KNN 最近邻
K:距离预测点最近的K个值,哪边多算哪边
监督学习
使用分类算法,且数据比较大
导入包
import pandas as pd
from sklearn import neighbors
import numpy as np
%matplotlib inline
import seaborntraining_data = pd.DataFrame()
training_data['test_1'] = [0.3051,0.4949,0.6974,0.3769,0.2231,0.341,0.4436,0.5897,0.6308,0.5]
training_data['test_2'] = [0.5846,0.2654,0.2615,0.4538,0.4615,0.8308,0.4962,0.3269,0.5346,0.6731]
training_data['outcome'] = ['win','win','win','win','win','loss','loss','loss','loss','loss']
training_data.head()绘图
seaborn.lmplot('test_1', 'test_2', data=training_data, fit_reg=False,hue="outcome", scatter_kws={"marker": "D","s": 100})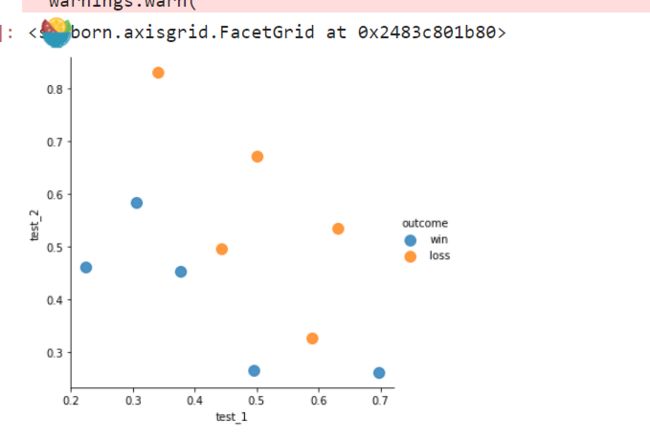
转化数据为numpy
test12 = training_data[['test_1', 'test_2']]
test12
X = test12.values
y = np.array(training_data['outcome'])
模型训练
#模型拟合
clf = neighbors.KNeighborsClassifier(3, weights = 'uniform')
trained_model = clf.fit(X, y)评价模型
trained_model.score(X, y)预测
# 创建一个新观测,为 .4 和 .6
x_test = np.array([[.4,.6]])
# 将学习者应用于新的未分类的观测。
trained_model.predict(x_test)
# array(['loss'], dtype=object)
trained_model.predict_proba(x_test)
# array([[ 0.66666667, 0.33333333]]) K值取值
from matplotlib import pyplot as plt
import numpy as np
score = []
krange = range(1,10)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i)
clf = clf.fit(X,y)
score.append(clf.score(X,y))
plt.xticks(np.array(krange))
plt.plot(krange,score)
plt.figure(figsize=(12,9))
plt.show()
参考链接
https://dsai-notes.apachecn.org/#/14