【论文阅读】A Survey on Contrastive Self-supervised Learning
论文地址:https://arxiv.org/abs/2011.00362
介绍
有监督的方法的问题:
1、需要昂贵的标记数据
2、泛化性能差
3、遭受对抗攻击
大量的方法开始寻找不需要大量昂贵的标记的方法,通过自监督来学习特征表示
随着2014年GAN被提出,有许多基于GAN的自监督的生成模型,但是GAN也存在问题:
1、模型参数比较振荡,很难收敛
2、判别器通常比生成器训练得更好,使得生成器很难生成逼真的样本
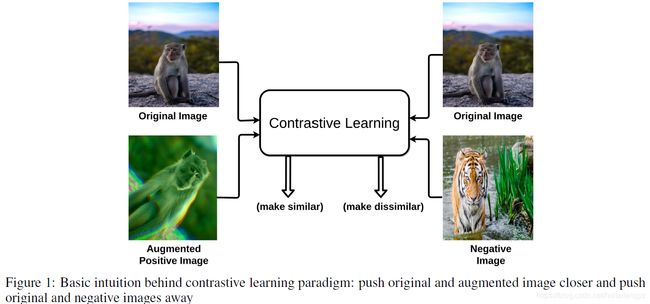
对比学习是一种判别方法,旨在将相似样本靠近,将不同的样本之间距离增大
方法是使用一种相似度度量来评价两个embedding有多相近
在CV任务中,对比损失基于图像经过encoder抽取的特征表示来进行计算
训练流程如下图:

对于一张原图像,其经过数据增广后的图像作为正样本,同个batch中的其他样本作为负样本
通过一些前置任务(pretext task)来学会区分正样本和负样本
早期工作将一些实例级的分类任务作为前置任务,最近的工作(SwAV、MoCo、SimCLR)使用一些改进的方法,取得了和SOTA的有监督方法相似的性能

前置任务
前置任务:使用伪标签通过自监督来学习数据的特征表示
伪标签通过数据中发现的属性自动生成
原始图像作为anchor,增广图像作为正样本,同batch中其他样本作为负样本
常用的前置任务可以分为四类:颜色变换、几何变换、基于上下文的任务、跨模态任务
颜色变换

模糊、颜色变形、转换为灰度图像
网络学习去识别对于颜色不变的相似图像
几何变换

一种空间变换,图像的几何信息被改变,但是不改变实际的像素信息
缩放、随机裁剪、翻折(水平、垂直)
基于上下文
拼图
原始图像作为anchor,打乱顺序后的原始图像作为正样本,同batch中其他图像作为负样本

帧顺序
1、一个视频中将帧的顺序打乱后作为正样本,将batch中其他视频作为负样本
2、从一段长视频中截取两端长度相等的片段作为一对样本
3、对每个视频片段采用空间增广
目标:训练模型是的同一段视频中裁出的不同片段间距离更加接近,不同片段
预测未来
给定一系列过去时刻的信息,预测未来的高层语义信息

视角预测(跨模态)
对于同一场景中,图像有多个视角的数据更适合
anchor和正样本来自同一物体在不同视角下同一时刻的图像,负样本则为该图像其他时刻的图像
模型希望同时能够确认来自不同角度的帧直接的相似特征,以及学习到同一序列中不同帧之间的差异

确定正确的前置任务
在对比学习中,前置任务的正确选择很重要
数据增广会带有一定的bias,有可能是一把双刃剑
例如在检测照片是否朝上的任务中,旋转的增广就是无效的,例如在下面的例子中,基于颜色的增广也是无效的

架构
将不同方法按照收集负样本的方式的不同可以分为以下四类

端到端训练
使用gradient-based学习,所有模块都可微
这种架构更偏好大的batchsize来积累更多的负样本
pipeline中包含两个不同的encoder:Query encoder(Q)和Key encoder(K)
主要的目的是希望两个encoder学习到同一个样本的不同表示
训练时将原始样本送入Q,其余正负样本均送入K,并使用相似度度量(一般为余弦相似度)来进行优化
SimCLR使用4096的batchsize,训练了100个epoch,发现大batch size和更多的epoch对模型效果都有提升
但是大的batchsize一方面需要更大的GPU内存,一方面会遇到优化问题
使用memory bank
目标:在训练中将前面使用过的大量样本的特征表示作为负样本
构建一个字典,来保存和更新最近见过的样本的embedding
memory bank (M)包含数据集D中每个样本I的特征表示m_I,并将每个epoch中对其使用指数平滑进行更新
通过这种方法,可以不再需要负样本采样,而直接使用memory bank中的表示
但是memory bank方法需要大量的计算来实时memory bank中的特征表示
使用冲量encoder(Momentum Encoder)
生成字典队列,将当前batch的特征入队,将最老的batch的样本出队
momentum encoder和encoder Q共享参数,并不在反向传播时更新,而是使用query encoder的参数进行momentum更新
![]()
因此只有query encoder在反向传播时更新![]()
这种方法的优点:
1、不需要同时训练两个不同的encoder
2、不再需要维护一个高计算量和内存使用的memory bank
聚类特征表示
前面三种都是instance-based的对比学习,这种是clustering-based的方法
使用两个共享参数的encoder进行end-to-end训练,使用聚类算法将相似的特征进行分组
目标是在将一对正样本相互靠近的同时,希望其他样本中相似特征可以相互聚类
instance-based方法的问题:假设正样本是一只猫,负样本中有别的猫,也有别的类别的图像,instance-based的方法会让这两只猫的特征也相互远离,但是并不合理

编码器
最常用的是ResNet-50模型,因为兼顾了网络大小和网络学习能力
一般使用网络中间层的特征,再对每个通道进行average pool至一维,从而得到n-dim的特征表示
有实验表明,抽取encoder后面阶段的特征能够学到更好的表示
训练
损失函数
最常用的相似度度量是余弦相似度:
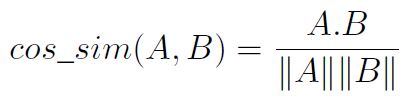
对比学习使用Noise Contrastive Estimation(NCE)来比较不同样本的embedding:

其中q为原始样本,k+为正样本,k-为负样本
NCE最初的动机是进行一个非线性logistic regression,能够判别观察到的数据和其他生成的噪声
当负样本非常多时,变种为InfoNCE:

对比学习在训练过程中,通过最小化损失函数来学习encoder网络的参数
优化器
对比学习中常用的优化器为SGD和Adam
当batch size很大时,使用学习率线性衰退的标准SGD方法优化会不稳定,因此采用Layer-wise
Adaptive Rate Scaling(LARS)方法
LARS与其他方法(比如Adam)的区别:
1、LARS每层使用不同的学习率
2、更新的幅度基于weight norm
3、使用阶段性warm restart的consine learning rate
下游任务
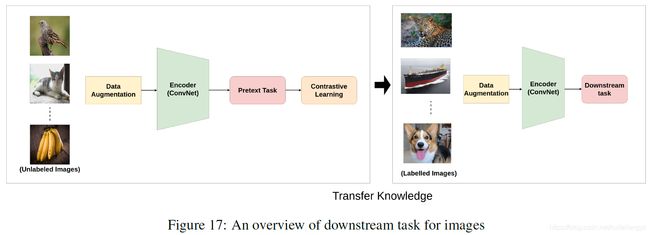
先使用前置任务用对比学习的方法预训练模型,然后将其作为初始化,在具体的下游任务(分类、检测、分割、未来预测等)中进行finetune
为了评估自监督学到特征的有效性,通常使用卷积核可视化、特征图可视化、最近邻方法等来进行分析前置任务的有效性
可视化卷积核和特征图
比较有监督和自监督训练模型的卷积核或者特征图

最临近邻居检索
同一类的图像希望它们的特征在隐空间内相近,因此可以对某个样本使用top K检索,看最临近的特征是否与其是同类
Benchmarks
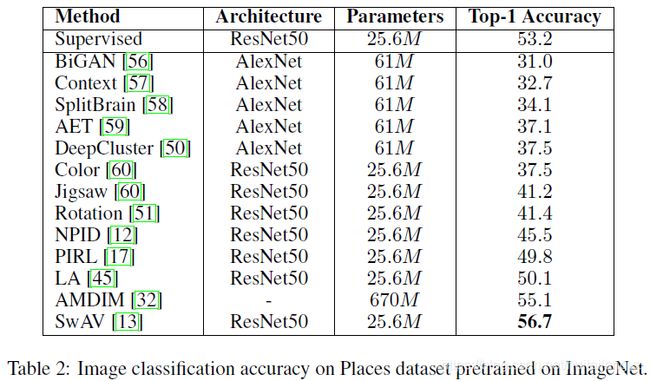
图像分类:在ImageNet上预训练,然后使用线性分类器在Places上finetune
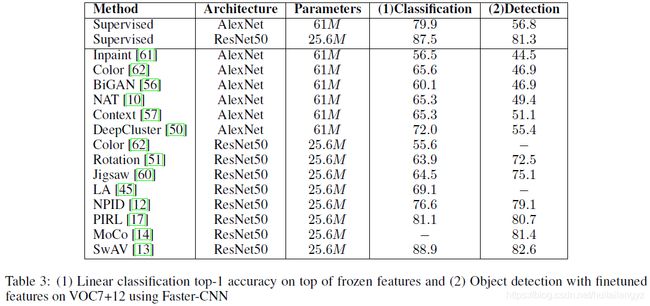
线性分类:在VOC7上进行预训练,然后将特征再使用一个线性分类器进行finetune
目标检测;在VOC7预训练后,使用Faster-RCNN在VOC7+12上进行finetune
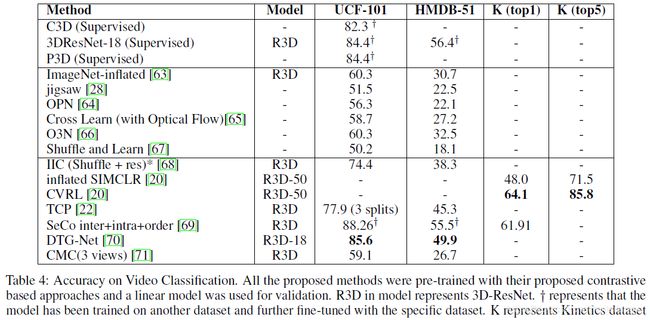
视频分类:先在数据集上进行预训练,然后使用一个线性分类器进行finetune后进行评估
NLP中的对比学习

讨论和未来方向
缺乏理论基础
尝试研究对比目标函数的泛化性时,发现架构设计和采样方法对性能有深远的影响
Tsai等人从多视角嫉妒的提供了信息理论框架来理解鼓励自监督学习的性质,说明了不同方法高度依赖前置任务的选择
有必要对对比学习框架中不同模块的理论分析
数据增广和前置任务的选择
PIRL强调不论选择的前置任务,模型都能得到一致的结果
SimCLR和MoCo-v2说明选择鲁棒的前置任务和合适的数据增广可以大大提高特征表示的质量
SwAV则通过多样的增广方式打败了其他方法
因此很难比较这些方法来选择最好的前置任务和增广方法
训练时适当的负采样
当负样本比较简单(与原始样本的相似度很低)时,对比损失的帮助有限
Kalantidis等提出了包含少量困难负样本的混合策略来促进快速更好的训练,但是这也带来了许多的超参,很难泛化到其他数据集
数据集bias
不同数据集本身会带来一定的bias,而且很难通过增大数据集大小来减少bias