DPRQA论文笔记
Dense Passage Retrieval for Open-Domain Question Answering
这篇文章依然是关于开放问答领域,由Facebook发表,重点研究passage retrieval模块。
Overview
open-domain question answering 通常有两大模块: Passage Retrieval 和 Reader,前者是针对问题在数据库中寻找与该问题有关的文章,后者是对文章和问题进行encode并预测答案。本文重点研究前者,即训练出更好的Passage Retrieval模块。作者提到之前的工作,如BM25,采用的都是稀疏的向量表示,例如TF-IDF,因此本文希望训练出一个dense的Passage Retrieval模型来提取相关文章。
本文的contribution主要有两个:
- 提出dense的Passage Retrieval,并且不需要预训练,只需要简单fine-tuning就能超过BM25的效果
- 作者验证得出效果更好的Passage Retrieval会对整体end-to-end的QA系统准确率的提升起到很大帮助
Dense Passage Retrieval
Model
其实这里用到的就是两个BERT,只不过没有pre-train的过程。令 E P E_{P} EP和 E Q E_{Q} EQ分别表示passage和question的encoder,定义passage、question的dense representation为 v p = E P ( p ) , v q = E Q ( q ) v_{p}\ =\ E_{P}(p), \ \ \ v_{q}\ =\ E_{Q}(q) vp = EP(p), vq = EQ(q),两者的similarity定义为:
s i m ( p , q ) = v p T v q sim(p,q)\ =\ v^{T}_{p}v_{q} sim(p,q) = vpTvq
也就是普通的dot product。作者说相似度计算的方式有很多,但是试验结果表明,差别不大,因此就采用点积了。
Training
训练的部分需要定义损失函数,本文采用了负采样,即对于每个问题 q i q_{i} qi,我们取一个正例文章 p i + p^{+}_{i} pi+,和 n n n个负例文章 { p i , j − } j = 1 n \{p^{-}_{i,j}\}_{j=1}^{n} {pi,j−}j=1n,损失函数就定义为负对数似然
L ( q i , p i + , p i , 1 − , … , p i , n − ) = − l o g e s i m ( p i + , q i ) e s i m ( p i + , q i ) + ∑ j = 1 n e ( s i m ( q i , p i , j − ) ) L(q_i,p^+_i,p^-_{i,1},\dots,p^-_{i,n})\ =\ -log\ \frac{e^{sim(p^{+}_{i},q_{i})}}{e^{sim(p^{+}_{i},q_{i})+\sum_{j=1}^{n}e^(sim(q_i,p^-_{i,j}))}} L(qi,pi+,pi,1−,…,pi,n−) = −log esim(pi+,qi)+∑j=1ne(sim(qi,pi,j−))esim(pi+,qi)
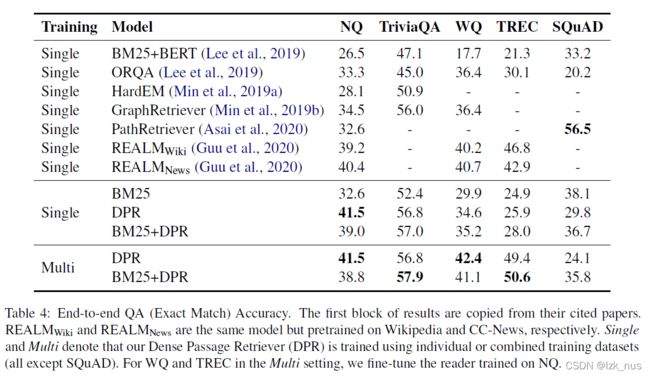
那么怎么选取负样本呢,作者提出了三种方式:
- Random:随机选取
- BM25:选取由BM25预测出的不包含问题的答案top passage,这些passage只是覆盖了问题中的大多数token
- Gold:将正例文章与其他问题进行匹配作为负例
在实际实验中,作者比较了不同的选取方式并最终决定选取一定数量的Gold和BM25 top1,如下表所示
同时,作者还用到了in-batch negative的方法,通过reuse gold passage来构建negative passage。具体来说,问题和文章经过encoder之后都是一个 B × d B \times d B×d的矩阵 Q , P Q,P Q,P, B B B是batch size,那么相似度矩阵就是 S = Q P T ∈ R B × B S\ =\ QP^T \ \ \ \in R^{B \times B} S = QPT ∈RB×B。对于这 B 2 B^2 B2个pair ( q i , p j ) (q_i,p_j) (qi,pj),当 i = j i=j i=j时为正例,否则就是反例。
Experiment
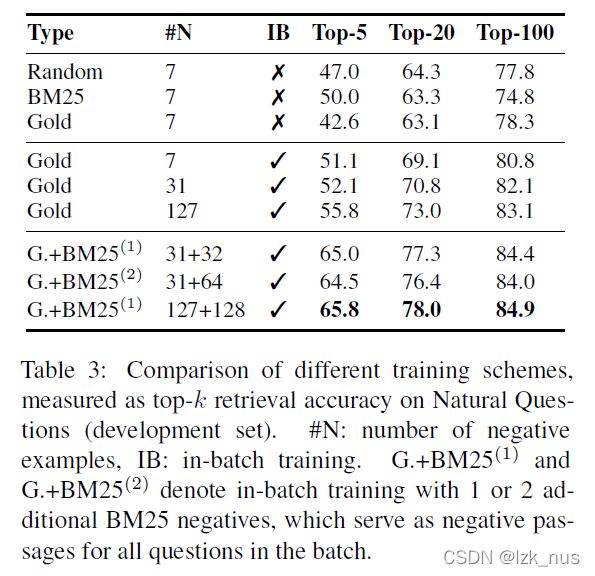
作者在多个数据集上进行了实验,包括NQ、TriviaQA,WQ、TREC、SQuAD。实验结果表明除了在SQuAD上效果不尽如人意,DPR的表现都很好
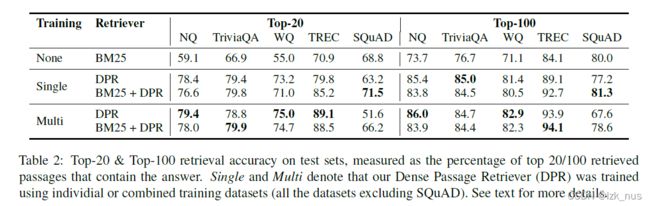
之后作者又将DPR嵌入整体的QA系统进行试验,EM的数据和上表成正比,这也就印证了作者所说的higher retrieval能够带来better performance