【论文笔记 - 图像生成 - CVPR2022】Exploring Dual-task Correlation for Pose Guided Person Image Generation

论文地址:https://arxiv.org/pdf/2203.02910.pdf
代码地址:https://github.com/PangzeCheung/Dual-task-Pose-Transformer-Network
姿势引导人物图像生成是将人物图像从源姿势转换为给定目标姿势的任务,作者认为现有的方法大多只针对不适定的源到目标任务,无法捕捉到合理的纹理映射。为了解决这个问题,提出了一种新的双任务姿势变换网络(Dual-task Pose Transformer Network, D P T N DPTN DPTN),引入了源到源的辅助任务,并通过姿势变换模块(Pose Transformer Module, P T M PTM PTM) 充分利用双任务的相关性来提高姿态迁移的性能,
-
S o u r c e - t o - S o u r c e T a s k Source\text{-}to\text{-}Source\ Task Source-to-Source Task,源图像到源图像自重构分支,即生成原图,
-
S o u r c e - t o - T a r g e t T a s k Source\text{-}to\text{-}Target\ Task Source-to-Target Task,源图像到目标图像的转换分支,即生成有原图像纹理和目标姿态的图像
1. 模型结构
如下图所示, D P T N DPTN DPTN 为连体结构,包含 S e l f - r e c o n s t r u c t i o n B r a n c h Self\text{-}reconstruction\ Branch Self-reconstruction Branch 和 T r a n s f o r m a t i o n B r a n c h Transformation\ Branch Transformation Branch 两部分,它们之间共享部分权重,这样源到源任务所学习的知识可以有效地帮助源到目标的学习。此外,作者还使用姿势变换模块 P T M PTM PTM 将两个分支任务连接起来,自适应地探索来自两个任务的特征之间的相关性,在源和目标之间建立所有像素的细粒度映射,同时,促进源纹理传输以增强生成的目标图像的细节。
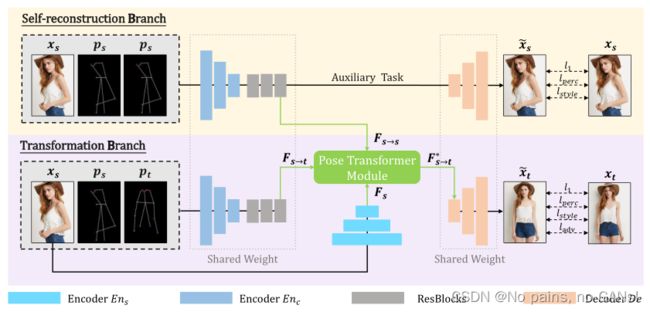
1.1 Siamese Structure for Dual Tasks
作者认为,从源到目标任务的学习不能很好利用源图像的细节,并通过实验验证了,在不修改传统姿态迁移网络的前提下,单纯加入源到源的训练,也就是 s e l f - r e c o n s t u c t i o n t r a i n i n g self\text{-}reconstuction\ training self-reconstuction training,就可以提升模型效果,

基于此,作者将源到源任务添加到模型中,利用学到的知识,来帮助训练过程中源到目标的转换。
网络结构如上图所示,具体来说,分为以下几个步骤,
- 编码器 E n c o d e r Encoder Encoder 提取两种输入的特征,
- 应用 R e s B l o c k s ResBlocks ResBlocks 逐步进行姿态变换,得到与源姿态对齐的 F s → s \boldsymbol{F}_{s \rightarrow s} Fs→s 和与目标姿态对齐的 F s → t \boldsymbol{F}_{s \rightarrow t} Fs→t,
- S e l f - r e c o n s t r u c t i o n B r a n c h Self\text{-}reconstruction\ Branch Self-reconstruction Branch,解码器 D e c o d e r Decoder Decoder 根据 F s → s \boldsymbol{F}_{s \rightarrow s} Fs→s 生成假源图,
- T r a n s f o r m a t i o n B r a n c h Transformation\ Branch Transformation Branch,编码器 D e c o d e r Decoder Decoder 根据改善的 F s → t ∗ \boldsymbol{F}_{s \rightarrow t}^* Fs→t∗ 生成目标图片,
作者认为这样设计有如下优点,
- 共享权重,因此学习的知识可以在两个任务之间轻松地转移,并且引入的 S e l f - r e c o n s t r u c t i o n B r a n c h Self\text{-}reconstruction\ Branch Self-reconstruction Branch 不会大幅增加额外的参数
- 连体结构使双任务的中间输出在特征分布上接近,便于 P T M PTM PTM 探索双任务的相关性。
1.2 Pose Transformer Module
由于基于 C N N CNN CNN 的变换分支(即源到目标)难以处理复杂的空间变形, F s → t \boldsymbol{F}_{s \rightarrow t} Fs→t 往往会丢失许多源外观细节,如下图所示,

因此,作者提出了基于多头注意力机制的 P T M PTM PTM,通过捕获双任务特征之间的对应关系,改善 F s → t \boldsymbol{F}_{s \rightarrow t} Fs→t。具体结构如下所示,

包含两大模块,
-
包含上下文增强模块(Context Augment Block, C A B CAB CAB),整合来自 F s → s \boldsymbol{F}_{s \rightarrow s} Fs→s 的信息,
-
纹理迁移模块(Texture Transfer Block, T T B TTB TTB),根据 F s \boldsymbol{F}_s Fs 中的真实源图像纹理来优化 F s → t \boldsymbol{F}_{s \rightarrow t} Fs→t ,使其捕获双重任务中特征之间的相关性。
1.2.1 Context Augment Block
上图右侧展示了 C A B CAB CAB 的具体结构,首先应用带有残差连接的多头自注意力 (Multi-Head Self-Attention, M H S A MHSA MHSA),自适应地增强输入特征的上下文表示,
F ~ s → s i = I N ( F s → s i − 1 + MHSA ( F s → s i − 1 , F s → s i − 1 , F s → s i − 1 ) ) \tilde{\boldsymbol{F}}_{s \rightarrow s}^{i}=I N\left(\boldsymbol{F}_{s \rightarrow s}^{i-1}+\operatorname{MHSA}\left(\boldsymbol{F}_{s \rightarrow s}^{i-1}, \boldsymbol{F}_{s \rightarrow s}^{i-1}, \boldsymbol{F}_{s \rightarrow s}^{i-1}\right)\right) F~s→si=IN(Fs→si−1+MHSA(Fs→si−1,Fs→si−1,Fs→si−1))
然后使用具有多个全连接层的 M L P MLP MLP 模块来增加网络容量,
F s → s i = I N ( F ~ s → s i + M L P ( F ~ s → s i ) ) \boldsymbol{F}_{s \rightarrow s}^{i}=I N\left(\tilde{\boldsymbol{F}}_{\boldsymbol{s} \rightarrow \boldsymbol{s}}^{i}+M L P\left(\tilde{\boldsymbol{F}}_{\boldsymbol{s} \rightarrow \boldsymbol{s}}^{i}\right)\right) Fs→si=IN(F~s→si+MLP(F~s→si))
经过 N N N 个 C A B CAB CAB 模块后,得到了最终改善的特征 F s → s N \boldsymbol{F}_{s \rightarrow s}^N Fs→sN ,并将其应用于源到目标任务的每个 T T B TTB TTB 中。
1.2.2 Texture Transfer Block
首先应用带有残差连接的 M H S A MHSA MHSA ,使模型注意 F s → t i − 1 \boldsymbol{F}_{s \rightarrow t}^{i-1} Fs→ti−1 的关键信息,
F ~ s → t i = I N ( F s → t i − 1 + M H S A ( F s → t i − 1 , F s → t i − 1 , F s → t i − 1 ) ) \tilde{\boldsymbol{F}}_{s \rightarrow t}^{i}=I N\left(\boldsymbol{F}_{s \rightarrow t}^{i-1}+M H S A\left(\boldsymbol{F}_{s \rightarrow t}^{i-1}, \boldsymbol{F}_{s \rightarrow t}^{i-1}, \boldsymbol{F}_{s \rightarrow t}^{i-1}\right)\right) F~s→ti=IN(Fs→ti−1+MHSA(Fs→ti−1,Fs→ti−1,Fs→ti−1))
然后通过多头交叉注意力 (Multi-Head Cross-Attention, M H C A MHCA MHCA)来建立 F ~ s → t i , F s → s N , F s \tilde{\boldsymbol{F}}_{s \rightarrow t}^{i}, \boldsymbol{F}_{s \rightarrow s}^{N}, \boldsymbol{F}_{s} F~s→ti,Fs→sN,Fs 的关系。具体来说, F ~ s → t i , F s → s N \tilde{\boldsymbol{F}}_{s \rightarrow t}^{i}, \boldsymbol{F}_{s \rightarrow s}^{N} F~s→ti,Fs→sN 分别为 q u e r i e s queries queries 和 k e y s keys keys,用于计算源和目标像素之间的相似性,借助于此, F s \boldsymbol{F}_{s} Fs 在 M H C A MHCA MHCA 中被用作 v a l u e s values values,用真实图像的纹理特征以改善 F ~ s → t i \tilde{\boldsymbol{F}}_{s \rightarrow t}^{i} F~s→ti,
F ^ s → t i = I N ( F ~ s → t i + M H C A ( F ~ s → t i , F s → s N , F s ) ) \hat{\boldsymbol{F}}_{s \rightarrow t}^{i}=I N\left(\tilde{\boldsymbol{F}}_{s \rightarrow t}^{i}+M H C A\left(\tilde{\boldsymbol{F}}_{s \rightarrow t}^{i}, \boldsymbol{F}_{s \rightarrow s}^{N}, \boldsymbol{F}_{s}\right)\right) F^s→ti=IN(F~s→ti+MHCA(F~s→ti,Fs→sN,Fs))
这样, F ~ s → t i \tilde{\boldsymbol{F}}_{s \rightarrow t}^{i} F~s→ti 就具有更真实的源纹理,这将促进 T r a n s f o r m a t i o n B r a n c h Transformation\ Branch Transformation Branch 生成更精细的图像。最后,与 C A B CAB CAB 类似采用了 M L P MLP MLP。
F s → t i = I N ( F ^ s → t i + M L P ( F ^ s → t i ) ) \boldsymbol{F}_{s \rightarrow t}^{i}=I N\left(\hat{\boldsymbol{F}}_{s \rightarrow t}^{i}+M L P\left(\hat{\boldsymbol{F}}_{s \rightarrow t}^{i}\right)\right) Fs→ti=IN(F^s→ti+MLP(F^s→ti))
经过 N N N 个 T T B TTB TTB 模块后,得到了最终的输出特征 F s → t N \boldsymbol{F}_{s \rightarrow t}^N Fs→tN ,并将其应用于 D e c o d e r Decoder Decoder 中生成目标图像 x ~ t \tilde{x}_{t} x~t。
2. 损失函数
d u a l t a s k s dual\ tasks dual tasks 总的损失为,
L = L s → s + L s → t \mathcal{L}=\mathcal{L}_{s \rightarrow s}+\mathcal{L}_{s \rightarrow t} L=Ls→s+Ls→t
L s → s , L s → t \mathcal{L}_{s \rightarrow s}, \mathcal{L}_{s \rightarrow t} Ls→s,Ls→t 分别表示源到源、源到目标的损失,它们都包含了 l 1 l_1 l1 损失 L l 1 \mathcal{L}_{l_1} Ll1,感知损失 L p e r c \mathcal{L}_{perc} Lperc 和风格损失 L s t y l e \mathcal{L}_{style} Lstyle,显然,在源到目标任务中还需要一个对抗损失 L a d v \mathcal{L}_{adv} Ladv 来产生更逼真的纹理。
就可以得到如下的式子,
L s → s = λ l 1 L l 1 s + λ perc L perc s + λ style L style s \mathcal{L}_{s \rightarrow s}=\lambda_{l_{1}} \mathcal{L}_{l_{1}}^{s}+\lambda_{\text {perc }} \mathcal{L}_{\text {perc }}^{s}+\lambda_{\text {style }} \mathcal{L}_{\text {style }}^{s} Ls→s=λl1Ll1s+λperc Lperc s+λstyle Lstyle s
L s → t = λ l 1 L l 1 t + λ perc L perc t + λ style L style t + λ a d v L a d v \mathcal{L}_{s \rightarrow t}=\lambda_{l_{1}} \mathcal{L}_{l_{1}}^{t}+\lambda_{\text {perc }} \mathcal{L}_{\text {perc }}^{t}+\lambda_{\text {style }} \mathcal{L}_{\text {style }}^{t}+\lambda_{a d v} \mathcal{L}_{a d v} Ls→t=λl1Ll1t+λperc Lperc t+λstyle Lstyle t+λadvLadv
在具体一点,
l 1 l_1 l1 损失惩罚生成的图像和真实图像之间的 l 1 l_1 l1 距离,
L l 1 d = ∥ x d − x ~ d ∥ 1 \mathcal{L}_{l_{1}}^{d}=\left\|\boldsymbol{x}_{\boldsymbol{d}}-\tilde{\boldsymbol{x}}_{\boldsymbol{d}}\right\|_{1} Ll1d=∥xd−x~d∥1
感知损失计算图像之间的特征距离, ϕ i \phi_{i} ϕi 表示 V G G VGG VGG 的第 i i i 个特征,
L perc d = ∑ i ∥ ϕ i ( x d ) − ϕ i ( x ~ d ) ∥ 1 \mathcal{L}_{\text {perc }}^{d}=\sum_{i}\left\|\phi_{i}\left(\boldsymbol{x}_{\boldsymbol{d}}\right)-\phi_{i}\left(\tilde{\boldsymbol{x}}_{\boldsymbol{d}}\right)\right\|_{1} Lperc d=∑i∥ϕi(xd)−ϕi(x~d)∥1
风格损失比较了图像之间的风格相似性, Gram j ϕ \operatorname{Gram}_{j}^{\phi} Gramjϕ 是 ϕ j \phi_{j} ϕj 的特征矩阵,
L style d = ∑ j ∥ Gram j ϕ ( x d ) − Gram j ϕ ( x ~ d ) ∥ 1 \mathcal{L}_{\text {style }}^{d}=\sum_{j}\left\|\operatorname{Gram}_{j}^{\phi}\left(\boldsymbol{x}_{\boldsymbol{d}}\right)-\operatorname{Gram}_{j}^{\phi}\left(\tilde{\boldsymbol{x}}_{\boldsymbol{d}}\right)\right\|_{1} Lstyle d=∑j∥∥∥Gramjϕ(xd)−Gramjϕ(x~d)∥∥∥1
对抗损失用于惩罚生成图像 x ~ t \tilde{x}_{t} x~t 和真实图像 x t x_{t} xt 分布的差异,
L a d v = E [ log ( 1 − D ( x ~ t ) ) ] + E [ log D ( x t ) ] \mathcal{L}_{a d v}=\mathbb{E}\left[\log \left(1-D\left(\tilde{\boldsymbol{x}}_{\boldsymbol{t}}\right)\right)\right]+\mathbb{E}\left[\log D\left(\boldsymbol{x}_{\boldsymbol{t}}\right)\right] Ladv=E[log(1−D(x~t))]+E[logD(xt)]