浅谈常见的基础神经网络
LeNet:
基本结构:INPUT输入层、C1卷积层、S2池化层、C3卷积层、S4池化层、C5卷积层、F6全连接层、Output全连接层。
INPUT层,一般图像输入3232,本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。卷积层C1,对输入图像进行第一次卷积运算(使用 6 个大小为 55 的卷积核),得到6个C1特征图(6个大小为2828的 feature maps, 32-5+1=28)。卷积核的大小为55,总共就有6*(55+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的55个像素和1个bias有连接,所以总共有1562828=122304个连接。池化层S2,采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid。卷积之后紧接着就是池化运算,使用 22核 进行池化,于是得到了S2,6个1414的 特征图(28/2=14)。S2这个pooling层是对C1中的22区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。于是每个池化核有两个训练参数,所以共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。C3层,输入:S2中所有6个或者几个特征map组合,卷积核大小:55,卷积核种类:16,输出featureMap大小:1010 (14-5+1)=10。
S4是pooling层,窗口大小仍然是22,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。
C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:

F6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。
Output全连接层,采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
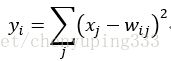
LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。
AlexLet:
是深度学习发展史上的一个重要里程碑,在2012 ILSVRC test set上top1错误率37.5%,top5错误率17.0%。
特征:
1 8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。
2 将sigmoid激活函数改成了更加简单的ReLU激活函数。
3 用Dropout来控制全连接层的模型复杂度。
4 引入数据增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合。
5 局部响应归一化层
6 解决过拟合,
数据增强的两种方式: (1)平移翻转(2) 改变rgb的通道的强度。
dropout :
Dropout是一种Bagging的近似,在训练时,每次Dropout后,训练的网络是整个深度神经网络的其中一个子网络。在测试时,将dropout层取消,这样得到的前向传播结果其实就是若干个子网络前向传播综合结果的一种近似。
learning rate decay 随着训练的进行,逐渐减小学习率。
7 池化操作提取的是一小部分的代表性特征,减少冗余信息
网络结构:
总共8层,5个卷积层,3个全连接层,实际最后1000个节点后面实际上还有一个softmax层。第2个,第4个和第5个卷积层只和同一个GPU上前一个卷积层相连,第3个卷积层和第2个卷积层所有的神经元互相连接,第1层和第2层后面有LRN,第1,第2和第5层后面有最大池化,激活函数全部使用ReLUs。

VGGNet:
VGG在AlexNet基础上做了改进,整个网络都使用了同样大小的33卷积核尺寸和22最大池化尺寸,网络结果简洁。
VGG模型的结构图:
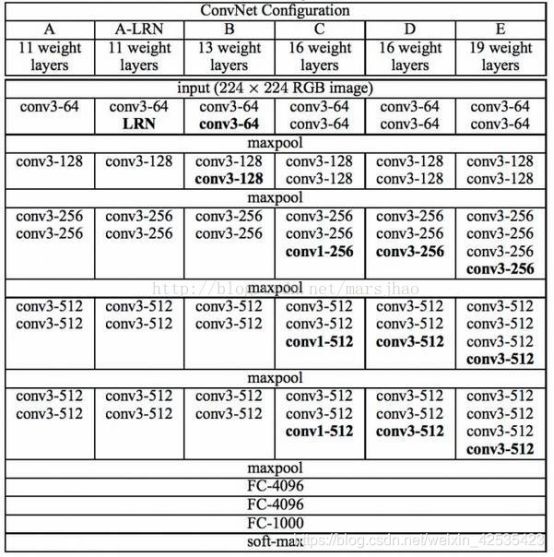
conv3-64 :是指第三层卷积后维度变成64,conv3-128指的是第三层卷积后维度变成128;
input(224x224 RGB image) :指的是输入图片大小为224 * 244的彩色图像,通道为3,即224 * 2243;
maxpool :是指最大池化,在vgg16中,pooling采用的是22的最大池化方法;
FC-4096 :指的是全连接层中有4096个节点,FC-1000为该层全连接层有1000个节点;
padding:指的是对矩阵在外边填充n圈,padding=1即填充1圈,5X5大小的矩阵,填充一圈后变成7X7大小;
vgg16每层卷积的滑动步长stride=1,padding=1,卷积核大小为3 * 3 *3;
VGG网络结构:

conv3 - 64(卷积核的数量):kernel size:3 stride:1 pad:1
像素:(224-3+21)/1+1=224 22422464
参数: (333)64 =1728
conv3 - 64:kernel size:3 stride:1 pad:1
像素: (224-3+12)/1+1=224 22422464
参数: (3364)64 =36864
pool2 kernel size:2 stride:2 pad:0
像素: (224-2)/2 = 112 11211264
参数: 0
conv3-128:kernel size:3 stride:1 pad:1
像素: (112-3+21)/1+1 = 112 112112128
参数: (33*64)*128 =73728

VGG16包含16层,VGG19包含19层。一系列的VGG在最后三层的全连接层上完全一样,整体结构上都包含5组卷积层,卷积层之后跟一个MaxPool。所不同的是5组卷积层中包含的级联的卷积层越来越多。
AlexNet中每层卷积层中只包含一个卷积,卷积核的大小是77,。在VGGNet中每层卷积层中包含2~4个卷积操作,卷积核的大小是33,卷积步长是1,池化核是2*2,步长为2,。VGGNet最明显的改进就是降低了卷积核的尺寸,增加了卷积的层数。
使用多个较小卷积核的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面作者认为相当于进行了更多的非线性映射,增加了网络的拟合表达能力。
特点:
使用了更小的33卷积核,和更深的网络。两个33卷积核的堆叠相对于55卷积核的视野,三个33卷积核的堆叠相当于77卷积核的视野。这样一方面可以有更少的参数(3个堆叠的33结构只有77结构参数数量的(333)/(77)=55%);另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
在VGGNet的卷积结构中,引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
残差resnet
残差块的结构如下图:

它对每层的输入做一个reference(X), 学习形成残差函数, 而不是学习一些没有reference(X)的函数。这种残差函数更容易优化,能使网络层数大大加深。在上图的残差块中它有二层,如下表达式,
其中σ代表非线性函数ReLU。
比如说梯度下降法,或者其它热门的优化算法。如果没有残差,没有这些捷径或者跳跃连接,凭经验你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对。也就是说,理论上网络深度越深越好。但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练。实际上,随着网络深度的加深,训练错误会越来越多。
但有了ResNets就不一样了,即使网络再深,训练的表现却不错,比如说训练误差减少,就算是训练深达100层的网络也不例外。这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。
残差块:
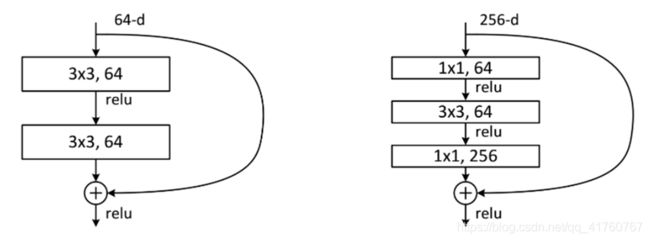
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个“building block” 。
GoogLeNet:
网络结构:

模型解读:
GoogLeNet网络有22层深(包括pool层,有27层深),在分类器之前,采用Network in Network中用Averagepool(平均池化)来代替全连接层的思想,而在avg pool之后,还是添加了一个全连接层,是为了大家做finetune(微调)。而无论是VGG还是LeNet、AlexNet,在输出层方面均是采用连续三个全连接层,全连接层的输入是前面卷积层的输出经过reshape得到。据发现,GoogLeNet将fully-connected layer用avg pooling layer代替后,top-1 accuracy 提高了大约0.6%;然而即使在去除了fully-connected layer后,依然必须dropout。
由于全连接网络参数多,计算量大,容易过拟合,所以GoogLeNet没有采用VGG、LeNet、AlexNet三层全连接结构,直接在Inception模块之后使用Average Pool和Dropout方法,不仅起到降维作用,还在一定程度上防止过拟合。
在Dropout层之前添加了一个7×7的Average Pool,一方面是降维,另一方面也是对低层特征的组合。我们希望网络在高层可以抽象出图像全局的特征,那么应该在网络的高层增加卷积核的大小或者增加池化区域的大小,GoogLeNet将这种操作放到了最后的池化过程,前面的Inception模块中卷积核大小都是固定的,而且比较小,主要是为了卷积时的计算方便。
特点:
1.此网络架构的主要特点就是提升了对网络内部计算资源的利用。
2.增加了网络的深度和宽度,网络深度达到22层(不包括池化层和输入层),但没有增加计算代价。
3.参数比2012年冠军队的网络少了12倍,但是更加准确。
4.对象检测得益于深度架构和传统的计算机视觉算法(R-CNN)。
参数个数:

GoogLeNet在网络模型方面与AlexNet、VGG还是有一些相通之处的,它们的主要相通之处就体现在卷积部分,
- AlexNet采用5个卷积层
- VGG把5个卷积层替换成5个卷积块
- GoogLeNet采用5个不同的模块组成主体卷积部分
Inception V2:学习VGGNet的特点,用两个33卷积代替55卷积,可以降低参数量,提出BN算法。BN算法是一个正则化方法,可以提高大网络的收敛速度。就是每一batch的输入分布标准化处理,使得规范化为N(0,1)的高斯分布,收敛速度大大提高。
**Inception V3:**学习Factorization into small convolutions的思想,在Inception V2的基础上,将一个二维卷积拆分成两个较小卷积,例如将77卷积拆成17卷积和7*1卷积,这样做的好处是降低参数量。该paper中指出,通过这种非对称的卷积拆分比对称的拆分为几个相同的小卷积效果更好,可以处理更多,更丰富的空间特征,这就是Inception V3网络结构。
**Inception V4:**借鉴了微软的ResNet网络结构思想,实际上是把原来的inception加上了resnet的方法,从一个节点能够跳过一些节点直接连入之后的一些节点,并且残差也跟着过去一个。
想了解inception V1 V2 V3 V4:https://blog.csdn.net/u011021773/article/details/80791650?ops_request_misc=&request_id=&biz_id=102&utm_term=Inception%20V4&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-6-80791650.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187