Python爬虫学习笔记_DAY_29_Python爬虫之scrapy框架项目结构与基本语法详细介绍【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I.scrapy框架的项目结构
II.robots协议
III.scrapy框架的基本语法介绍
I.scrapy框架的项目结构
承接上一篇笔记,开始学习scrapy框架的项目结构:
首先,我们可以先新建一个scrapy的项目(这里以获取58同 城网页数据为例):
我们先打开终端,cd指令进入上一篇笔记新建的文件夹中(或者任意新建一个空的文件夹也可以),在这个文件夹下,我们运行项目创建指令,创建新的项目:
输入scrapy项目创建指令:
scrapy startproject scrapy_58tc
接下来,跟第一篇笔记相似,我们通过终端进入项目文件夹下的spiders文件夹,并在这里生成我们的爬虫文件:
终端进入spiders文件夹指令:
cd scrapy_58tc/scrapy_58tc/spiders
接下来,在生成爬虫文件之前,我们需要获取目标网页的地址或接口,于是我们先访问58同 城的官网,并在搜索框中任意搜索一个工作岗位,这里以搜索【前端开发】为例:

之后点击‘同城搜索’,在搜索结果页面,按F12检查网页,并刷新一下网页,点击Network(网络)这一项,开始抓接口,很快,我们发现接口在下图圈红圈的那个文件中:

于是我们复制一下接口url,它是这样的:(由于58同城的接口带有地理位置信息,大家尽量按照自己的接口url进行复制,下面的url仅供参考!)
https://fz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=classify_A终端生成scrapy爬虫文件指令:
scrapy genspider tc https://fz.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpolicy=classify_A
注意,上面的指令运行后,将生成一个名为 tc.py 的爬虫文件,并且目标url是58同城【前端开发】岗位信息页。(上述指令运行后终端可能提示错误,但是其实是已经正常生成,大家不必理会报错信息!)
之后我们用pycharm打开整个58同 城项目文件,观察它的项目结构:
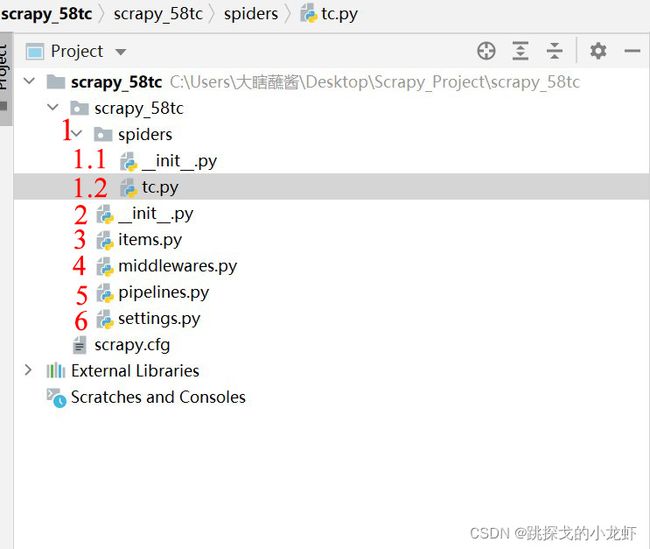
可以大致把项目文件夹下分出六个部分:
1️⃣ Spiders文件夹:这文件夹我们不陌生,因为每一次新建scrapy爬虫项目后,我们都需要终端进入Spiders文件夹,生产爬虫文件。在Spiders文件夹下,又有两个文件,一个是_init_.py文件,一个是tc.py。_init_.py文件是我们创建项目时默认生成的一个py文件,我们用不到这个py文件,因此我们可以忽略它,另一个tc.py文件是我们爬虫的核心文件,后续的大部分代码都会写入这个文件,因此它是至关重要的py文件。
2️⃣_init_.py文件:它和上面提到的Spiders文件夹下的_init_.py一样,都是不被使用的py文件,无需理会。
3️⃣ items.py文件:这文件定义了数据结构,这里的数据结构与算法中的数据结构不同,它指的是爬虫目标数据的数据组成结构,例如我们需要获取目标网页的图片和图片的名称,那么此时我们的数据组成结构就定义为 图片、图片名称。后续会专门安排对scrapy框架定义数据结构的学习。
4️⃣ middleware.py文件:这py文件包含了scrapy项目的一些中间构件,例如代理、请求方式、执行等等,它对于项目来说是重要的,但对于我们爬虫基础学习来说,可以暂时不考虑更改它的内容。
5️⃣ pipelines.py文件:这是我们之前在工作原理中提到的scrapy框架中的管道文件,管道的作用是执行一些文件的下载,例如图片等,后续会安排对scrapy框架管道的学习,那时会专门研究这个py文件。
6️⃣ settings.py文件:这文件是整个scrapy项目的配置文件,里面是很多参数的设置,我们会偶尔设计到修改该文件中的部分参数,例如下一部分提到的ROBOTS协议限制,就需要进入该文件解除该限制,否则将无法实现爬取。
II.robots协议
接下来介绍一个scrapy框架工作过程中的小知识点:robots协议,首先看看它是什么:
robots协议也叫robots.txt,是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
那么简而言之,robots协议就是规定了我们使用爬虫的范围,也被戏称君子协议。
在上一篇笔记中,我们用scrapy框架对baidu的主页生成了项目文件和爬虫文件,在笔记介绍运行的部分提到我们注释掉了项目文件settings.py中的 ROBOTSTXT_OBEY = True 这句代码,其实就是因为这句代码代表了我们选择遵循ROBOTS协议,那么我们就无法获取数据,因此我们需要注释掉这句话。(也即我们选择不遵守它)
下面我们可以选择打开之前对baidu主页生产的scrapy项目文件,打开settings.py文件,把 ROBOTSTXT_OBEY = True 这句代码''解除''注释:
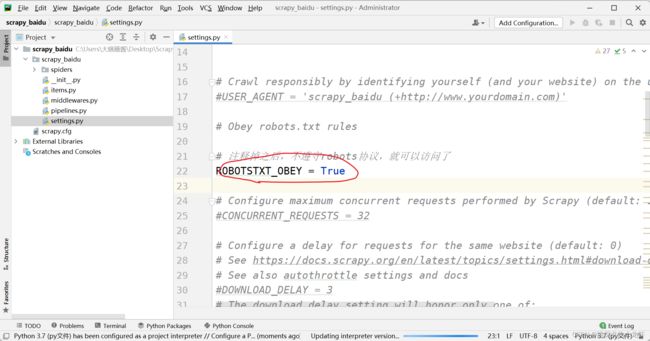
之后重新运行我们的爬虫文件:
scrapy crawl baidu在终端,我们可以看到运行的结果中,数据消失了,或者说没有拿到,而是提示了下面的错误信息:

因此,在使用scrapy框架的时候,我们在拿不到数据时,可以考虑是否是robots协议起到了作用,如果是这样,那就把 ROBOTSTXT_OBEY = True 这句代码注释即可!
III.scrapy框架的基本语法介绍
最后,我们对scrapy框架的基本语法做一个简单的汇总与介绍:
我们回到58同城的项目文件中,打开项目文件下的爬虫文件:tc.py:
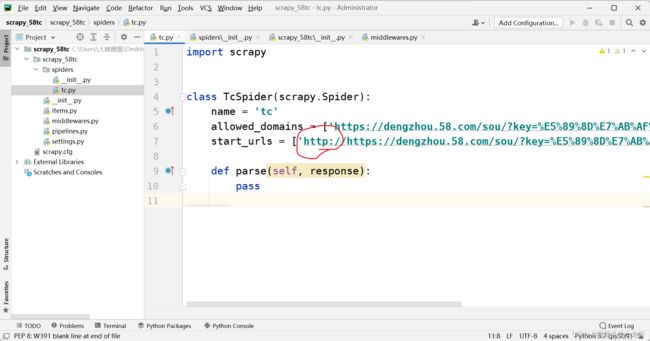
这里,首先我们把额外生产的https协议头去掉,只留下一个https://,即删去红圈内的部分。之后我们可以看到在class中,也即类中,有两个参数:allowed_domains和start_urls,这两个参数有不同的含义:
✳️ allowed_domains:这是scrapy框架中规定爬取的url的范围,简单地说就是,我们只能在这个参数定义的url的范围下获取数据,一旦数据超出范围,那么我们的请求将会失效。
✴️ start_urls:这是scrapy框架起始访问的url,也即在最初向这个url的位置发起请求。
在这个简单的项目中,这两个参数可以是同一个,在后续的项目中,对于两个参数,特别是第一个参数的设置,是有所讲究的。
之后我们的目光聚焦在下面的函数 parse(self,response) 中,这个函数是当我们发起请求成功后的一个回调函数,如果不理解回调函数的不要紧,我们只需要知道,这个函数的触发时机是请求已经被正确处理了。于是我们可以拿到函数的传参:response的值,而这个response的值就是服务器给我们的响应。针对这个response响应,有下面的基础操作:
def parse(self, response):
# (1) response.text属性:获取的是字符串形式的数据
content_str = response.text
print(content_str)
# (2) response.body属性:获取的是二进制形式的数据
content_b = response.body
print("====================")
print(content_b)
# (3) response.xpath()函数可以直接使用xpath解析
# (4) response.extract() 提取selector对象的属性值
# (5) response.extract_first() 提取selector列表的第一个数据
pass可以看到,一共有五个基础的response处理,其中比较重要的是最后三个处理方式:
1️⃣ response.xpath(xpath语句传入):这种方式是对response进行xpath解析,我们在括号内传入xpath语法对应的语句即可,要注意的是,普通的xpath解析,返回的是一个列表,但是在scrapy框架中的xpath解析,返回的是selector对象列表,针对selector对象列表,我们需要进一步的处理,才能真正拿到数据。
2️⃣ response.extract():这种处理,承接了上面的操作,当我们拿到了selector对象列表,通过再执行.extract()函数,即可把selector对象列表转成普通的列表,进而获取数据。
3️⃣ response.extract_first():这是第二种方法的加强版本,可以直接拿到转成的普通列表的第一个元素,在一些情况下更方便。
也就是说,我们通常情况下,拿数据是这样的一句代码:
data = response.xpath(''xpath - - - - -'').extract()/.extract_first()
关于五种response的处理,后续的笔记进行进一步的实战说明!