CV——day71 零基础学YOLO:YOLOv2
YOLOv2
- 5. YOLOv2
-
- 5.1 YOLOv2升级概述
- 5.2 YOLOv2网络架构
- 5.3 基于聚类提取先验框
- 5.4 偏移量计算方法
- 5.5 坐标映射与还原
- 5.6 感受野的作用
- 5.7 特征融合改进
-
- 5.7.1 多尺度检测
- 5.8 YOLOv2 总结
5. YOLOv2
5.1 YOLOv2升级概述
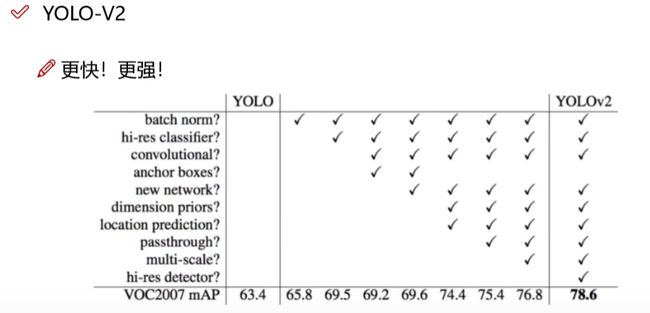
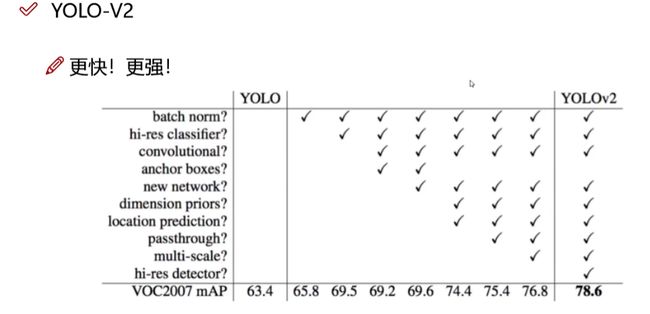
可以看出,v2的map相比v1改进了很多,那么具体有哪些呢?
YOLO-V2-Batch Normalization
a. V2版本舍弃Dropout,卷积后全部加入Batch Normalization
b. 网络的每一层的输入都做了归一化,收敛相对更容易
c. 经过Batch Normalization处理后的网络会提升2%的mAP
d. 从现在的角度来看,Batch Normalization已经成网络必备处理
5.2 YOLOv2网络架构

网络结构变许多,借鉴了VGG等网络,核心网络中所有层都是卷积层,无全连接层,不仅避免了过拟合,也减少了参数量。

5个最大池化(maxpool)作为降采样,减小输出大小,即变为原来的1/2,参数h,w也变为原来的h/32,w/32;输入的416*416因此也是有依据的,首先要能被32整除,416/32=13 是一个奇数,也就只有一个中心点,所以每个参数的选择都是很巧妙且有依据的。
5.3 基于聚类提取先验框
先验框B在YOLOv1的取值为2,但现实中远不止这两种,如Faster-RCNN有九种。

- **K=5:**上图(左)中可以看出,k=5是一个折中的值,再往上IOU的提升速度会逐渐变缓
- *1-IOU:*重合程度越高说明越近,而不用欧氏距离来计算,相当于归一化距离了。

5.4 偏移量计算方法

偏移量预测:tx,ty是预测值,原先的偏移量是x+tx,有可能超出边界框

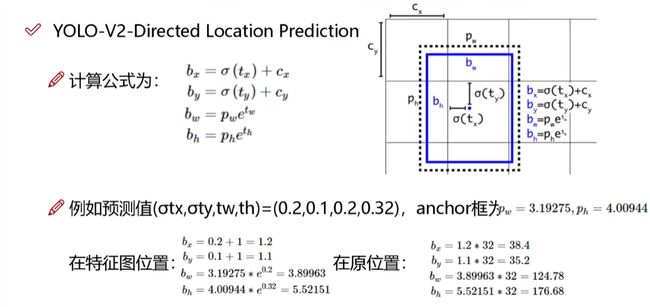
**计算公式如下:**仔细按顺序看其实就会很清楚了,加油!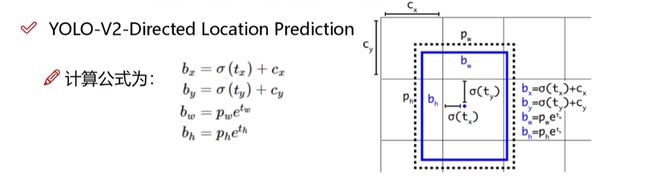
5.5 坐标映射与还原

为什么要乘以32呢,因为现在算出的位置是特征图上的位置,在原图上只有一个单元格大小,五次下采样2^{5}=32,等比例放大之后就是原来的位置所在了 。
5.6 感受野的作用
概述来说就是特征图上的点能看到原始图像多大区域
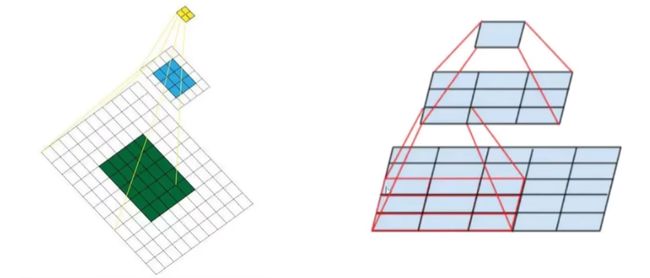
特征图中的一个单元格就相当于上一层输入图中的好几个单元格的浓缩。

图中绐的是两个卷积核堆起来,下边数字说的是3个,两个堆起来就是5 * 5,三个是7 * 7,可以自己尝试算一下。(也就是左边应该再有一个7 * 7的输入图)
那么为什么都用小卷积核呢?

5.7 特征融合改进
最后一层时感受野太大了,小目标可能丢失了,需融合之前的特征

把原特征图拆成四个13 * 13 * 512 的特征图,4 * 512+1024=3072,让前一层找小目标。
5.7.1 多尺度检测

5.8 YOLOv2 总结
到最后,其实大家就能看得懂这一张图了吧。