CatBoost自动调参—Optuna和Hyperopt耗时和效果对比
1、摘要
本文主要讲解:Optuna和Hyperopt性能对比
2、数据介绍
如需数据请私聊
3、相关技术
optuna主要的调参原理如下:
1 采样算法(随机搜索)
利用 suggested 参数值和评估的目标值的记录,采样器基本上不断缩小搜索空间,直到找到一个最佳的搜索空间,其产生的参数会带来更好的目标函数值。
2 剪枝算法
自动在训练的早期(也就是自动化的 early-stopping)终止无望的 trial
Hyperopt主要的调参原理如下:
hyperopt是一个Python库,主要使用①随机搜索算法/②模拟退火算法/③TPE算法来对某个算法模型的最佳参数进行智能搜索,它的全称是Hyperparameter Optimization。
4、完整代码和步骤
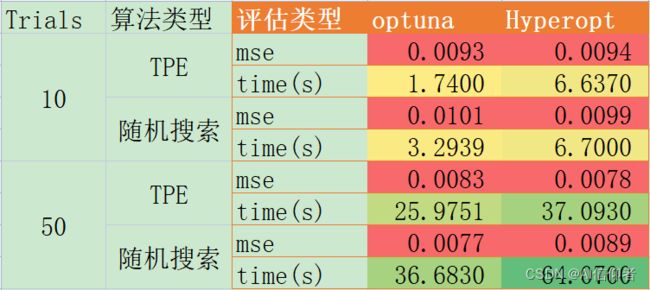
最终测试结果如下:
optuna程序入口
import os
import time
import optuna
import pandas as pd
from catboost import CatBoostRegressor
from sklearn.metrics import r2_score, mean_squared_error
from sklearn.model_selection import train_test_split
os.chdir(r'D:\项目\PSO_CATBOOST\\')
src = r'D:\项目\PSO_CATBOOST\\'
file = 'shuju.xlsx'
data = pd.read_excel(file)
X_train = data.drop(['label', 'b1', 'b2'], axis=1).values
y_train = data['label'].values
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
def epoch_time(start_time, end_time):
elapsed_secs = end_time - start_time
elapsed_mins = elapsed_secs / 60
return elapsed_mins, elapsed_secs
def objective(trial):
# 自定义的参数空间
depth = trial.suggest_int('depth', 1, 16)
border_count = trial.suggest_int('border_count', 1, 222)
l2_leaf_reg = trial.suggest_int('l2_leaf_reg', 1, 222)
learning_rate = trial.suggest_uniform('learning_rate', 0.001, 0.9)
iterations = trial.suggest_int('iterations', 1, 100)
estimator = CatBoostRegressor(loss_function='RMSE', random_seed=22, learning_rate=learning_rate,
iterations=iterations, l2_leaf_reg=l2_leaf_reg,
border_count=border_count,
depth=depth, verbose=0)
estimator.fit(X_train, y_train)
val_pred = estimator.predict(X_test)
mse = mean_squared_error(y_test, val_pred)
return mse
""" Run optimize.
Set n_trials and/or timeout (in sec) for optimization by Optuna
"""
study = optuna.create_study(sampler=optuna.samplers.TPESampler(), direction='minimize')
# study = optuna.create_study(sampler=optuna.samplers.RandomSampler(), direction='minimize')
start_time = time.time()
study.optimize(objective, n_trials=10)
end_time = time.time()
elapsed_mins, elapsed_secs = epoch_time(start_time, end_time)
print('elapsed_secs:', elapsed_secs)
print('Best value:', study.best_trial.value)
Hyperopt代码如下
import os
import time
import pandas as pd
from catboost import CatBoostRegressor
from hyperopt import fmin, hp, partial, Trials, tpe,rand
from sklearn.metrics import r2_score, mean_squared_error
from sklearn.model_selection import train_test_split
# 自定义hyperopt的参数空间
space = {"iterations": hp.choice("iterations", range(1, 100)),
"depth": hp.randint("depth", 16),
"l2_leaf_reg": hp.randint("l2_leaf_reg", 222),
"border_count": hp.randint("border_count", 222),
'learning_rate': hp.uniform('learning_rate', 0.001, 0.9),
}
os.chdir(r'D:\项目\PSO_CATBOOST\\')
src = r'D:\项目\PSO_CATBOOST\\'
file = 'shuju.xlsx'
data = pd.read_excel(file)
X_train = data.drop(['label', 'b1', 'b2'], axis=1).values
y_train = data['label'].values
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
def epoch_time(start_time, end_time):
elapsed_secs = end_time - start_time
elapsed_mins = elapsed_secs / 60
return elapsed_mins, elapsed_secs
# 自动化调参并训练
def cat_factory(argsDict):
estimator = CatBoostRegressor(loss_function='RMSE', random_seed=22, learning_rate=argsDict['learning_rate'],
iterations=argsDict['iterations'], l2_leaf_reg=argsDict['l2_leaf_reg'],
border_count=argsDict['border_count'],
depth=argsDict['depth'], verbose=0)
estimator.fit(X_train, y_train)
val_pred = estimator.predict(X_test)
mse = mean_squared_error(y_test, val_pred)
return mse
# 算法选择 tpe
algo = partial(tpe.suggest)
# 随机搜索
# algo = partial(rand.suggest)
# 初始化每次尝试
trials = Trials()
# 开始自动参数寻优
start_time = time.time()
best = fmin(cat_factory, space, algo=algo, max_evals=10, trials=trials)
end_time = time.time()
elapsed_mins, elapsed_secs = epoch_time(start_time, end_time)
print('elapsed_secs:', elapsed_secs)
all = []
# 遍历每一次的寻参结果
for one in trials:
str_re = str(one)
argsDict = one['misc']['vals']
value = one['result']['loss']
learning_rate = argsDict["learning_rate"][0]
iterations = argsDict["iterations"][0]
depth = argsDict["depth"][0]
l2_leaf_reg = argsDict["l2_leaf_reg"][0]
border_count = argsDict["border_count"][0]
finish = [value, learning_rate, iterations, depth, l2_leaf_reg, border_count]
all.append(finish)
parameters = pd.DataFrame(all, columns=['value', 'learning_rate', 'iterations', 'depth', 'l2_leaf_reg', 'border_count'])
# 从寻参结果中找到r2最大的
best = parameters.loc[abs(parameters['value']).idxmin()]
print("best: {}".format(best))
如需帮忙请私聊
5、学习链接
optuna自动调参框架对lgb的超参进行优化
NNI使用python文件直接启动参数调优