2022VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
摘要
我们提出了一个统一的视觉-语言预训练模型(VLMo),该模型与一个模块化的transformer网络共同学习一个双编码器和一个融合编码器。具体地,我们引入了模态混合专家(MoME)Transformer,其中每个块包含一个特定于模态的专家的池化和一个共享的自注意力层。由于MoME的建模灵活性,预训练好的VLMo可以作为视觉语言分类任务的融合编码器进行微调,或者用作有效的图像-文本检索的双编码器。此外,我们提出了一种阶段预训练策略,该策略有效地利用了除图像-文本对之外的大规模的仅图像和仅文本数据。实验结果表明,VLMo在各种视觉-语言任务上取得了最先进的结果,包括VQA、NLVR2和图像文本检索。
一、介绍
视觉-语言(VL)预训练从大规模的图像-文本对中学习通用的跨模态表示。以往的模型通常采用图像-文本匹配、图像-文本对比学习、掩码区域分类/特征回归、单词-区域/补丁对齐和掩码语言建模等方法来对视觉和语言信息进行聚合和对齐,然后,预训练好的模型可以直接对下游的视觉-语言任务进行微调,如VL检索和分类(视觉问答、视觉推理等)。
两种主流体系结构在以前的工作中被广泛使用。CLIP和ALIGN采用双编码器架构,分别编码图像和文本,模态交互作用是由图像和文本特征向量的余弦相似度来处理的。双编码器架构对检索任务是有效的,特别是对大量的图像和文本,图像和文本的特征向量可以预先计算和存储。然而,图像和文本之间的浅层交互并不足以处理复杂的VL分类任务。ViLT发现CLIP在视觉推理任务上的准确性相对较低。另一行工作依赖于对建模图像-文本对具有跨模态注意力的融合编码器。融合编码器架构在VL分类任务上取得了优越的性能,但它需要联合编码所有可能的图像-文本对。二次时间复杂度导致的推理速度比时间复杂度为线性的双编码器模型要慢得多。
为了利用这两种类型的架构,我们提出一个统一的视觉-语言预训练模型(VLMo),可以作为一个双编码器分别编码图像和文本检索任务,或作为融合编码器建模图像-文本对的深度交互用于分类任务。这是通过引入模态混合专家(MoME)Transformer,这可以编码一个Transformer块内的各种模态(图像、文本、和图像-文本对)。MoME采用了多模态专家的池化来取代标准Transformer中的前馈网络,它通过切换到不同的模态专家来捕捉特定于模态的信息,并使用跨模态的共享自注意力来对齐视觉和语言信息。具体地,MoME Transformer包含三个模态专家,分别是用于图像编码的视觉专家、用于文本编码的语言专家、和用于图像-文本融合的视觉-语言专家。由于建模的灵活性,我们可以为不同的目的使用共享参数重用MoME Transformer,即仅文本编码器、仅图像编码器、和图像-文本融合编码器。
VLMo与三个预训练任务共同学习,即图像-文本对比学习、图像-文本匹配、和掩码语言建模。此外,我们还提出了一种阶段预训练策略,在VLMo预训练中有效利用图像-文本对之外的大规模仅图像和进文本语料库。我们首先利用BEIT中提出的掩码图像建模方法,对MoME Transformer的视觉专家和自注意力模块在仅图像数据上进行了预训练,然后,我们使用掩码语言建模对语言专家在纯文本数据上预训练,最后,利用该模型初始化视觉-语言预训练。通过摆脱有限大小的图像-文本对及其简单的和简短的标题,对大量的仅图像和仅文本数据进行阶段预训练,有助于VLMo学习更通用的表示。
实验结果表明,VLMo在视觉-语言检索和分类任务上取得了最先进的结果。我们的模型,用作一个双编码器,优于融合编码器基本模型,同时在检索任务上享受到更快的推理速度。此外,我们的模型还在视觉问答(VQA)和视觉推理的自然语言(NLVR2)方法取得了最先进的结果,其中VLMo被用作融合编码器。
我们的主要贡献如下:1)我们提出了一个统一的视觉-语言预训练模型VLMo,它可以用作分类任务的融合编码器,也可以作为检索任务的双编码器进行微调。2)我们介绍了一种用于视觉-语言任务的通用多模态transformer,即MoME Transformer,以编码不同的模态。它由模态专家捕获特定于模态的信息,并通过跨模态共享的自注意力模块来对齐不同模态的内容。3)我们表明,使用大量的仅图像和仅文本数据的阶段预训练极大地改进了我们的视觉-语言预训练模型。
二、相关工作
与之前的工作不同,我们使用共享的MoME Transformer进行统一的预训练,使模型能够对检索任务执行单独的编码,并联合编码图像-文本对,以捕获分类任务的更深层次的交互。我们的模型实现了具有竞争力的性能,同时在检索和分类任务中具有更快的推理速度。
三、方法
给定图像-文本对,VLMo通过MoME Transformer网络获得仅图像、仅文本、和图像-文本对表示。如图1所示,统一的预训练优化了具有仅图像和仅文本表示的图像-文本对比学习、图像-文本对表示的图像-文本匹配和掩码语言建模的共享MoME Transformer。由于建模的灵活性,该模型可以作为检索任务的双编码器,在微调过程中分别编码图像和文本。它还可以作为融合编码器进行微调,以建模图像和文本的更深层的模态交互。
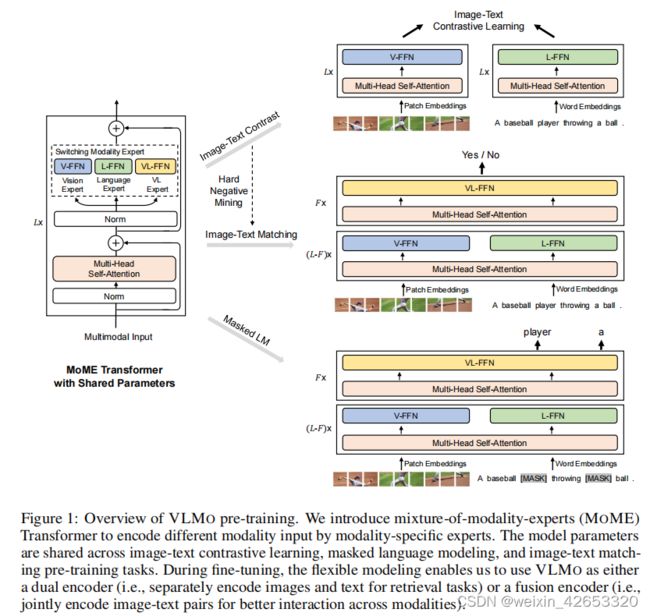
图1是VLMo预训练的概述。我们引入了混合模态专家(MOME)Transformer来编码特定模态专家的不同模态输入。该模型参数在图像-文本对比学习、掩蔽语言建模和图像-文本匹配的训练前任务中共享。在微调过程中,灵活的建模使我们能够使用VLMO作为双编码器(即,分别将图像和文本编码用于检索任务)或融合编码器(即,联合编码图像-文本对,以更好地跨模式交互)。
3.1 输入表示
给定一个图像-文本对,我们将图像-文本对编码为图像、文本、和图像-文本向量表示。然后将这些表示输入MoME Transformer,以学习上下文表示,并对齐图像和文本特征向量。
图像表示 根据视觉Transformer,2D图像v∈RH×W×C被分割并重塑为N=HW/P2补丁vp∈RN×(P2C),其中C是通道数,(H,W)是输入图像的分辨率,(P,P)是补丁分辨率。然后将图像补丁展平为向量,并进行线性投影,得到补丁嵌入。我们还在序列上准备了一个可学习的特殊标记[I_CLS]。最后,通过叠加补丁嵌入、可学习的1D位置嵌入Vpos∈R(N+1)×D和图像类型嵌入Vtype∈RD:H0v=[v[I_CLS],vvip,…+Vpype,其中H0v∈R(N+1)×D,线性投影V∈R(P2C)×D。
文本表示 根据BERT,我们通过WordPiece将文本标记为子词。一个序列的开始标记(I_CLS)和一个特殊边界标记(T_SEP)被添加到文本序列中。文本输入表示H0w∈R(M+2)×D被计算通过加上相应的单词嵌入、文本位置嵌入和文本类型嵌入H0w=[w[T_CLS],wi,…,wM,w[T_SEP]]+Tpos+Ttype。M表示标记化的子字单位的长度。
图像-文本表示 我们将图像和文本输入向量连接起来,形成图像-文本表示H0 vl=[H0w;H0v]。
3.2 模态混合专家Transformer
受专家混合网络的启发,我们提出了一种用于视觉-语言任务的通用多模态Transformer,即MoME Transformer,以编码不同的模态。MoME Transformer引入了混合模态专家来代替标准Transformer的前馈网络。给定前一层的输出向量Hl−1,l∈[1,L],每个MoME Transformer块通过切换到不同模态的模态专家来捕获特定于模态的信息,并使用跨模态共享的多头自注意力来对齐视觉和语言内容。LN是层归一化的缩写。

MoME-FFN根据输入向量Hl'的模态和Transformer层的索引,选择多个模态专家中的一个专家。具体来说,由三种模态专家:视觉专家(V-FFN)、语言专家(L-FFN)、和视觉-语言专家(VL-FFN)。如果输入是仅图像向量或仅文本向量,我们使用视觉专家编码图像,使用语言专家编码文本。如果输入包含多个模态的向量,如图像-文本对的向量,我们使用视觉专家和语言专家在Transformer的底层编码各自的模态向量,然后在顶层使用视觉-语言专家来捕获更多的模态交互。给定输入向量的三种类型,我们得到了仅图像、仅文本和图像-文本上下文表示。
3.3 预训练任务
VLMo通过图像和文本表示上的图像-文本对比学习、在图像-文本对表示上的掩码语言建模和图像-文本匹配,共享参数。
图像-文本对比 给定一批N个图像-文本对,图像-文本对比学习的目标是预测N*N个可能的图像-文本对的匹配对。在一个训练批中由N2-N个负的图像-文本对。
[I_CLS]标记和[T_CLS]标记的最终输出向量分别被用作图像和文本的聚合表示。然后进行线性投影和归一化,我们在一个训练批中获得图像向量{ˆhvi}Ni=1和文本向量{ˆhwi}Ni=1,以计算图像到文本和文本到图像的相似性:
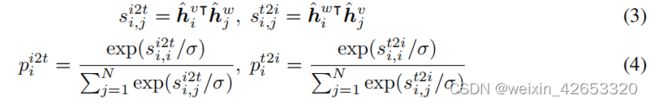
其中,si2t i,j表示第i对图像和第j对文本的图像到文本的相似度,st2i i,j表示文本对图像的相似度。ˆhwi∈RD和ˆhvj∈RD表示第i个文本和第j幅图像的归一化向量,σ是学习到的温度参数。pi2t i和pt2i i是softmax标准化相似性。利用图像到文本和文本到图像相似性的交叉熵损失来训练模型。
掩码语言建模 在BERT[10]之后,我们在文本序列中随机选择标记,并将它们替换为[MASK]标记。该模型被训练成从所有其他未掩蔽标记和视觉线索中预测这些掩蔽标记。我们使用15%的掩蔽概率作为BERT。掩码标记的最终输出向量被输入到整个文本词汇表上的分类器中用交叉熵损失。
图像-文本匹配 图像-文本匹配的目的是预测图像和文本是否匹配。我们使用[T_CLS]标记的最终隐藏向量来表示图像-文本对,并将该向量输入具有交叉熵损失的分类器进行二值分类。受ALBEF[23]的启发,我们基于对比图像到文本和文本到图像的相似性采样硬负图像-文本对。与ALBEF不同,它从单个GPU的训练样例中采样硬负挖掘(我们将其命名为局部硬负挖掘)。我们提出了全局硬负挖掘,并从所有gpu中收集的更多的训练例子中采样硬负图像-文本对。全局硬负挖掘可以找到更多信息丰富的图像-文本对,并显著地改进了我们的模型。
3.4 阶段性预训练
我们引入一个阶段性预训练策略,利用大规模仅图像和仅文本语料库来改进视觉-语言模型。如图2所示,我们首先对仅图像数据进行视觉预训练,然后对仅文本数据进行语言预训练,以学习一般的图像和文本表示。该模型用于初始化视觉-语言预训练,以学习视觉和语言信息的对齐。对于视觉预训练,我们训练了MoME Transformer的注意力模块和视觉专家,就像BEIT中的仅图像数据一样。我们直接利用BEIT的预训练的参数来初始化注意力模块和视觉专家。对于语言预训练,我们冻结了注意力模块和视觉专家的参数,并利用掩码语言建模对语言专家的纯文本数据进行了优化。与图像-文本对相比,仅图像数据和仅文本数据更容易收集。此外,图像-文本对的文本数据通常较短而简单。对仅图像和仅文本语料库的预训练提高了对复杂对的泛化效果。
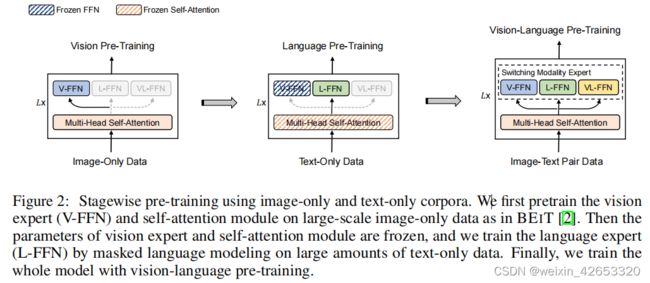
图2:使用仅图像和仅文本语料库进行阶段性预训练。我们首先对视觉专家(V-FFN)和自我注意模块进行了大规模的仅图像数据的预训练,就像在BEIT[2]中一样。然后冻结视觉专家和自我注意模块的参数,通过对大量的纯文本数据进行掩码语言建模,训练语言专家(L-FFN)。最后,我们用视觉语言的预训练来训练整个模型。
3.5 在下游任务上微调VLMo
如图3所示,我们的模型可以进行微调,以适应各种视觉-语言的检索和分类任务。
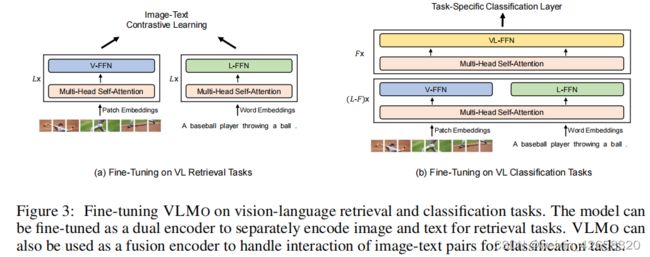
图3:微调视觉语言检索和分类任务上的VLMO。该模型可以作为一个双编码器进行微调,以分别对图像和文本进行编码用于检索任务。VLMO还可以作为一个融合编码器来处理分类任务中的图像-文本对的交互。
视觉-语言分类 对于视觉问题回答和视觉推理等分类任务,VLMO被用作一个融合编码器来建模图像和文本的模态交互。我们使用标记[T_CLS]的最终编码向量作为图像-文本对的表示,并将其提供给特定于任务的分类器层来预测标签。
视觉-语言检索 对于检索任务,VLMO可以作为双编码器分别对图像和文本进行编码。在微调过程中,我们的模型对图像-文本对比损失进行了优化。在推理过程中,我们计算所有图像和文本的表示,然后使用点积得到所有可能的图像-文本对的对图像到文本和文本到图像的相似度得分。单独的编码比基于融合编码器的模型能够实现更快的推理速度。
四、实验
我们使用大规模的图像-文本对对模型进行预训练,并在视觉-语言分类和检索任务上评估模型。
4.1 预训练设置
继之前的工作之后,我们的预训练数据包含四个图像标注数据集:概念标注(CC)、SBU标注、COCO和Visual Genome(VG)数据集。预训练数据中约有4M图像和10M图像-文本对。
4.3 在视觉-语言分类任务上的评估
我们首先在两个广泛使用的分类数据集上进行微调实验:视觉问题回答[15]和视觉推理[42]的自然语言。该模型被微调为一个融合编码器,以建模更深层次的交互。
视觉问答(VQA) 对于VQA,给出一个自然图像和一个问题,任务是生成/选择正确的答案。我们在VQA 2.0数据集[15]上训练和评估该模型。按照常见的做法,我们将VQA 2.0转换为一个分类任务,并从一个由3,129个答案组成的共享集合中选择答案。我们使用[T_CLS]标记的最终编码向量作为图像-问题对的表示,并将其提供给分类器层来预测答案。
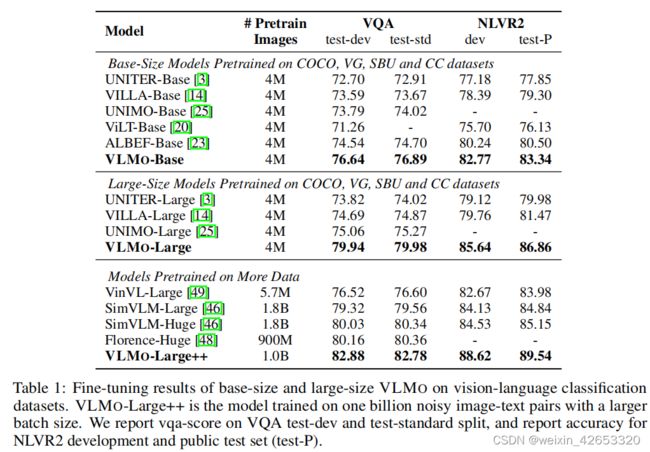
4.6 消融研究

五、结论
在这项工作中,我们提出了一个统一的视觉语言预训练模型VLMO,它共同学习一个双编码器和一个具有共享的MoME Transformer主干的融合编码器。MOME引入了一群模态专家来编码特定于模态的信息,并使用共享的自我注意模块来对齐不同的模态。使用MOME的统一预训练使模型能够用作高效视觉语言检索的双编码器,或作为融合编码器来建模分类任务的跨模态交互。我们还表明,利用大规模的仅图像和仅文本语料库的阶段性预训练极大地改善了视觉语言的预训练。实验结果表明,VLMO在各种视觉语言分类和检索基准上优于以往最先进的模型。
在未来,我们希望从以下几个角度来改进VLMO:1)我们将扩大在VLMO预训练中使用的模型规模。2)我们还希望根据UniLM[11]中提出的方法,对视觉语言生成任务的VLMO进行微调,比如图像字幕。3)我们将探索视觉语言预训练在多大程度上可以帮助彼此,特别是当共享的MOME主干自然地混合在文本和图像表示中。4)我们可以扩展所提出的模型来集成更多的模式(例如,语音、视频和结构化知识),支持通用的多模态预训练。