Modules Of YoloV5 Architecture
欢迎访问个人网络日志知行空间
文章目录
- 1.Bottleneck
- 2.BottlenetCSP
- 3. C3:Bottleneck with 3 Convolutional Blocks
- 4. Focus
- 5.SPP
- 6.DWConv, Depth Wise Convolution
- 7.GhostConv
- 8.GhostBottleneck
- 9.MixConv
- 10.CrossConv
- 11.FPN+PAN
-
- 在这里插入图片描述
1.Bottleneck
来自于何凯明2014年工作Resnet

2.BottlenetCSP
与CSP论文描述的方式不一直,但CSP论文源码亦是通过此方式实现,参考YoloV5 Issues 781。

3. C3:Bottleneck with 3 Convolutional Blocks
将Bottleneck换成 SPP将变成 C3SPP,换成Transformer将变成C3TR,换成GhostBottleneck就是C3Ghost,C3结构是Yolov5中提出的。

4. Focus
Focus层作为Yolov5中提出的,在最前面对输入做处理的层,是为了取代YoloV3中的前三层卷积,可以在保证图像信息无丢失的同时减小图像的尺寸,从而减小FLOPS,加速推理。
YoloV5 作者对Focus Layer的一些解释,可参考Discussion、Issue 804

5.SPP
YoloV5中实现的SPP与SPP论文给出来的,有些许差异,YoloV5中的SPP是固定了MaxPool的kernel大小分别为5\9\13,其stride=1,且对输入进行padding,故MaxPool并不改变输入图像的尺寸大小。

标准的SPP是指定MaxPool后输出的 W o u t W_{out} Wout、 H o u t H_{out} Hout尺寸大小,stride是根据输入 W i n , H i n W_{in},H_{in} Win,Hin和 W o u t W_{out} Wout、 H o u t H_{out} Hout来计算的,见何凯明大神2015年04月份的论文,keras代码实现。
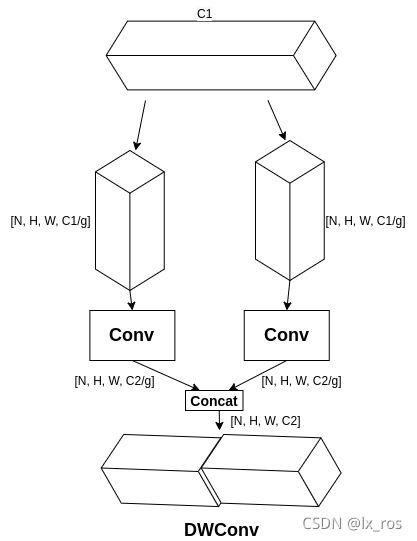
6.DWConv, Depth Wise Convolution
分组卷积,将输入特征按通道数分组,然后分别进行卷积,最后将结果沿通道方向Concat,Pytorch Conv2d接口中groups参数来控制,普通卷积相当于groups为1。
图片来源于:https://www.huaweicloud.com/zhishi/arc-13746260.html

YoloV5中goups=math.gcd(C1, C2),即输入输出通道的最大公约数。
7.GhostConv
华为诺亚实验室2020CVPR提出的GhostConv论文,代码, 主要思想是卷积得到的不同通道上的特征比较相似,可以降低卷积输出的通道数,通过对卷积得到的通道上的特征做线性变换来扩充特征通道,减少FLOPS的同时,能得到相同的结果。

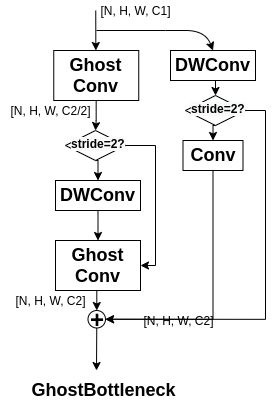
8.GhostBottleneck
GhostBottleneck, YoloV5中提出的结构,根据卷积的步长stride是否等于2来决定模块的结构。
9.MixConv
Google Brain 2019年提出来的一种方法,对同一个输入,按通道进行划分,不同通道部分的输入使用不同size的卷积核,将得到的输出沿通道方向合并,并使用shortcut连接。该方法将多个不同尺度的卷积核结合起来可以达到更高的准确性和效率,论文

10.CrossConv
将3x3的卷积拆分成1x3和3x1的卷积,同时使用shortcut链接,YoloV5中定义,与使用3x3`的卷积相比,可减少卷积参数。

11.FPN+PAN
YoloV5中使用了Feature Pyramid Network(FPN)与Path Aggregation Network (PAN)网络结构,用于检测不同尺度的目标和特征融合。FPN是FAIR的何凯明团队2016年提交preprint version并发表在CVPR2017上的论文,融入了特征金字塔,提高了目标检测的准确率,尤其体现在小物体的检测上。P2\P3\P4等对应的是C2\C3\C4是特征图大小发生变化的卷积层对应的输出,具体可参考论文Section 3。PAN是香港中文大学发表在CVPR2018上的论文,基于高层的特征具有更多的语义信息,低层特征具有更多的细节信息来做特征融合,取得了更好的语义分割效果。与FPN的Bottom-Up的做法不同,其在FPN的基础上又增加了从顶向下的路径。
Goole Brain2019年提交的论文EfficientDet中提出了BiFPN结构,最终发表在了CVPR2020上,后续可将其应用到YoloV5上实验看一下效果。

欢迎访问个人网络日志知行空间