浅谈匹配网络
论文:[1606.04080] Matching Networks for One Shot Learning (arxiv.org)
时间:NIPS 2016
最近在读《Matching Networks for One Shot Learning》这篇文章,里面好多内容有些疑问,以下参考博客并结合自己的理解,可能有些地方存在问题,希望大家多多指正。每天学一点知识,你将变得更优秀哒。
N-way-K-shot任务
N-way-K-shot任务就是将任务 划分为N个类别(way),每个类别的支持集(support set)包含K个样本,任务中剩余的样本作为该任务的验证集(query set).其中每个"任务"包含支持集(support set)和验证集(query set)
划分为N个类别(way),每个类别的支持集(support set)包含K个样本,任务中剩余的样本作为该任务的验证集(query set).其中每个"任务"包含支持集(support set)和验证集(query set)

匹配网络
目的:提供一个网络框架,能将少量数据集和未标记的实例映射到所属标签,避免通过微调已训练好的模型来适应新类
创新点:结合度量学习和记忆增强神经网络的新型神经网络结构----匹配网络
对于少量数据集而言,模型在拟合数据时,可能会产生过拟合问题 ,这个问题可使用正则化和数据增强方式来缓和。但这些都是治标不治本。训练样本需要被参数模型通过梯度下降对参数进行更新,使得学习速率比较缓慢。对于许多非参数模型能快速同化新的实例并且不会遭受遗忘。作者结合参数模型和非参数模型来获取新的实例,提高模型的泛化能力。作者从注意力的序列到序列(seq2seq)、记忆网络以及指针网络中获得灵感。提出了匹配网络,它利用注意力机制和记忆机制加速学习,实现在少量数据的条件下对无标签的实例进行标签预测。
符合定义:支持集![]() ,预测类别的图像为
,预测类别的图像为
算法理论:
1.基于余弦距离的注意力机制
通过余弦距离计算训练实例![]() 与测试实例之间的相似度,通过softmax对相似度进行归一化后得到测试实例在训练样本
与测试实例之间的相似度,通过softmax对相似度进行归一化后得到测试实例在训练样本![]() 上的注意力分布a(,
上的注意力分布a(,![]() ).
).
![]()
其中,嵌入函数g和f的作用是将![]() 和嵌入(embadding)到空间中(特征提取)
和嵌入(embadding)到空间中(特征提取)
模型的输出 :
:
![]()
2.Full Context Embeddings


1.训练集嵌入函数g
首先,通过一个普通的网络(VGG等)对支持集中训练样本的每个样本进行原始特征提取,记为![]()
然后,采用一个双向LSTM模型,为每个训练实例![]() 设置四个状态量,分别是
设置四个状态量,分别是
| 隐状态 | 记忆细胞 | |
| 前向 | ||
| 后向 |
前向隐状态![]() 和
和![]() ,由前一个训练实例
,由前一个训练实例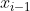 的隐状态和记忆细胞通过LSTM模型确定:
的隐状态和记忆细胞通过LSTM模型确定:
![]()
后向隐状态![]() 和
和![]() ,由前一个训练实例
,由前一个训练实例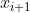 的隐状态和记忆细胞通过LSTM模型确定:
的隐状态和记忆细胞通过LSTM模型确定:
![]()
支持集的特征由前后隐状态和原始特征共同决定:
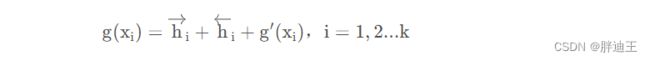
函数g特征提取时不仅考虑原始特征![]() 还考虑该训练样本和支持集中的其他样本有某种相关性
还考虑该训练样本和支持集中的其他样本有某种相关性
2.测试集嵌入函数f
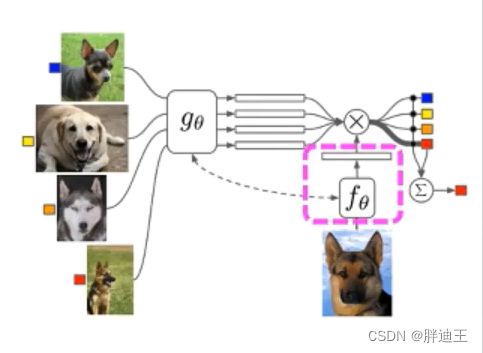
 首先,通过一个普通的网络对测试集的单个样本进行特征提取,记为
首先,通过一个普通的网络对测试集的单个样本进行特征提取,记为![]()
然后,采用一个注意力机制的LSTM模型(attLSTM),为每个测试实例 设置四个状态量,分别是隐状态
设置四个状态量,分别是隐状态![]() ,
,![]() ,记忆细胞
,记忆细胞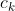 ,、read-out
,、read-out .k在论文中表示该进程块完成任务所需的处理步骤
.k在论文中表示该进程块完成任务所需的处理步骤
- 将k-1步的隐状态、记忆细胞、和第k-1次的read-out 通过LSTM模型获得此时的处理步骤k的隐状态
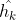 和记忆细胞:
和记忆细胞: 
2. 获得当前时刻测试样本的隐状态
![]()
3. 获得训练集的特征的加权和记为read-out
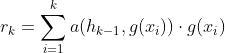
其中![]()
4. 将作为测试样本的特征
![]()
隐状态h决定了把注意力应该放在哪一些支持集的样本上。
以上介绍的两个嵌入函数g和f是论文中提到的Full Context Embeddings的两个部分。
训练策略
对一个任务T和带标签的数据L,每个任务中最多包含5类,每一类最多含有5张图片。
训练流程:

- 选择少数几个类别,为每个类别选择少量样本
- 从选出的集合中划分支持集S和测试集Q
- 通过本次迭代的支持集S来计算测试集上的误差
- 计算梯度,更新参数
整个过程被称为episode.匹配网络主要是减少测试集B在支持集S上的分类损失


训练完成后,在 novel 类别中再抽样出 S' 和 T',再调用 θ 完成分类任务,当 T' 与 T 相差较大时效果不好。关键的是,匹配网络不需要对它从未见过的类进行任何微调,因为它的非参数性质
实验:
对比模型有原始像素匹配,Baseline Classifier(鉴别特征匹配),MANN,Convolutional Siamese Net。其中Baseline Classifier中的图像分类是训练数据集中的原始类,但排除N个类。然后在最后一层(在softmax之前)的特征进行最近邻匹配
本文在使用时,添加了90°为倍数的4种旋转,进一步扩展类别数。使用其中的1200 4类字符作为训练,剩余4234类作为测试

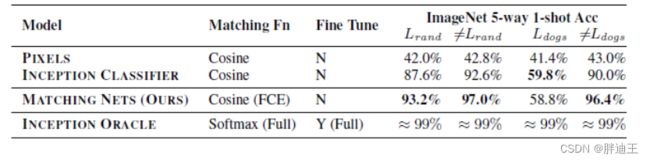
匹配网络的性能超过baselines ,即使对baselines的S'上进行微调后,无论是使用余弦距离还是softmax,baselines的泛化也很好

ImageNet
miniImageNet:选择100类,80类训练,20类测试。每类包含600张84*84的彩色图像。

randImageNet:随机选择118类作为测试集;剩余类作为训练集。
dogsImageNet:选择dogs的118个子类作为测试集;剩余类作为训练集。
结论:
如果训练网络进行 one-shot,那么 one-shot 会容易得多。
神经网络中的非参数结构使网络更容易记忆和适应相同任务中的新数据集
缺点:随着支持集S的大小增长,每个梯度更新的计算变得更加昂贵
参考来源
【平价数据】One Shot Learning_shenxiaolu1984的博客-CSDN博客
Part7 _ Matching Networks_哔哩哔哩_bilibili(有几张的图片来源于该视频)