MobileNet-V2理解以及pytorch源码实现
1.原理和创新点
-
整个网络中,主要有以下两种sequence。当s=1 , 同时 k=k撇, 也就是输入channel = 输出channel 时候,需要加一个shortcut
-
中间的3x3conv,采用的是群组卷积的特例, DepthWise Conv,此时
gropus = hidden_channel -
论文中提出,当维度较低时,应该采用线性激活函数,
-
高维时,采用ReLU6激活函数。丢失信息较少
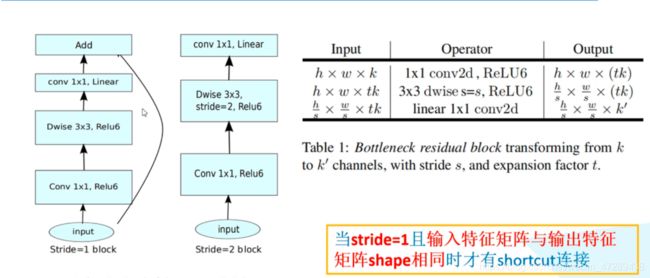
针对网络的参数表格,主要有以下几点: -
当一个
sequence重复多次时( 即n>1 ),只有第一个layer的stride=s(从图1中的表格可以看出,conv3x3的步长才为s,其他的均设置为1),剩下的所有layer的所有conv步长都设置为1。 当stride != 1,宽和高会发生改变 -
同一个
sequence中,后面的每个layer都有扩张因子t。并且输入channel = 输出 channel = c 。仍然要遵从图1表格的规律 -
图二中最后一行operator操作
conv2d 1x1实际上当作Linear()就行 -
在图二中第三行,t=1的,此时既没有升维也没有降维,因而可以把该layer中的第一个conv1x1直接丢弃就行。
满足第9点
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
# 这里继承是来源于nne.Sequential
# 而不是nn.Module
class ConvBNReLU(nn.Sequential):
# 此处的groups恰好,方便设置DW卷积
# conv2d中,不使用偏差bias
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
"""
conv1x1 in_channel ——> hidden_channel (t ReLU6)
conv3x3 hidden_channel ——> hidden_channel (group = hidden_channel)
conv1x1 hidden_channel ——> out_channel (线性)
从layers.append() 和 layers.extend()里面的ConvBNReLU的参数可以看出
第一个和第三个卷积kernel_size设定为1
第二个则传递进去kernel_size = s
"""
layers = []
# 这里的意思就是说, 如果 t=1 ,那么第一个卷积层就不采用1x1conv 。因为没有升维或者降维
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)

在实现图2表格时,要遵从上面列举的5、6两点。因而如下:
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
"""
下面的就是设置不同layer的步长, 也就是说说,只有i=0 才传递了stride = s
其他layers 的 stride=1
并且,这个stride 仅仅是针对每一个layer的conv3x3卷积 ,宽和高可能会改变的
"""
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
2.完整代码
from torch import nn
import torch
# 出于效率考量? 每个都能被8整除 ?
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
# 在min_ch 和 int() 结果中取最大的
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%. 确保向下取整减少不会超过10%
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
# 这里继承是来源于nne.Sequential
# 而不是nn.Module
class ConvBNReLU(nn.Sequential):
# 此处的groups恰好,方便设置DW卷积
# conv2d中,不使用偏差bias
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
"""
这个直接敲击,并不会出现类似上面的super里的结构
class ConvCl(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
super(ConvCl, self).__init__()
"""
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
"""
conv1x1 in_channel ——> hidden_channel (t ReLU6)
conv3x3 hidden_channel ——> hidden_channel (group = hidden_channel)
conv1x1 hidden_channel ——> out_channel (线性)
"""
layers = []
# 这里的意思就是说, 如果 t=1 ,那么第一个卷积层就不采用1x1conv 。因为没有升维或者降维
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
# 正态分布,均值为0,方差为0.01
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x