两种深度强化学习算法在网络调度上的应用与优化(DQN A3C)
首先给出论文地址和代码, Reinforcement Learning Based Scheduling Algorithm for Optimizing Age of Information in Ultra Reliable Low Latency Networks
从题目可以得知, 这是一篇有关强化学习的论文, 具体的工作是用A3C算法来优化10个sensor的AOI以及保证URLLC,所谓URLLC,即给每一个sensor都设定一个阈值,接着通过训练来保证每一个sensor的AOI不超过这个阈值,否则就会受到惩罚,给一个很负的奖励,通俗的来讲就是保证可靠性,这是优化目标。状态的设置是10个sensor的AOI和最后5个包的下载时间和吞吐量,将这些状态送往神经网络最后整合一下, 再通过一个全连接神经网络得到10个概率分布, 作者选择动作的方式和一般A3C选择动作的方式些许不同,但影响不大, 感兴趣的可以在代码里面查看,里面涉及到了很多知识, 模型的保存、交叉熵、tensorboard的可视化,模型的保存用于Test并给出最后的结果,也就是论文中的表格数据和图,Train文件夹是用来训练模型的,以上是作者所用的A3C算法,尽管这个模型还有很多的不足,但是很简单,作为学习入门是可以的了。
另外,我用最基本的DQN也实现了一下这篇论文, 最后的结果如下:

结果不比A3C差,我写的代码有时间也会上传到GitHub,以上。
1. D Q N 算 法 核 心 − l e a r n 1. DQN算法核心-learn 1.DQN算法核心−learn
包括了train和模型保存两个重要的部分,算法基本的流程和大家所学的相差不大, 不过由于记忆池的变化,所以有稍许的改动,原作者的模型保存是使用了一个队列来传递梯度下降的值到另一个函数里面去, 虽然最后我搞明白了所谓队列在两个函数之间传输的特点,但是用在我的代码里面就是一直无法收敛,所以我索性放到了train里面。
def prepare_learn(self, done):
# check to replace target parameters 用eval网络替换tartget网络的参数,
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else: # 如果计数累加不超过记忆池,从目前的memory_counter 中选32个索引值
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :] # 根据索引取memory中的数据 ,数据量是随机的不相关的数据
# batch_memory 中都是状态,这些状态包含了next_state,
q_eval = self.predict_eval(batch_memory[:, :, 0:self.s_dim[1]])
q_next = self.predict_next(batch_memory[:, :, self.s_dim[1]: self.s_dim[0] - 2])
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
action_vec = batch_memory[:, :, 11]
reward_vec = batch_memory[:, :, 10]
action_index = []
# 数据是记忆库的数据
reward = []
for a in action_vec:
i = np.argmax(a)
action_index.append(i)
# print(action_index)
for r in reward_vec:
i = r[0]
reward.append(i)
self.Reward_his.append(i)
# 32个索引值, 原来源是memory中的act数据,
eval_act_index = action_index
# 无法得到未来的期望
if done:
q_target[batch_index, eval_act_index] = reward
else:
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
self.epsilon = self.epsilon + self.e_greedy_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
_, cost = self.sess.run([self._train_op, self.loss],
feed_dict={
self.q_target: q_target,
self.inputs_e: batch_memory[:, :, 0:self.s_dim[1]],
})
self.cost.append(cost)
if self.learn_step_counter % 100 == 0:
self.saver.save(self.sess, SUMMARY_DIR + "/nn_model_ep_" + str(self.learn_step_counter) + ".ckpt")
print(f"MODEL READY_{self.learn_step_counter}!)")
另外在训练过程中的可视化也极为重要, 因为代码一开始是肯定无法收敛的,除非你是天选之子,如上代码的收敛是在不断测试下有的,甚至让笔者一度怀疑这算法到底可不可行。
可视化有多种方法,可以是一个特定数据反映数据是否收敛, 更好的当然是最为直接的图了,我在写代码的过程中发现如果选择每一个sensor的概率接近10%,即平均的更新每一个sensor,这样对应到奖励值上也会有一个不太差的结果, 但是在 D Q N DQN DQN中, 我发现选择频率最高的sensor接近收敛与19% , 这和 A 3 C A3C A3C是有一些不同的,它的概率通过 s o f t m a x softmax softmax输出就是稳定在10%左右, 这里体现了算法的差异性。这是一方面, 另一方面是在训练过程中,不同的算法选择更新sensor的临界点不同,这是上面所说的概率的另一个更加具体的体现,即 s e n s o r 1 sensor_1 sensor1的阈值为 30 30 30,那么 D Q N DQN DQN会选择在它的 A O I AOI AOI达到19时就更新它,不让它继续增加下去了,这和算法本身的训练过程有关, 优化目标既然是最小化所有 S e n s o r A O I Sensor AOI SensorAOI, 那么这个算法就认为在19更新它的 A O I AOI AOI我可以获得最大的奖励, 但对于 A 3 C A3C A3C肯定是不一样了, 具体的数据我没有论证, 大家如果感兴趣可以统计一下每一个算法在哪一个数值更新它的 A O I AOI AOI, 对比一下两个算法的不同.
2. D Q N 神 经 网 络 参 数 分 析 2.DQN神经网络参数分析 2.DQN神经网络参数分析
def build_eval_net(self):
with tf.variable_scope('eval_net', ):
# 这个inputs理应是s
inputs = tflearn.input_data(shape=[None, self.s_dim[0], self.s_dim[1]])
split_0 = tflearn.fully_connected(inputs[:, 0:1, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_1 = tflearn.fully_connected(inputs[:, 1:2, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_2 = tflearn.fully_connected(inputs[:, 2:3, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_3 = tflearn.fully_connected(inputs[:, 3:4, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_4 = tflearn.fully_connected(inputs[:, 4:5, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_5 = tflearn.fully_connected(inputs[:, 5:6, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_6 = tflearn.fully_connected(inputs[:, 6:7, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_7 = tflearn.fully_connected(inputs[:, 7:8, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_8 = tflearn.fully_connected(inputs[:, 8:9, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
split_9 = tflearn.fully_connected(inputs[:, 9:10, -1], Neu, activation='relu', bias_init=
tf.constant_initializer(0.1))
# 此处Neu应做卷积核个数, 4 为其size
split_20 = tflearn.conv_1d(inputs[:, 10:11, :], Neu, 4, activation='relu',
bias_init=tf.constant_initializer(0.1))
split_21 = tflearn.conv_1d(inputs[:, 11:12, :], Neu, 4, activation='relu',
bias_init=tf.constant_initializer(0.1))
split_20_flat = tflearn.flatten(split_20)
split_21_flat = tflearn.flatten(split_21)
merge_net = tflearn.merge(
[split_0, split_1, split_2, split_3, split_4, split_5, split_6, split_7, split_8, split_9,
split_20_flat, split_21_flat], 'concat')
dense_net_0 = tflearn.fully_connected(merge_net, Neu, activation='linear',
bias_init=tf.constant_initializer(0.1))
q_eval = tflearn.fully_connected(dense_net_0, self.a_dim, activation='linear', bias_init=
tf.constant_initializer(0.1))
return inputs, q_eval
调 用 : 调用: 调用:
self.inputs_e, self.q_eval = self.build_eval_net()
这里用的搭建神经网络的模块是集成在TensorFlow上的高级 A P I , T f l e a r n API, Tflearn API,Tflearn。
应用也十分简单, 给定一个inputs设定输入格式, 然后选用其中的数据即可, 这里因为我们的状态和每一个sensor的AOI有关, 所以可以看到前10个状态都是将一个个sensor的值传入了一个全连接神经网络, 再将两个一行五列的的数据放入卷积神级网络,为了维度匹配, 这里的神经元个数都是相同的,接着将这些值按行扩展拼接起来,再通过一个全连接网络,最后就可以输出q_eval值了, q_target的网络结构和以上一样, 这里不再赘述。
Trick of network
在调试的过程中发现神级网络参数的设置十分重要, 一些小的技巧可以使得模型更快的收敛。
Neu = 66
Filter = 66
经过测试, 神经元和卷积核的数量设置以上数据是合理的。
更为重要的是,上图代码的神经网络的偏差的设置也十分关键, 也即bias的值,我在莫凡走迷宫的代码中配置了我的DQN代码,加上bias要比不加agent走进出口的概率要大很多,所以我在这里加上了bias,同理, 也可以加初始化的 w w w, 大家可以尝试一下。
def __init__(
self,
sess,
a_dim,
state_dim,
# dqn中的学习率表示 α * (Q_target - Q_eval) = α * (R + gammma * max(Q(s',a1), Q(s', a3) ...)) - [Q(
# s1, a1), Q(s1, a2),..] ,
learning_rate=0.01,
# Gamma
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=100,
memory_size=9999,
batch_size=32,
e_greedy_increment=None,
):
Initialization parameter 记忆池设定在了9999, 学习率由A3C的0.001增加到了0.01模型很快就收敛了,batch_size稳定设置在32。
Activation
经过测试, 在 D Q N DQN DQN中, 最后一层或者两层用 l i n e a r linear linear效果更好, 其余用的是 r e l u relu relu, 注意,我只测试过 D Q N DQN DQN用哪一种激活函数比较好, 如果对别的神级网络的参数调试有好的建议和想法可以一起讨论!
动作选择与Agent
# -------------------Start next step--------------------------
sensor_selection = dqn.choose_action(np.reshape(state_, (1, S_INFO, S_LEN)))
time_stamp += 1
q_eval = dqn.predict_eval(np.reshape(state_, (1, S_INFO, S_LEN)))
# 记录交叉熵
entropy = dqn_.compute_entropy(q_eval[0])
entropy_record.append(entropy)
if (len(r_batch) >= TRAIN_SEQ_LEN and len(r_batch) % 10 == 0) or done == True:
print("Training.....")
dqn.prepare_learn(done)
# 记录下熵看何时保存模型
if done:
dqn.plot_reward()
dqn.plot_cost()
x = np.arange(len(entropy_record))
y = entropy_record
x_new = np.linspace(min(x), max(x), 100)
y_new = make_interp_spline(x, y)(x_new)
plt.plot(x_new, y_new)
plt.xlabel('steps')
plt.ylabel('Entropy')
plt.show()
break
if k == 79999:
done = True
在训练的过程中给定一个结束状态,当训练结束时就传入learn中结束掉训练, 同时绘制奖励和loss曲线 ,这里我绘图用了插值拟合, 这样可以更清晰的看到曲线的波动,而不是一团密集的折现,如下:
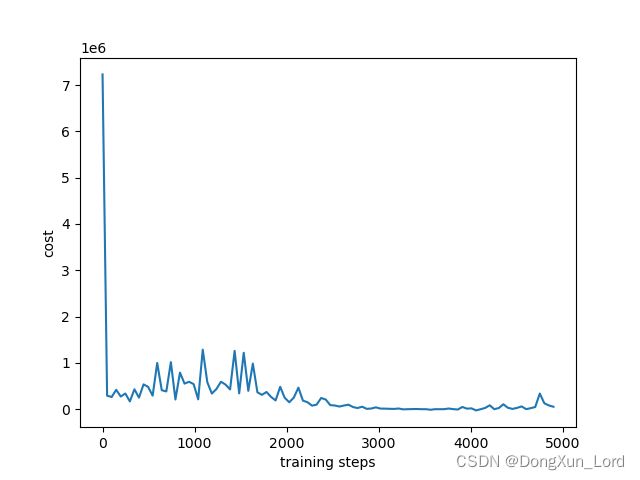

这里只训练了59999次,所以奖励值还有少许的波动
动作选择:
def choose_action(self, inputs):
if np.random.uniform() < self.epsilon:
q_eval = self.sess.run(self.q_eval, feed_dict={
self.inputs_e: inputs
})
sensor_index = np.argmax(q_eval)
else:
sensor_index = np.random.randint(0, self.a_dim) # 从动作集合中随便选一个
return sensor_index
动作还是选择使q_eval最大的索引, 作为动作。但是我一直不知道对于多个动作空间的选择是如何设置的,目前我遇到的都是选择单个动作, 如果动作的维度复杂,在复杂的动作空间是如何输出的?目前网上没有找到关于这方面的资源。
Agent参数
# coding=gb2312
import os
import matplotlib.pyplot as plt
import numpy as np
import tensorflow._api.v2.compat.v1 as tf # 这样的导入有1.0的提示
from scipy.interpolate import make_interp_spline
import dqn_
import env
import load_trace
np.set_printoptions(suppress=True)
# tf.reset_default_graph()
tf.logging.set_verbosity(tf.logging.ERROR)
tf.disable_v2_behavior()
os.environ['CUDA_VISIBLE_DEVICES'] = ''
S_INFO = 12
S_LEN = 5
A_DIM = 10
NUM_AGENTS = 1
TRAIN_SEQ_LEN = 1000
MODEL_SAVE_INTERVAL = 100
M_IN_K = 200.0
DEFAULT_SELECTION = 1 # default video quality without agent
RANDOM_SEED = 42 # 随机数种子
SUMMARY_DIR = './results/models'
LOG_FILE = './results/log'
TRAIN_TRACES = './cooked_traces/' # 训练路径
NN_MODEL = None
lamba = 1000 # 传感器的权重初始乘值