GAN生成对抗网络
目录
1. GAN的介绍
1.1 GAN的引入
1.2 GAN模型的主要组成
1.3 GAN训练的目的
1.4 GAN的网络结构示意图
1.5 数学描述
1.6 原始GAN-手写数字图像生成代码
2. 常见的GAN
2.1 DCGAN
2.1.1 DCGAN代码:
2.2 CGAN
2.2.1 条件GAN的代码:
2.3 VAE-GAN 自编码器GAN
2.3.1 自编码器代码实现:
2.3.2 自编码器去噪代码实现:
2.3.3 卷积自编码器去噪代码实现:
2.4 CycleGAN 循环GAN
2.5 ACGAN
3. GAN的应用
3.1 图像合成
3.2 生物医药发现
3.3 异常检测
3.4 高分辨率图像 Super Resolution
3.5 图像去噪
该文代码下载:GAN
1. GAN的介绍
1.1 GAN的引入
GAN:Generative Adversarial Networks 是一种无监督的深度学习模型,提出于2014年,被誉为“近年来复杂分布上无监督学习最具前景的方法之一。”
1.2 GAN模型的主要组成
- 生成器G(generator)
- 判别器D(discriminator)
1.3 GAN训练的目的
希望生成器G能够学习到样本的真实分布![]() ,那么G就能生成之前不存在的但是却又很真实的样本。
,那么G就能生成之前不存在的但是却又很真实的样本。
数据增强增加训练集

eg:
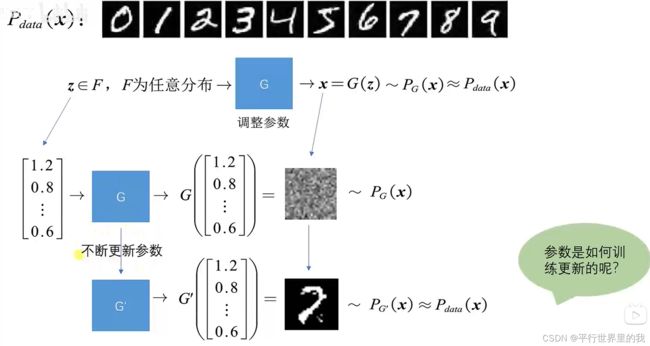
1.4 GAN的网络结构示意图

1.5 数学描述
![]()

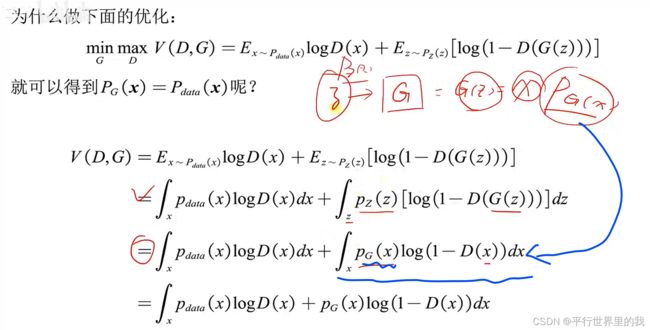

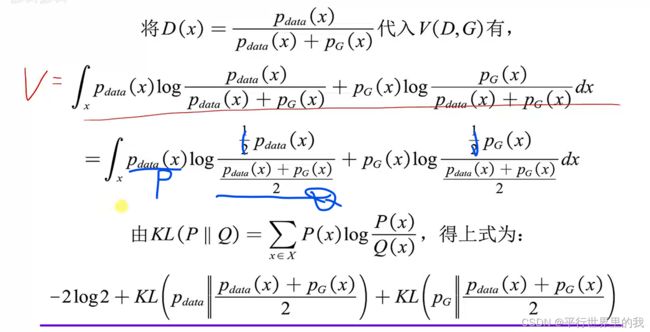 JSD散度最小时。使两个分布相等
JSD散度最小时。使两个分布相等

1.6 原始GAN-手写数字图像生成代码
分为生成器和判别器两部分。
整体代码为:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
(train_images, train_labels),(_, _) = tf.keras.datasets.mnist.load_data()
print(train_images.shape) #(60000, 28, 28)
# print(train_labels.shape) 输出(60000,) 实际上用不到标签值
train_images = tf.expand_dims(train_images, -1)# 或者用 train_labels = train_images.reshape(60000,28,281,1)
print(train_images.shape)
print(train_images.dtype) #
# train_images = train_images.astype('float32') # 把uint8类型转成float32类型
train_images = tf.cast(train_images, tf.float32)
print(train_images.dtype)
train_images = (train_images - 127.5)/127.5 # 归一化到[-1,1]
print(train_images.shape)
BATCH_SIZE = 64
#创建数据集
datasets = tf.data.Dataset.from_tensor_slices(train_images) # 最常用的创建数据集的方法from_tensor_slices,从train_images中创建datasets
print(datasets) #
datasets = datasets.shuffle(60000).batch(BATCH_SIZE) # (64, 28, 28)
print(datasets) #
# 生成器
def generator_model():
model = tf.keras.Sequential()
# 输入100,到隐含层1,256个神经元
model.add(tf.keras.layers.Dense(256, input_shape=(100,), use_bias=False)) # 输入一个100维的随机向量作为输入
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
# 隐含层2,512个神经元
model.add(tf.keras.layers.Dense(512, use_bias=False)) # 输入一个100维的随机向量作为输入
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
# 输出层是784个神经元
model.add(tf.keras.layers.Dense(28 * 28 * 1, use_bias=False, activation='tanh')) # 输入一个100维的随机向量作为输入
model.add(tf.keras.layers.BatchNormalization())
# 把784维的向量,reshape成一张图像,且注意其每一个值都是(-1,1)因为上面用的tanh做激活函数
model.add(tf.keras.layers.Reshape((28, 28, 1)))
return model
# 判别器
def discriminator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten()) # 判别器输入是一张图像[28, 28, 1],所以先flatten成一个向量作为神经元的输入层,连接到后面的隐含层
model.add(tf.keras.layers.Dense(512, use_bias=False))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dense(256, use_bias=False))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dense(1)) # 用sigmoid激活的话就认为<0.5认为不是一张真实的图像,>0.5认为是一张真实的图像,
# 不用sigmoid激活就认为<0是假的图像,>0是真的图像
return model
# 损失函数
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True) #二分类的交叉熵损失
# 解释一下from_logits=True:
# logits表示网络的直接输出,没经过sigmoid或者softmax的概率化。from_logits=False就表示把已经概率化了的输出,重新映射回原值,那么=True就是上面没有经过概率化输出
#判别器的loss
def discriminator_loss(real_out, fake_out): # image_out(64, 1), fake_out(64, 1)
#判别器的loss有两部分:真实的图像希望能判别为1,生成的图像希望能判别为0
image_real_loss = cross_entropy(0.9 * tf.ones_like(real_out), real_out) # cross_entropy(y_true, y_pred)
image_fake_loss = cross_entropy(tf.zeros_like(fake_out), fake_out)
return image_real_loss + image_fake_loss #整个的loss就是两部分合并起来
#生成器的loss
def generator_loss(fake_out): # fake_out为(64, 1), 就是对64张生成图像的预测结果
# print("fake_out:",fake_out.shape)
return cross_entropy(0.9*tf.ones_like(fake_out), fake_out) #希望生成的图像 image_fake被判定为真
# 生成器和判别器是两个模型,所以设置两个分别的优化器
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
# 训练
epochs = 100
noise_dim = 100
nsamples = 20 #每个epoch都生成20个数据看一下生成的效果
z = tf.random.normal([nsamples, noise_dim]) #生成16个随机100维的向量,用这16个随机向量来观察生成的手写数字的情况
generator = generator_model()
discriminator = discriminator_model()
# 对一个batch进行训练的函数
@tf.function # 加上这句话会训练的特别快
def train_step(images): # 接受一个批次的图像(64, 28, 28, 1)
noise = tf.random.normal([BATCH_SIZE, noise_dim]) # (64, 100)
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: # 要追踪两个model的梯度
gen_image = generator(noise, training=True) # 返回(64,28,28,1)
real_out = discriminator(images,
training=True) # 把images(64, 28, 28, 1)送入判别器返回(64,1) 64是64张图像,1是每个图像的返回结果, 因为最后之后一个神经元
fake_out = discriminator(gen_image, training=True) # 把生成的图像(64,28,28,1),送入判别器得到(64, 1)
# 以上都是为了得到loss, 通过记录loss的获得流程, 最终通过调整参数利用优化器, 降低loss
gen_loss = generator_loss(fake_out) # 生成器希望让生成图像被判别为真
disc_loss = discriminator_loss(real_out, fake_out)
gradient_gen = gen_tape.gradient(gen_loss, generator.trainable_variables) # 计算生成器损失和生成器变量之间的梯度
gradient_disc = disc_tape.gradient(disc_loss, discriminator.trainable_variables) # 计算判别器损失和生成器变量之间的梯度
# 更新参数
generator_optimizer.apply_gradients(zip(gradient_gen, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradient_disc, discriminator.trainable_variables))
def generator_plot_images(gen_model, test_noise): # 传进来的就是 z = tf.random.normal([nsamples, noise_dim]) # (20, 100)
pred_images = gen_model(test_noise, training=False)
fig = plt.figure(figsize=(20, 1))
# for i in range(pred_images.shape[0]):
# plt.subplot(4, 4, i+1)
# plt.imshow((pred_images[i,:,:,0] + 1) / 2, cmap='gray')
# plt.axis('off')
for i in range(nsamples): # 实际上就是pred_images.shape[0]
plt.subplot(1, 20, i + 1)
plt.imshow((pred_images[i, :, :, 0] + 1) / 2, cmap='binary') # pred_images是[20,28,28,1]
plt.axis('off')
plt.show() # 不加这句话就不能在训练的过程中看到生成的结果
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch in dataset:#image_batch就是(256, 28, 28, 1)
train_step(image_batch)
print("Epoch{}/{}".format(epoch+1, epochs))
generator_plot_images(generator, z)
train(datasets, epochs)
刚开始生成的图像不好,基本是噪声,随着训练的增加,训练结果越来越好。
2. 常见的GAN
2.1 DCGAN
DCGAN:Deep Convolutonal Generative Adversarial Networks 深度卷积生成对抗性网络
实际上DCGAN就是将判别器和生成器中原始GAN的多层感知机替换成卷积神经网络。
网络结构:
- 步长卷积 (D)和分数卷积 (G)取代池化层
- D和G里使用批归一化处理
- 移除全连接层
- 在G中使用ReLU激活函数,除最后一层使用Tanh输出
- 在D中使用LeakyReLU激活函数

2.1.1 DCGAN代码:
DCGAN的代码和1.6节原始GAN的区别在于生成器和判别器。
生成器代码为:
def generator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(7*7*256, use_bias=False,input_shape=(100,)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Reshape((7, 7, 256))) #(7, 7, 256)
model.add(tf.keras.layers.Conv2DTranspose(128, (5,5), strides=(1,1), padding='same', use_bias=False)) # (7, 7, 128)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(64, (5,5), strides=(2,2), padding='same', use_bias=False)) # (14, 14, 64)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(1, (5,5), strides=(2,2), padding='same', use_bias=False, activation='tanh')) # (28, 28, 1)
# model.add(tf.keras.layers.BatchNormalization()) # 最后一层不用BN,
# model.add(tf.keras.layers.LeakyReLU()) # (28, 28, 1) # 并用tanh激活
return model判别器代码为:
def discriminator_model():
model = tf.keras.Sequential()
# (28, 28, 1) -> (14, 14, 64)
model.add(tf.keras.layers.Conv2D(64, (5,5), strides=(2, 2), padding='same', input_shape=(28, 28, 1)))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3)) # 开始不希望判别器太厉害, 卷完之后变成(14, 14, 64)
# (14, 14, 64) -> (7, 7, 128)
model.add(tf.keras.layers.Conv2D(128, (5,5), strides=(2, 2), padding='same')) # (7, 7, 128)
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
# (7, 7, 128) -> (4, 4, 256) # ceil(7/2)
model.add(tf.keras.layers.Conv2D(256, (5,5), strides=(2, 2), padding='same')) #(4, 4, 256)
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Flatten()) # 打平
model.add(tf.keras.layers.Dense(1)) # 一个输出
return model最终结果比原始GAN要好一些。
2.2 CGAN
CGAN:Conditional Generative Adversarial Networks 条件GAN
数学描述:
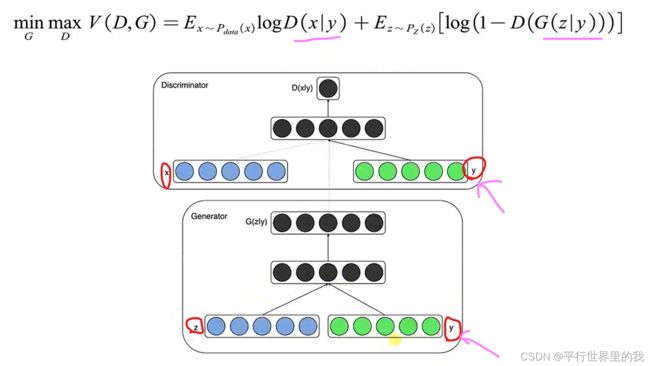
可以看作是每一个类别y都对应一个属于自己的目标函数。有了这个约束,假如生成了清晰但是类别与标签不匹配的图像,也会当作fake来进行打分,因此可以通过调整标签的值,来改变生成数据的类别。
2.2.1 条件GAN的代码:
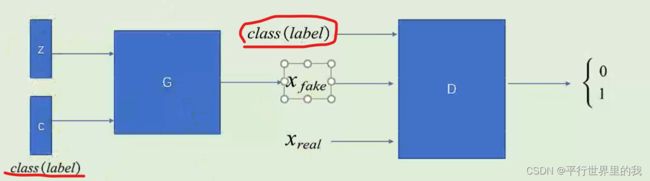
CGAN通过结合标签信息来提高生成数据的质量
生成器代码:
def generator_model():
noise = tf.keras.layers.Input(shape=((noise_dim))) # 输入的噪声是100维
label = tf.keras.layers.Input(shape=(())) # 输入的标签就是1个数,但是这个数可以表示有10个类别,所以在下面Embedding第一个是10,第二个是50是映射成50个神经元
x = tf.keras.layers.Embedding(10, 50, input_length=1)(label) # 把一个长度是1的标签(没有有one-hot编码)
#把x和noise合并在一起变成长度为150的向量
x = tf.keras.layers.concatenate([noise, x])
x = tf.keras.layers.Dense(3*3*128, use_bias=False)(x)
x = tf.keras.layers.Reshape((3, 3, 128))(x) # 注意reshape大写R
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
#下面开始反卷积: (3, 3, 128) -> (7, 7, 64) -> (14, 14, 32) -> (28, 28, 1)
x = tf.keras.layers.Conv2DTranspose(64, (3,3), strides=(2,2), use_bias=False)(x) #填充方式如果是same那么是(6, 6, 64),但是默认是vaild填充
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
#(7, 7, 64) -> (14, 14, 32)
x = tf.keras.layers.Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', use_bias=False)(x) #填充方式如果是same那么是(6,6,64),但是默认是vaild填充
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
#(14, 14, 32) -> (28, 28, 1)
x = tf.keras.layers.Conv2DTranspose(1, (3,3), strides=(2,2), padding='same', use_bias=False)(x) #填充方式如果是same那么是(6,6,64),但是默认是vaild填充
x = tf.keras.layers.Activation('tanh')(x)
model = tf.keras.Model(inputs=[noise, label], outputs=x)
return model判别器代码:
def discriminator_model():
image = tf.keras.layers.Input(shape=((28, 28, 1)))
label = tf.keras.layers.Input(shape=(()))
x = tf.keras.layers.Embedding(10, 28*28, input_length=1)(label)
x = tf.keras.layers.Reshape((28,28,1))(x)
x = tf.keras.layers.concatenate([x, image])#合并到一起形状变成(28, 28, 2)
x = tf.keras.layers.Conv2D(32, (3, 3), strides=(2,2), padding='same', use_bias=False)(x) # (14, 14, 32)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Dropout(0.5)(x) #不要快速成为一个很厉害的判别器
x = tf.keras.layers.Conv2D(64, (3, 3), strides=(2,2), padding='same', use_bias=False)(x) # (7, 7, 64)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Dropout(0.5)(x)
x = tf.keras.layers.Conv2D(128, (3, 3), strides=(2,2), padding='same', use_bias=False)(x) # (3, 3, 128)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Dropout(0.5)(x)
x = tf.keras.layers.Flatten()(x)
logits = tf.keras.layers.Dense(1)(x) #未激活的输出
model = tf.keras.Model(inputs=[image, label], outputs=logits)
return model2.3 VAE-GAN 自编码器GAN

自编码器:
包括两部分,一个Enconder一个Decoder,输入一张图像,目标是经过编码得到一个向量,然后将这个中间向量解码输出之后,输入图像和输出图像尽可能像,将输入输出图像的差异定义为loss,则优化loss就可以训练出Encoder和Decoder。
作用:去噪、降维、图像生成(把Decoder部分单独拿出来,给定一个向量,就能生成一张图像,但是随便给一个向量都能生成想要的图像吗?不一定,因为生成器要求输入的向量必须是经过Encoder之后的向量,如果想随机给一个向量,然后它随机产生一张正确的图像,这就引出了下面的变分自编码器。)
VAE:
设置两个损失,第一个是使得输入图像和输出图像尽可能的像,第二个损失是想让Encoder之后的向量满足一个分布,如正态分布,那么Encoder之后的向量就更加满足一个正态分布,那么就可以随机给一个正态分布的向量,就可以产生一个满足要求的图像。
VAE-GAN
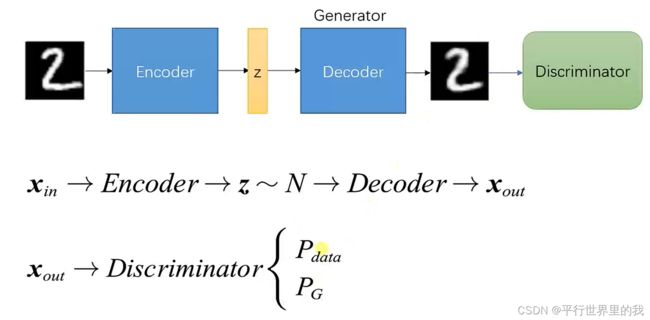
2.3.1 自编码器代码实现:
包括encoder和decoder两部分,另外,训练的是x_train,标签也是x_train。
将x_test(原始图像)输入自编码器,得到decoder_test(生成的图像)。
模型代码:
input_dim = tf.keras.layers.Input(shape=(input_size,))
#encode
en = tf.keras.layers.Dense(hidden_size,activation='relu')(input_dim) #把input_dim传入这一层
#decode
de = tf.keras.layers.Dense(output_size,activation='sigmoid')(en)
model = tf.keras.Model(inputs=input_dim,outputs=de)
model.summary()
model.compile(optimizer='adam',loss='mse')
model.fit(x_train,x_train,epochs=50,batch_size=256,shuffle=True,validation_data=(x_test,x_test))使用手写数字数据集,整体代码为:
import tensorflow as tf
import matplotlib.pyplot as plt
(x_train,_), (x_test,_) = tf.keras.datasets.mnist.load_data()
print(x_train.shape, x_test.shape) #(60000, 28, 28) (10000, 28, 28)
x_train = x_train.reshape(x_train.shape[0],-1) #变成60000 * 784的向量
x_test = x_test.reshape(x_test.shape[0],-1)
print(x_train.shape, x_test.shape) #(60000, 784) (10000, 784)
#归一化(像素值都是0-255的,归一化为0-1之间的数)
'''
tf.cast()函数的作用是执行 tensorflow 中张量数据类型转换,比如读入的图片如果是int8类型的,一般在要在训练前把图像的数据格式转换为float32。
'''
x_train = tf.cast(x_train, tf.float32) / 255
x_test = tf.cast(x_test, tf.float32) / 255
input_size = 784
hidden_size = 32
output_size = 784
input_dim = tf.keras.layers.Input(shape=(input_size,))
#encode
en = tf.keras.layers.Dense(hidden_size,activation='relu')(input_dim) #把input_dim传入这一层
#decode
de = tf.keras.layers.Dense(output_size,activation='sigmoid')(en)
model = tf.keras.Model(inputs=input_dim,outputs=de)
model.summary()
model.compile(optimizer='adam',loss='mse')
model.fit(x_train,x_train,epochs=50,batch_size=256,shuffle=True,validation_data=(x_test,x_test))
#获得encoder(功能可以把一张图像压缩为一个向量)
encode = tf.keras.Model(inputs=input_dim,outputs=en)
#获得decoder(把一个向量还原回图像)
input_decoder = tf.keras.layers.Input(shape=(hidden_size,))
output_decoder = model.layers[-1](input_decoder)
decode = tf.keras.Model(inputs=input_decoder,outputs=output_decoder)
#调用encoder把测试集数据压缩为32维向量
# encode_test = encode(x_test) # encode.predict(x_test)可以返回numpy数据(10000,32)
encode_test = encode.predict(x_test)
print(encode_test.shape)
# (10000, 32)
#调用decoder把向量解码回图像
# decode_test = decode(encode_test)
decode_test = decode.predict(encode_test)
print(decode_test.shape)
# (10000, 784)
x_test = x_test.numpy()
#画图
n = 10 #画两行10列的子图
plt.figure(figsize=(20,4))#宽20,高4
for i in range(1,10):
ax = plt.subplot(2, n, i)
plt.imshow(x_test[i].reshape(28,28),cmap='binary')
plt.axis('off')
ax = plt.subplot(2, n, n+i)
plt.imshow(decode_test[i].reshape(28,28),cmap='binary')
plt.axis('off')
plt.show()

2.3.2 自编码器去噪代码实现:
自己添加噪声,代码为:
#噪声系数
factor = 0.5
x_train_noise = x_train + factor * np.random.normal(0,1,size=x_train.shape) # 给x_train添加噪声x_train.shape:60000*784
x_test_noise = x_test + factor * np.random.normal(0,1,size=x_test.shape) # 给x_train添加噪声x_test.shape:10000*784
x_train_noise = np.clip(x_train_noise,0.,1.)
x_test_noise = np.clip(x_test_noise,0.,1.)
print("x_train:",x_train.shape) #x_train: (60000, 784)
print("x_test:",x_test.shape) #x_test: (10000, 784)
print("x_train_noise:",x_train_noise.shape) #x_train_noise: (60000, 784)
print("x_test_noise:",x_test_noise.shape) #x_test_noise: (10000, 784)
plt.figure(figsize=(10,2))
for i in range(1,11):#画10张图像,i从1到10
ax = plt.subplot(1,10,i)
plt.imshow(x_train_noise[i].reshape(28,28))
plt.show()
训练的是x_train_noise,标签是x_train
将x_test_noise(带噪声的图像)放入自编码器,得到decoder_test(不带噪声的图像)。
同样对手写数字识别图像进行去噪,整体代码为:
input_decoder = tf.keras.layers.Input(shape=(hidden_size,))
output_decoder = model.layers[-1](input_decoder)
decode = tf.keras.Model(inputs=input_decoder,outputs=output_decoder)
#调用encoder把测试集数据压缩为32维向量
# encode_test = encode(x_test) # encode.predict(x_test)可以返回numpy数据(10000,32)
encode_test = encode.predict(x_test_noise)
#调用decoder把向量解码回图像
# decode_test = decode(encode_test)
decode_test = decode.predict(encode_test)
x_test = x_test.numpy()
#画图
n = 10 #画两行10列的子图
plt.figure(figsize=(20,4))#宽20,高4
for i in range(1,10):
ax = plt.subplot(2, n, i)
plt.imshow(x_test_noise[i].reshape(28,28))
ax = plt.subplot(2, n, n+i)
plt.imshow(decode_test[i].reshape(28,28))
plt.show()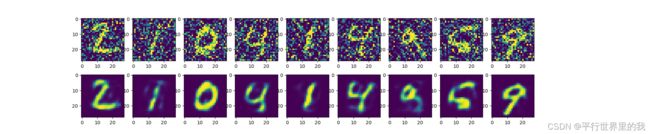
2.3.3 卷积自编码器去噪代码实现:
首先也是自己添加噪声,和2.3.2一样。
encode:用卷积提取特征; decode:用反卷积上采样,还原回原来的图像
模型代码为:
#encode:用卷积提取特征
# en = tf.keras.layers.Dense(hidden_size,activation='relu')(input_dim) #把input_dim传入这一层
input_dim = tf.keras.layers.Input(shape=x_train.shape[1:]) # x_train.shape[1:] 输出:TensorShape([28, 28, 1])
x = tf.keras.layers.Conv2D(16,3,activation='relu',padding='same')(input_dim) #28*28*16(16个3*3的卷积核)
x = tf.keras.layers.MaxPooling2D(padding='same')(x) #14*14*16(same就是保持原图大小不动,然后用2*2的池化窗口做池化)
x = tf.keras.layers.Conv2D(32,3,activation='relu',padding='same')(x) #14*14*32(再用32个3*3的卷积核做卷积得到14*14*32)
x = tf.keras.layers.MaxPooling2D(padding='same')(x) #7*7*32
#decode:用反卷积上采样,还原回原来的图像
x = tf.keras.layers.Conv2DTranspose(16, 3, strides=2, activation='relu', padding='same')(x)#stride就是把图像扩大回原来的2倍,把7*7*32的变成了14*14*16
x = tf.keras.layers.Conv2DTranspose(1, 3, strides=2, activation='sigmoid', padding='same')(x)#28*28*1
model = tf.keras.Model(inputs=input_dim,outputs=x)
model.summary()
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),loss='mse')
#训练的时候用带噪声的图像,输出是去除噪声的
model.fit(x_train_noise,x_train,epochs=50,batch_size=256,shuffle=True,validation_data=(x_test_noise,x_test))训练的是x_train_noise,标签是x_train
将x_test_noise(带噪声的图像)放入卷积自编码器,得到pre_test(不带噪声的图像)。
同样对手写数字识别图像进行去噪,整体代码为:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
(x_train,_), (x_test,_) = tf.keras.datasets.mnist.load_data()
# 现在是增加一个维度作为通道信息
x_train = np.expand_dims(x_train, -1)#在最后一个维度加一个通道信息(如这个就是单通道的,维度就是1)
x_test = np.expand_dims(x_test, -1)
print(x_train.shape, x_test.shape) #((60000, 28, 28, 1), (10000, 28, 28, 1))
#归一化像素值都是0-255的,归一化为0-1之间的数)
x_train = tf.cast(x_train, tf.float32) / 255
x_test = tf.cast(x_test, tf.float32) / 255
# 增加噪声
#噪声系数
factor = 0.5
x_train_noise = x_train + factor * np.random.normal(0,1,size=x_train.shape) # 给x_train添加噪声x_train.shape:60000*784
x_test_noise = x_test + factor * np.random.normal(0,1,size=x_test.shape) # 给x_train添加噪声x_test.shape:10000*784
x_train_noise = np.clip(x_train_noise,0.,1.)
x_test_noise = np.clip(x_test_noise,0.,1.)
print("x_train:",x_train.shape)
print("x_test:",x_test.shape)
print("x_train_noise:",x_train_noise.shape)
print("x_test_noise:",x_test_noise.shape)
plt.figure(figsize=(10,2))
for i in range(1,11):#画10张图像,i从1到10
ax = plt.subplot(1,10,i)
plt.imshow(x_train_noise[i].reshape(28,28))
plt.show()
#encode:用卷积提取特征
# en = tf.keras.layers.Dense(hidden_size,activation='relu')(input_dim) #把input_dim传入这一层
input_dim = tf.keras.layers.Input(shape=x_train.shape[1:]) # x_train.shape[1:] 输出:TensorShape([28, 28, 1])
x = tf.keras.layers.Conv2D(16,3,activation='relu',padding='same')(input_dim) #28*28*16(16个3*3的卷积核)
x = tf.keras.layers.MaxPooling2D(padding='same')(x) #14*14*16(same就是保持原图大小不动,然后用2*2的池化窗口做池化)
x = tf.keras.layers.Conv2D(32,3,activation='relu',padding='same')(x) #14*14*32(再用32个3*3的卷积核做卷积得到14*14*32)
x = tf.keras.layers.MaxPooling2D(padding='same')(x) #7*7*32
#decode:用反卷积上采样,还原回原来的图像
x = tf.keras.layers.Conv2DTranspose(16, 3, strides=2, activation='relu', padding='same')(x)#stride就是把图像扩大回原来的2倍,把7*7*32的变成了14*14*16
x = tf.keras.layers.Conv2DTranspose(1, 3, strides=2, activation='sigmoid', padding='same')(x)#28*28*1
model = tf.keras.Model(inputs=input_dim,outputs=x)
model.summary()
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),loss='mse')
#训练的时候用带噪声的图像,输出是去除噪声的
model.fit(x_train_noise,x_train,epochs=50,batch_size=256,shuffle=True,validation_data=(x_test_noise,x_test))
pre_test = model.predict(x_test_noise)
#画图
n = 10 #画两行10列的子图
plt.figure(figsize=(20,4))#宽20,高4
for i in range(1,11):
ax = plt.subplot(2, n, i)
plt.imshow(x_test_noise[i].reshape(28,28))
ax = plt.subplot(2, n, n+i)
plt.imshow(pre_test[i].reshape(28,28))
plt.show()

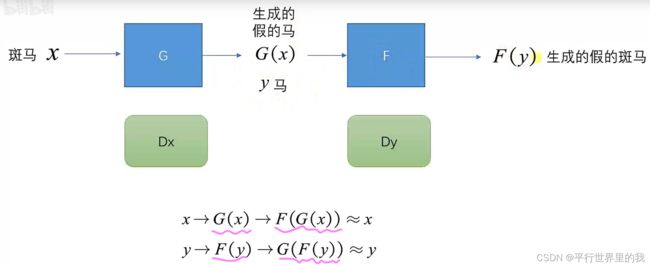
2.4 CycleGAN 循环GAN
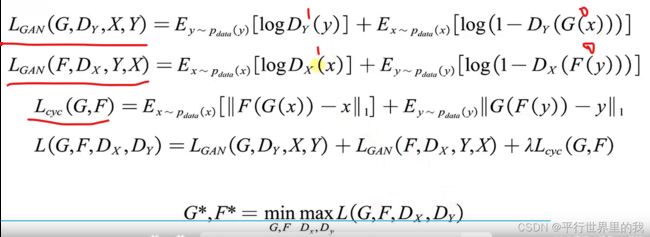
2.5 ACGAN
ACGAN 简介与代码实战
ACGAN模型为:
ACGAN既能生成图像又能进行分类
生成器的输入包括class(label)和noise两部分,其中class是训练数据的标签也就是label, 生成器将两个部分拼接,输出是一张图像;
判别器输入图像(真的和生成的),输出是两部分,一部分判别真假(batch,1),一部分输出是分类的结果。
损失函数:
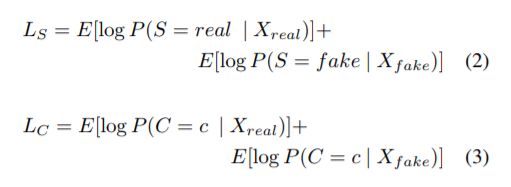

生成器代码:
def generator_model():
noise = tf.keras.layers.Input(shape=((noise_dim,))) # 输入的噪声是100维
label = tf.keras.layers.Input(shape=(())) # 输入的标签就是1个数,但是这个数可以表示有10个类别,所以在下面Embedding第一个是10,第二个是50是映射成50个神经元
x = tf.keras.layers.Embedding(10, 50, input_length=1)(label) # 把一个长度是1的标签(没有有one-hot编码)
#把x和noise合并在一起变成长度为150的向量
x = tf.keras.layers.concatenate([noise, x])
x = tf.keras.layers.Dense(3*3*128, use_bias=False)(x)
x = tf.keras.layers.Reshape((3, 3, 128))(x) # 注意reshape大写R
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
#下面开始反卷积: (3, 3, 128) -> (7, 7, 64) -> (14, 14, 32) -> (28, 28, 1)
x = tf.keras.layers.Conv2DTranspose(64, (3,3), strides=(2,2), use_bias=False)(x) #填充方式如果是same那么是(6, 6, 64),但是默认是vaild填充
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
#(7, 7, 64) -> (14, 14, 32)
x = tf.keras.layers.Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', use_bias=False)(x) #填充方式如果是same那么是(6,6,64),但是默认是vaild填充
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
#(14, 14, 32) -> (28, 28, 1)
x = tf.keras.layers.Conv2DTranspose(1, (3,3), strides=(2,2), padding='same', use_bias=False)(x) #填充方式如果是same那么是(6,6,64),但是默认是vaild填充
x = tf.keras.layers.Activation('tanh')(x) # [-1, 1]
model = tf.keras.Model(inputs=[noise, label], outputs=x)
return model判别器代码:
def discriminator_model():
image = tf.keras.layers.Input(shape=((28, 28, 1)))
# label = tf.keras.layers.Input(shape=(())) 去掉输入
# x = tf.keras.layers.Embedding(10, 28*28, input_length=1)(label)
# x = tf.keras.layers.Reshape((28,28,1))(x)
# x = tf.keras.layers.concatenate([x, image])
x = tf.keras.layers.Conv2D(32, (3, 3), strides=(2,2), padding='same', use_bias=False)(image) # (14, 14, 32)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Dropout(0.5)(x) #不要快速成为一个很厉害的判别器
x = tf.keras.layers.Conv2D(64, (3, 3), strides=(2,2), padding='same', use_bias=False)(x) # (7, 7, 64)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Dropout(0.5)(x)
x = tf.keras.layers.Conv2D(128, (3, 3), strides=(2,2), padding='same', use_bias=False)(x) # (3, 3, 128)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Dropout(0.5)(x)
x = tf.keras.layers.Flatten()(x)
S_out = tf.keras.layers.Dense(1)(x) #未激活的判断图像真假的输出
C_out = tf.keras.layers.Dense(10)(x) #分类输出,一共10类
# model = tf.keras.Model(inputs=[image, label], outputs=logits)
model = tf.keras.Model(inputs=image, outputs=[S_out, C_out]) #多输出模型
return model3. GAN的应用
- 高分辨率图像
- 目标检测
- 合成 Synthesis
- 分割 Segmentation
- 重建 Reconstruction
- 检测 Detection
- 降噪 De-noising
- 分类 Classification
3.1 图像合成
医学类图像,可能病发病率不一样,样本就不足。或者样本标记不够
从2D到3D的重建,生物医学领域,心脏、胃等建模
3.2 生物医药发现
如基于某一个病情,自动给出推荐需要用什么药,其实质是在一个数据库中根据病例做药物选择的过程。
针对不同人的病情做一个个性化推荐,捕捉每个个体之间的细微差异,于是引入GAN来做药物推荐。——AAE
3.3 异常检测
有很多正常数据,但是没有很多异常数据,于是可以通过生成器来学习到正常数据的分布,然后将需要检测到的异常图通过前面的生成器得到其正常图的样子,然后对比即可找出异常。
缺点:对于比较小的异常,因为GAN生成图并不能做到细节非常明显,所以很难检测。
3.4 高分辨率图像 Super Resolution
将低分辨率图像转换成高分辨率的
3.5 图像去噪
深度学习训练得到的降噪很容易模糊。
GAN:学习噪声,构造带噪声的图像,进行配对带噪声的和不带噪声的图像对比