候选人计算投影和只有来自 P y P_{y} Py的负候选人的抽样子集,为了简单起见,可以用二项分布替换 P y P_{y} Py。 B ( 1 , p y ) B(1,p_{y}) B(1,py)被所用训练实例共享, p y p_{y} py是负实体被采样的概率。对于 y y y中的每个负候选,我们从 B ( 1 , p y ) B(1,p_{y}) B(1,py)中采样一个值,以确定我们是否将该候选包含在候选实体矩阵 W c W_{c} Wc中。
experiments
做了两个实验,分别是实体预测和关系预测。实验结果从下面两张图可以看出来
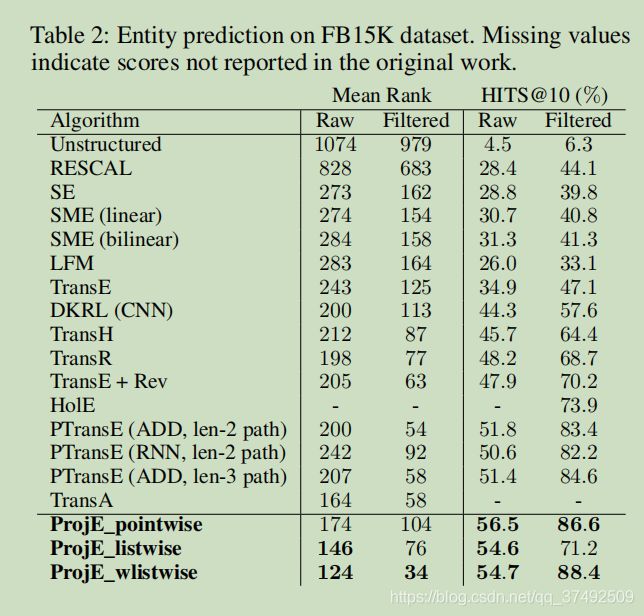
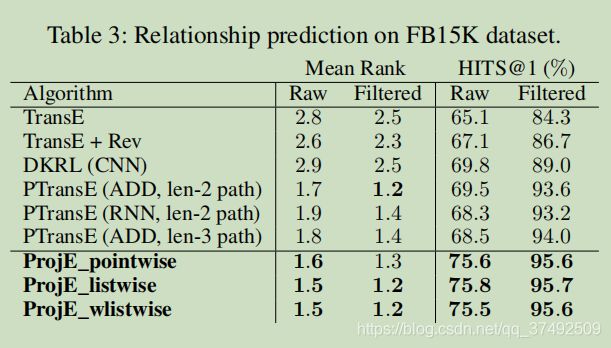
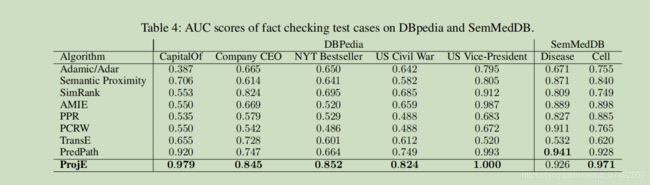
conclusion
本文的主要贡献归纳为如下几点
1.将图谱补全工作视为排序问题并将候选实体映射到一个向量上,该向量表示输入的三元组已知部分的组合嵌入,并按降序排列分数向量
2.通过使用listwise ProjE variation 集体优化排名分数向量,可以得到更好的预测表现
3.训练时只采用了路径为1,层数为2的简单结构就将预测结果优于复杂模型
4.当前模型不需要预训练的嵌入和更少的参数量