2022: LAVT: Language-Aware Vision Transformer for Referring Image Segmentation
摘要
指代图像分割目的是从图像中分割出自然语言表达式指代的对象。我们表明,通过视觉transformer编码器网络中间层的语言和视觉特征的早期融合能够实现更好的跨模态对齐。通过在视觉特征提取编码阶段进行跨模态特征融合,我们可以利用transformer编码器中已被证明的相关建模能力提取有用的多模态上下文。通过这种方式可以获得正确的分割结果以及一个轻量级的掩码预测器。
一、介绍
图像特征与文本特征的融合策略包括循环交互、跨模态注意力、多模态图推理、语言结构引导的上下文建模等。最近通过一个跨模态transformer解码器(图1(a))学习有效的跨模态对齐取得了性能提升。
然而,跨模态交互只发生在特征编码之后,一个跨模态解码器只负责对齐视觉和语言特征。因此,以前的方法不能有效利用编码器中丰富的transformer层来挖掘有用的多模态上下文。为解决此问题,一种潜在的解决是利用一个视觉编码器网络在视觉编码期间共同嵌入语言和视觉特征。
据此,我们提出一种语言感知的视觉transformer网络(LAVT),其中视觉特征与语言特征被一起编码,在每个空间位置感知相关的语言上下文。如图1(b),LAVT在一个现代视觉Transformer主干网络中充分利用多阶段设计,形成了一种分层的语言感知视觉编码方案。具体地,我们通过一个像素-单词注意力机制密集地将语言特征整合进视觉特征中,这发生在网络的每个阶段。有益的视觉-语言线索然后被之后的transformer块利用,如[35],在下一个编码器阶段。这种方法使我们放弃一个复杂的跨模态解码器,因为提取的语言感知的视觉特征可以很容易地使用一个轻量级的掩码预测器获得准确的分割掩码。
本文的贡献如下:(1)我们提出了LAVT,一种基于transformer的参考图像分割框架,它可以执行语言感知的视觉编码来替代特征提取后的跨模态融合。(2)我们在参考图像分割的三个数据集上实现了最新的结果,论证了所提出方法的有效性和通用性。

二、相关工作
三、方法
图2论证了LAVT模型的结构,利用一个分层的视觉transformer来联合嵌入语言和视觉信息来促进跨模态对齐。

3.1 语言感知的视觉编码
我们使用一个深度语言表示模型编码输入表达式为高维的单词向量,将语言特征表示为L∈RCt×T,其中Ct和T分别表示通道数和单词数。
在获得语言特征之后,我们通过视觉Transformer层的分层共同进行视觉特征编码和视觉-语言(也被称为跨模态或多模态)特征融合,将其分为四个阶段。我们在自底向上的方向上使用i∈{1,2,3,4}索引每个阶段。每个阶段采用了一堆Transformer编码层(具有相同的输出大小)φi、一个多模态特征融合模块θi和一个可学习的门控单元ψi。在每个阶段,语言感知的视觉特征通过三个步骤被生成和定义。首先,Transformer层φi将前一阶段的特征作为输入,输出丰富的视觉特征,表示为Vi∈RCi×Hi×Wi。然后,通过多模态特征融合模块θi将Vi与语言特征L结合,生成一组多模态特征,记为Fi∈RCi×Hi×Wi。最后,Fi中的每个元素由可学习的门控单元ψi加权,然后将元素添加到Vi中,生成一组嵌入语言信息的增强视觉特征,我们将其表示为Ei∈RCi×Hi×Wi。我们将这最后一步中的计算称为语言路径。这里,Ci、Hi和Wi分别表示第i阶段的通道数量、特征图的高度和宽度。
Transformer编码层的四个阶段对应Swin Transformer中的四个阶段,这是一种有效的分层视觉主干,适合解决密集预测任务。每个阶段中的多模态特征融合模块是我们所提出的像素-单词注意力模块(PWAM),其设计目的是将语言意义与视觉线索密集对齐。门控单元就是我们所说的语言门(LG),这是我们设计的一个特殊单元,用于调节沿着语言路径(LP)的语言信息的流动。
3.2 像素-单词注意力模块
为从其背景中分离一个目标对象,将视觉与跨模态对象的语言表示对齐是重要的。一种通用的方法是结合每个像素的表示和参考表达的表示,并学习对参照类和背景类有区别的多模态表示。之前的方法已经发展了各种机制解决这一挑战,包括动态卷积、连接、跨模态注意力、图神经网络等。与大多以前的跨模态注意力机制相比,我们的像素-单词注意力模块(PWAM)产生了更小的内存占用,因为它避免计算两个图像大小的空间特征图的注意力权重计算,而且由于注意力步骤的减少也更简单。

图3为PWAM的原理图,给定输入视觉特征Vi∈RCi×Hi×Wi和语言特征L∈RCt×T,PWAM分两步进行多模态融合。首先,在每个空间位置,PWAM将单词维度的语言特征L聚合,生成特定位置的句子级特征向量,其收集了当前局部区域最相关的句子级特征向量。这步生成一组空间特征图Gi ∈ RCi×Hi×Wi 。具体地,我们通过如下得到Gi:

其中,ωiq、ωik、ωiv和ωiw都是投影函数。每个语言投影ωik和ωiv都实现为1×1与输出通道数Ci的卷积。查询投影ωiq和最终投影ωiw分别实现为1×1卷积,然后进行实例归一化,输出通道数为Ci。在这里,“flatten”是指将两个空间维度按row-major、C-style顺序展开成一个维度的操作,而“unflatten”指的是相反的操作。利用这两种操作和转换方法将特征映射转换为适当的形状进行计算。式1~5以视觉特征Vi为查询,以语言特征L为键和值,对查询投影函数ωiq和输出投影函数ωiw进行实例归一化,实现scaled点积注意力[55]。
其次,在得到与Vi形状相同的语言特征Gi后,我们将它们结合起来,通过元素级乘法生成一组多模态特征图Fi。具体来说,我们的步骤描述如下:

其中为元素级乘法,ωim和ωio分别为视觉投影和最终的多模态投影。这两个函数都被实现为1×1卷积,然后是ReLU[45]非线性。
3.3 语言途径
如前所述,在每个阶段,我们将来自PWAM,Fi的输出与来自transformer层,Vi的输出合并。我们将此融合操作中的计算称为语言途径。为了防止Fi压倒性的视觉信号和允许自适应的语言信息流到下一阶段的transfomer层,我们设计一个语言门学习一套元素级权值图基于Fi来重新缩放Fi中的每个元素。语言路径的示意图如图4,数学描述如下:
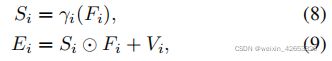

γi是一个两层感知器,第一层是1×1卷积,然后是ReLU[45]非线性,第二层是1×1卷积,然后是一个双曲正切函数。消融研究如表3,我们探究了有和没有使用一个语言门沿着语言路径,以及在语言门中不同的最终非线性激活函数,发现使用门和tanh最终非线性工作最适合我们的模型。式9中是利用预先训练好的视觉Transformer层进行多模态嵌入的一种有效方法,因为将多模态特征作为“补充”(或“残差”)进行处理,避免了破坏在纯视觉数据上预先训练好的初始化权值。在采用替换或连接的情况下,我们观察到了更糟糕的结果。
3.4 分割
我们结合多模态特征图,Fi,以自上而下的方式利用多尺度语义用于最终的分割,解码步骤可以通过以下递归函数来描述:

这里‘[;]’表示沿通道维度的特征连接,v表示通过双线性插值的上采样,ρi是一个投影函数,通过批归一化[26]和ReLU[45]非线性作为两个3×3卷积连接。最后的特征图Y1通过1×1卷积投影到两个类得分图中。
3.5 实现
LAVT中的变压器层通过来自Swin变压器[35]的ImageNet-22K[11]上预先训练的分类权值进行初始化。我们的语言编码器是基本的BERT模型,有12层,隐藏的大小为768,从[55](因此Ct在Sec。3是768),并使用官方的预先训练的权重进行初始化。Ci设置为512,模型以交叉熵损失进行优化。在[35]之后,我们采用了AdamW[38]优化器,权值衰减为0.01,初始学习率为0.00005,多项式学习率衰减。我们训练我们的模型为40epochs,批处理大小为32。我们在一个epoch中遍历每个对象(同时随机抽样一个引用表达式)。图像的大小被调整到480×480,没有数据增强技术被应用。在推理过程中,使用沿分数图的通道维度的argmax作为预测。
四、实验

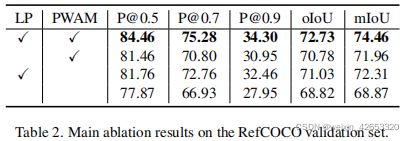


五、总结
本文,我们提出一种语言感知的视觉Transformer框架(LAVT)用于参考图像分割,利用一个视觉transformer的多阶段设计共同编码多模态输入。在三个基准上的实验结果论证了它的优势。